
 Seonglae Cho
Seonglae ChoTodo list
nanogpt transformer 추가
pip에 배포해보기 모델 불러오기 가능하게? autoModel
stream 안되는 문제
다음주
DDP with nanogpt
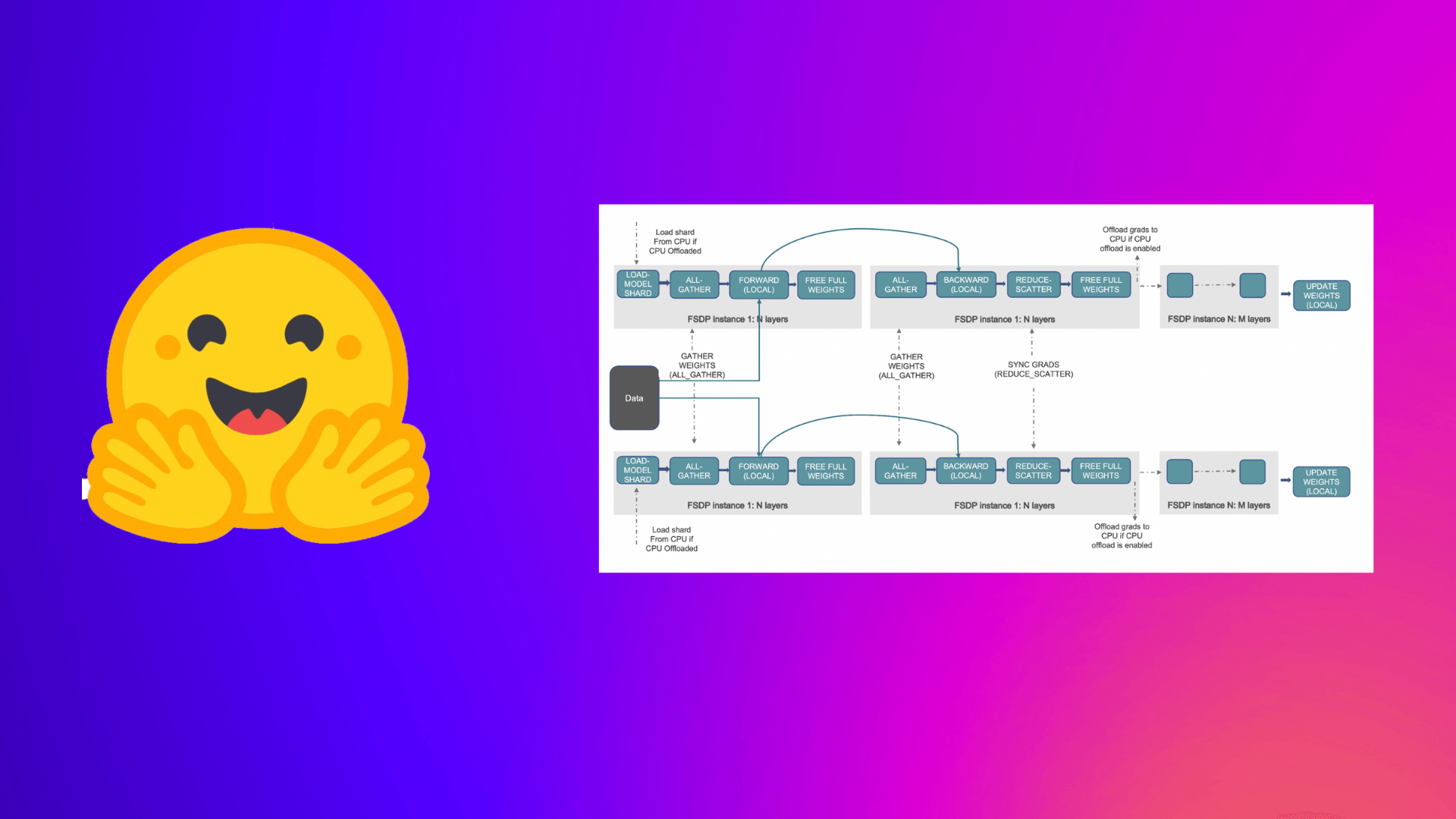
FSDP with accelerate
mistral 훈련
small nano special token 추가해서 chat data 학습?
DPO training
korean llm leaderboard 등록하거나 여러 benchmark 돌리기
nanogpt 에 groupgpt 등 전부 공부한 뒤 테크닉 추가해서 hanGPT model_type 최종목표
tinybencthmark evaluate에 추가해서 evaluate하기

RTX3090 4개를 multi-node 분산학습을 자유자재로 하는 남자 어떤데
accelerate launch \ --config_file configs/fsdp_config.yaml \ --main_process_ip 10.244.241.60 \ --main_process_port 1234 \ --machine_rank 0 \ --num_processes 2 \ --num_machines 2 \ train.py \ --seed 100 \ --model_name "seonglae/yokhal-md" \ --dataset_name "smangrul/code-chat-assistant-v1" \ --chat_template_format "none" \ --add_special_tokens False \ --append_concat_token False \ --splits "train,test" \ --max_seq_len 2048 \ --max_steps 500 \ --logging_steps 25 \ --log_level "info" \ --eval_steps 100 \ --save_steps 250 \ --logging_strategy "steps" \ --evaluation_strategy "steps" \ --save_strategy "steps" \ --push_to_hub \ --hub_private_repo True \ --hub_strategy "every_save" \ --bf16 True \ --packing True \ --learning_rate 5e-5 \ --lr_scheduler_type "cosine" \ --weight_decay 0.01 \ --warmup_ratio 0.03 \ --max_grad_norm 1.0 \ --output_dir "output" \ --per_device_train_batch_size 1 \ --per_device_eval_batch_size 1 \ --gradient_accumulation_steps 1 \ --gradient_checkpointing True \ --use_reentrant False \ --dataset_text_field "content" \ --use_flash_attn True \ --ddp_timeout 5400 \ --optim paged_adamw_32bit
accelerate launch \ --config_file configs/fsdp_config.yaml \ --main_process_ip 10.244.241.60 \ --main_process_port 1234 \ --machine_rank 1 \ --num_processes 2 \ --num_machines 2 \ train.py \ --seed 100 \ --model_name "seonglae/yokhal-md" \ --dataset_name "smangrul/code-chat-assistant-v1" \ --chat_template_format "none" \ --add_special_tokens False \ --append_concat_token False \ --splits "train,test" \ --max_seq_len 2048 \ --max_steps 500 \ --logging_steps 25 \ --log_level "info" \ --eval_steps 100 \ --save_steps 250 \ --logging_strategy "steps" \ --evaluation_strategy "steps" \ --save_strategy "steps" \ --push_to_hub \ --hub_private_repo True \ --hub_strategy "every_save" \ --bf16 True \ --packing True \ --learning_rate 5e-5 \ --lr_scheduler_type "cosine" \ --weight_decay 0.01 \ --warmup_ratio 0.03 \ --max_grad_norm 1.0 \ --output_dir "output" \ --per_device_train_batch_size 1 \ --per_device_eval_batch_size 1 \ --gradient_accumulation_steps 1 \ --gradient_checkpointing True \ --use_reentrant False \ --dataset_text_field "content" \ --use_flash_attn True \ --ddp_timeout 5400 \ --optim paged_adamw_32bit
time accelerate launch fsdp.py \ --model_name_or_path gpt2-large \ --dataset_name wikitext \ --dataset_config_name wikitext-2-raw-v1 \ --per_device_train_batch_size $BS \ --per_device_eval_batch_size $BS \ --num_train_epochs 1 \ --block_size 12
Best practice
Fine-tuning Llama 2 70B using PyTorch FSDP
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
https://huggingface.co/blog/ram-efficient-pytorch-fsdp

Accelerate Large Model Training using PyTorch Fully Sharded Data Parallel
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
https://huggingface.co/blog/pytorch-fsdp
compute_environment: LOCAL_MACHINE debug: true distributed_type: FSDP downcast_bf16: 'no' dynamo_config: dynamo_backend: TENSORRT dynamo_mode: default dynamo_use_dynamic: true dynamo_use_fullgraph: true fsdp_config: fsdp_auto_wrap_policy: SIZE_BASED_WRAP fsdp_backward_prefetch: BACKWARD_PRE fsdp_cpu_ram_efficient_loading: true fsdp_forward_prefetch: false fsdp_min_num_params: 100000000 fsdp_offload_params: true fsdp_sharding_strategy: FULL_SHARD fsdp_state_dict_type: SHARDED_STATE_DICT fsdp_sync_module_states: true fsdp_use_orig_params: false machine_rank: 1 main_process_ip: 10.244.241.38 main_process_port: 8888 main_training_function: main mixed_precision: bf16 num_machines: 2 num_processes: 2 rdzv_backend: static same_network: true tpu_env: [] tpu_use_cluster: false tpu_use_sudo: false use_cpu: false
compute_environment: LOCAL_MACHINE debug: true distributed_type: FSDP downcast_bf16: 'no' fsdp_config: fsdp_auto_wrap_policy: SIZE_BASED_WRAP fsdp_backward_prefetch: BACKWARD_PRE fsdp_cpu_ram_efficient_loading: true fsdp_forward_prefetch: false fsdp_offload_params: true fsdp_sharding_strategy: FULL_SHARD fsdp_state_dict_type: SHARDED_STATE_DICT fsdp_sync_module_states: true fsdp_use_orig_params: false machine_rank: 1 main_process_ip: 10.244.241.38 main_process_port: 8888 main_training_function: main mixed_precision: bf16 num_machines: 2 num_processes: 2 rdzv_backend: static same_network: true tpu_env: [] tpu_use_cluster: false tpu_use_sudo: false use_cpu: false
compute_environment: LOCAL_MACHINE deepspeed_config: {} distributed_type: FSDP fsdp_config: min_num_params: 2000 offload_params: false sharding_strategy: 1 machine_rank: 0 main_process_ip: 10.244.241.60 main_process_port: 1234 main_training_function: main mixed_precision: 'no' num_machines: 1 num_processes: 2 use_cpu: false
compute_environment: LOCAL_MACHINE debug: false distributed_type: FSDP downcast_bf16: 'no' fsdp_config: fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP fsdp_backward_prefetch: BACKWARD_PRE fsdp_cpu_ram_efficient_loading: true fsdp_forward_prefetch: false fsdp_offload_params: false fsdp_sharding_strategy: FULL_SHARD fsdp_state_dict_type: SHARDED_STATE_DICT fsdp_sync_module_states: true fsdp_use_orig_params: true machine_rank: 1 main_training_function: main mixed_precision: bf16 num_machines: 2 num_processes: 2 main_process_ip: 10.244.241.60 main_process_port: 1234 rdzv_backend: static same_network: true tpu_env: [] tpu_use_cluster: false tpu_use_sudo: false use_cpu: false
Using RTX 3090 or 4000 series which doesn't support faster communication speedups. Ensuring P2P and IB communications are disabled. Flash Attention 2.0 only supports torch.float16 and torch.bfloat16 dtypes, but the current dype in GemmaForCausalLM is torch.float32. You should run training or inference using Automatic Mixed-Precision via the `with torch.autocast(device_type='torch_device'):` decorator, or load the model with the `torch_dtype` argument. Example: `model = AutoModel.from_pretrained("openai/whisper-tiny", attn_implementation="flash_attention_2", torch_dtype=torch.float16)` You are attempting to use Flash Attention 2.0 with a model not initialized on GPU. Make sure to move the model to GPU after initializing it on CPU with `model.to('cuda')`. Flash Attention 2.0 only supports torch.float16 and torch.bfloat16 dtypes, but the current dype in GemmaModel is torch.float32. You should run training or inference using Automatic Mixed-Precision via the `with torch.autocast(device_type='torch_device'):` decorator, or load the model with the `torch_dtype` argument. Example: `model = AutoModel.from_pretrained("openai/whisper-tiny", attn_implementation="flash_attention_2", torch_dtype=torch.float16)` Loading checkpoint shards: 100%|█████████████████| 2/2 [00:03<00:00, 1.98s/it] Size of the train set: 10876. Size of the validation set: 818 A sample of train dataset: {'content': '<|system|> You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.\n\nIf a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don’t know the answer to a question, please don’t share false information. <|endoftext|> <|prompter|> Are we alone in the universe? <|endoftext|> <|assistant|> Humanity has yet to find evidence for life outside planet Earth.\n\nThe current search for extraterrestrial life is largely focused on finding planets that are situated in an "habitable zone". Roughly put, a planet is in a habitable zone if its distance from nearby stars allows for liquid water to persist on its surface.\nSo far, a few such planets have been found, but none yet with liquid water on its surface. <|endoftext|>'} NCCL version 2.18.6+cuda12.1 /usr/local/lib/python3.10/dist-packages/trl/trainer/sft_trainer.py:294: UserWarning: You passed a tokenizer with `padding_side` not equal to `right` to the SFTTrainer. This might lead to some unexpected behaviour due to overflow issues when training a model in half-precision. You might consider adding `tokenizer.padding_side = 'right'` to your code. warnings.warn( Detected kernel version 5.4.0, which is below the recommended minimum of 5.5.0; this can cause the process to hang. It is recommended to upgrade the kernel to the minimum version or higher. max_steps is given, it will override any value given in num_train_epochs Using auto half precision backend /usr/local/lib/python3.10/dist-packages/trl/trainer/sft_trainer.py:318: UserWarning: You passed `packing=True` to the SFTTrainer, and you are training your model with `max_steps` strategy. The dataset will be iterated until the `max_steps` are reached. warnings.warn( GemmaForCausalLM( (model): GemmaModel( (embed_tokens): Embedding(256000, 2048, padding_idx=0) (layers): ModuleList( (0-17): 18 x GemmaDecoderLayer( (self_attn): GemmaFlashAttention2( (q_proj): Linear(in_features=2048, out_features=2048, bias=False) (k_proj): Linear(in_features=2048, out_features=256, bias=False) (v_proj): Linear(in_features=2048, out_features=256, bias=False) (o_proj): Linear(in_features=2048, out_features=2048, bias=False) (rotary_emb): GemmaRotaryEmbedding() ) (mlp): GemmaMLP( (gate_proj): Linear(in_features=2048, out_features=16384, bias=False) (up_proj): Linear(in_features=2048, out_features=16384, bias=False) (down_proj): Linear(in_features=16384, out_features=2048, bias=False) (act_fn): GELUActivation() ) (input_layernorm): GemmaRMSNorm() (post_attention_layernorm): GemmaRMSNorm() ) ) (norm): GemmaRMSNorm() ) (lm_head): Linear(in_features=2048, out_features=256000, bias=False) ) [E ProcessGroupNCCL.cpp:475] [Rank 0] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=2, OpType=BROADCAST, NumelIn=76546048, NumelOut=76546048, Timeout(ms)=5400000) ran for 5400986 milliseconds before timing out. [E ProcessGroupNCCL.cpp:489] Some NCCL operations have failed or timed out. Due to the asynchronous nature of CUDA kernels, subsequent GPU operations might run on corrupted/incomplete data. [E ProcessGroupNCCL.cpp:495] To avoid data inconsistency, we are taking the entire process down. [E ProcessGroupNCCL.cpp:916] [Rank 0] NCCL watchdog thread terminated with exception: [Rank 0] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=2, OpType=BROADCAST, NumelIn=76546048, NumelOut=76546048, Timeout(ms)=5400000) ran for 5400986 milliseconds before timing out. terminate called after throwing an instance of 'std::runtime_error' what(): [Rank 0] NCCL watchdog thread terminated with exception: [Rank 0] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=2, OpType=BROADCAST, NumelIn=76546048, NumelOut=76546048, Timeout(ms)=5400000) ran for 5400986 milliseconds before timing out. [2024-03-17 14:01:17,953] torch.distributed.elastic.multiprocessing.api: [ERROR] failed (exitcode: -6) local_rank: 0 (pid: 1292406) of binary: /usr/bin/python Traceback (most recent call last): File "/usr/local/bin/accelerate", line 8, in <module> sys.exit(main()) File "/usr/local/lib/python3.10/dist-packages/accelerate/commands/accelerate_cli.py", line 47, in main args.func(args) File "/usr/local/lib/python3.10/dist-packages/accelerate/commands/launch.py", line 1010, in launch_command multi_gpu_launcher(args) File "/usr/local/lib/python3.10/dist-packages/accelerate/commands/launch.py", line 672, in multi_gpu_launcher distrib_run.run(args) File "/usr/local/lib/python3.10/dist-packages/torch/distributed/run.py", line 797, in run elastic_launch( File "/usr/local/lib/python3.10/dist-packages/torch/distributed/launcher/api.py", line 134, in __call__ return launch_agent(self._config, self._entrypoint, list(args)) File "/usr/local/lib/python3.10/dist-packages/torch/distributed/launcher/api.py", line 264, in launch_agent raise ChildFailedError( torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
Traceback (most recent call last): File "/root/dhs/chat_assistant/sft/training/train.py", line 196, in <module> main(model_args, data_args, training_args) File "/root/dhs/chat_assistant/sft/training/train.py", line 176, in main trainer.train(resume_from_checkpoint=checkpoint) File "/usr/local/lib/python3.10/dist-packages/trl/trainer/sft_trainer.py", line 331, in train output = super().train(*args, **kwargs) File "/usr/local/lib/python3.10/dist-packages/transformers/trainer.py", line 1615, in train return inner_training_loop( File "/usr/local/lib/python3.10/dist-packages/transformers/trainer.py", line 1766, in _inner_training_loop self.model = self.accelerator.prepare(self.model) File "/usr/local/lib/python3.10/dist-packages/accelerate/accelerator.py", line 1263, in prepare result = tuple( File "/usr/local/lib/python3.10/dist-packages/accelerate/accelerator.py", line 1264, in <genexpr> self._prepare_one(obj, first_pass=True, device_placement=d) for obj, d in zip(args, device_placement) File "/usr/local/lib/python3.10/dist-packages/accelerate/accelerator.py", line 1140, in _prepare_one return self.prepare_model(obj, device_placement=device_placement) File "/usr/local/lib/python3.10/dist-packages/accelerate/accelerator.py", line 1422, in prepare_model model = FSDP(model, **kwargs) File "/usr/local/lib/python3.10/dist-packages/torch/distributed/fsdp/fully_sharded_data_parallel.py", line 463, in __init__ _auto_wrap( File "/usr/local/lib/python3.10/dist-packages/torch/distributed/fsdp/_wrap_utils.py", line 101, in _auto_wrap _recursive_wrap(**recursive_wrap_kwargs, **root_kwargs) # type: ignore[arg-type] File "/usr/local/lib/python3.10/dist-packages/torch/distributed/fsdp/wrap.py", line 537, in _recursive_wrap wrapped_child, num_wrapped_params = _recursive_wrap( File "/usr/local/lib/python3.10/dist-packages/torch/distributed/fsdp/wrap.py", line 537, in _recursive_wrap wrapped_child, num_wrapped_params = _recursive_wrap( File "/usr/local/lib/python3.10/dist-packages/torch/distributed/fsdp/wrap.py", line 537, in _recursive_wrap wrapped_child, num_wrapped_params = _recursive_wrap( File "/usr/local/lib/python3.10/dist-packages/torch/distributed/fsdp/wrap.py", line 555, in _recursive_wrap return _wrap(module, wrapper_cls, **kwargs), nonwrapped_numel File "/usr/local/lib/python3.10/dist-packages/torch/distributed/fsdp/wrap.py", line 484, in _wrap return wrapper_cls(module, **kwargs) File "/usr/local/lib/python3.10/dist-packages/torch/distributed/fsdp/fully_sharded_data_parallel.py", line 487, in __init__ _init_param_handle_from_module( File "/usr/local/lib/python3.10/dist-packages/torch/distributed/fsdp/_init_utils.py", line 516, in _init_param_handle_from_module _sync_module_params_and_buffers( File "/usr/local/lib/python3.10/dist-packages/torch/distributed/fsdp/_init_utils.py", line 982, in _sync_module_params_and_buffers _sync_params_and_buffers( File "/usr/local/lib/python3.10/dist-packages/torch/distributed/utils.py", line 306, in _sync_params_and_buffers dist._broadcast_coalesced( RuntimeError: [1] is setting up NCCL communicator and retrieving ncclUniqueId from [0] via c10d key-value store by key '1', but store->get('1') got error: Socket Timeout Exception raised from doWait at ../torch/csrc/distributed/c10d/TCPStore.cpp:445 (most recent call first): frame #0: c10::Error::Error(c10::SourceLocation, std::string) + 0x57 (0x7f9a8c084617 in /usr/local/lib/python3.10/dist-packages/torch/lib/libc10.so) frame #1: c10::detail::torchCheckFail(char const*, char const*, unsigned int, char const*) + 0x68 (0x7f9a8c03fa56 in /usr/local/lib/python3.10/dist-packages/torch/lib/libc10.so) frame #2: c10d::TCPStore::doWait(c10::ArrayRef<std::string>, std::chrono::duration<long, std::ratio<1l, 1000l> >) + 0x32c (0x7f9a7692300c in /usr/local/lib/python3.10/dist-packages/torch/lib/libtorch_cpu.so) frame #3: c10d::TCPStore::doGet(std::string const&) + 0x32 (0x7f9a76924192 in /usr/local/lib/python3.10/dist-packages/torch/lib/libtorch_cpu.so) frame #4: c10d::TCPStore::get(std::string const&) + 0x55 (0x7f9a769245b5 in /usr/local/lib/python3.10/dist-packages/torch/lib/libtorch_cpu.so) frame #5: c10d::PrefixStore::get(std::string const&) + 0x31 (0x7f9a768dbe01 in /usr/local/lib/python3.10/dist-packages/torch/lib/libtorch_cpu.so) frame #6: c10d::PrefixStore::get(std::string const&) + 0x31 (0x7f9a768dbe01 in /usr/local/lib/python3.10/dist-packages/torch/lib/libtorch_cpu.so) frame #7: c10d::PrefixStore::get(std::string const&) + 0x31 (0x7f9a768dbe01 in /usr/local/lib/python3.10/dist-packages/torch/lib/libtorch_cpu.so) frame #8: c10d::PrefixStore::get(std::string const&) + 0x31 (0x7f9a768dbe01 in /usr/local/lib/python3.10/dist-packages/torch/lib/libtorch_cpu.so) frame #9: c10d::ProcessGroupNCCL::broadcastUniqueNCCLID(ncclUniqueId*, bool, std::string const&, int) + 0xb2 (0x7f9a2ad00312 in /usr/local/lib/python3.10/dist-packages/torch/lib/libtorch_cuda.so) frame #10: c10d::ProcessGroupNCCL::getNCCLComm(std::string const&, std::vector<c10::Device, std::allocator<c10::Device> > const&, c10d::OpType, int, bool) + 0x203 (0x7f9a2ad05ce3 in /usr/local/lib/python3.10/dist-packages/torch/lib/libtorch_cuda.so) frame #11: c10d::ProcessGroupNCCL::broadcast(std::vector<at::Tensor, std::allocator<at::Tensor> >&, c10d::BroadcastOptions const&) + 0x41c (0x7f9a2ad18d0c in /usr/local/lib/python3.10/dist-packages/torch/lib/libtorch_cuda.so) frame #12: <unknown function> + 0x567b800 (0x7f9a768d0800 in /usr/local/lib/python3.10/dist-packages/torch/lib/libtorch_cpu.so) frame #13: <unknown function> + 0x5684232 (0x7f9a768d9232 in /usr/local/lib/python3.10/dist-packages/torch/lib/libtorch_cpu.so) frame #14: <unknown function> + 0x56842d9 (0x7f9a768d92d9 in /usr/local/lib/python3.10/dist-packages/torch/lib/libtorch_cpu.so) frame #15: <unknown function> + 0x4cb046b (0x7f9a75f0546b in /usr/local/lib/python3.10/dist-packages/torch/lib/libtorch_cpu.so) frame #16: <unknown function> + 0x4cae44c (0x7f9a75f0344c in /usr/local/lib/python3.10/dist-packages/torch/lib/libtorch_cpu.so) frame #17: <unknown function> + 0x1a039d8 (0x7f9a72c589d8 in /usr/local/lib/python3.10/dist-packages/torch/lib/libtorch_cpu.so) frame #18: <unknown function> + 0x568ad02 (0x7f9a768dfd02 in /usr/local/lib/python3.10/dist-packages/torch/lib/libtorch_cpu.so) frame #19: <unknown function> + 0x569aea7 (0x7f9a768efea7 in /usr/local/lib/python3.10/dist-packages/torch/lib/libtorch_cpu.so) frame #20: c10d::broadcast_coalesced(c10::intrusive_ptr<c10d::ProcessGroup, c10::detail::intrusive_target_default_null_type<c10d::ProcessGroup> > const&, c10::ArrayRef<at::Tensor>, unsigned long, int) + 0x7e2 (0x7f9a7692c5e2 in /usr/local/lib/python3.10/dist-packages/torch/lib/libtorch_cpu.so) frame #21: <unknown function> + 0xc10a10 (0x7f9a8948ea10 in /usr/local/lib/python3.10/dist-packages/torch/lib/libtorch_python.so) frame #22: <unknown function> + 0x3f7304 (0x7f9a88c75304 in /usr/local/lib/python3.10/dist-packages/torch/lib/libtorch_python.so) frame #23: <unknown function> + 0x15c99e (0x55624cdd799e in /usr/bin/python) frame #24: _PyObject_MakeTpCall + 0x25b (0x55624cdce4ab in /usr/bin/python) frame #25: _PyEval_EvalFrameDefault + 0x6db6 (0x55624cdc6e66 in /usr/bin/python) frame #26: _PyFunction_Vectorcall + 0x7c (0x55624cdd81ec in /usr/bin/python) frame #27: _PyEval_EvalFrameDefault + 0x1a2f (0x55624cdc1adf in /usr/bin/python) frame #28: _PyFunction_Vectorcall + 0x7c (0x55624cdd81ec in /usr/bin/python) frame #29: _PyEval_EvalFrameDefault + 0x6d5 (0x55624cdc0785 in /usr/bin/python) frame #30: _PyFunction_Vectorcall + 0x7c (0x55624cdd81ec in /usr/bin/python) frame #31: _PyEval_EvalFrameDefault + 0x6d5 (0x55624cdc0785 in /usr/bin/python) frame #32: _PyFunction_Vectorcall + 0x7c (0x55624cdd81ec in /usr/bin/python) frame #33: _PyObject_FastCallDictTstate + 0x16d (0x55624cdcd6dd in /usr/bin/python) frame #34: <unknown function> + 0x166e94 (0x55624cde1e94 in /usr/bin/python) frame #35: <unknown function> + 0x15385b (0x55624cdce85b in /usr/bin/python) frame #36: PyObject_Call + 0xbb (0x55624cde687b in /usr/bin/python) frame #37: _PyEval_EvalFrameDefault + 0x2a40 (0x55624cdc2af0 in /usr/bin/python) frame #38: _PyFunction_Vectorcall + 0x7c (0x55624cdd81ec in /usr/bin/python) frame #39: PyObject_Call + 0x122 (0x55624cde68e2 in /usr/bin/python) frame #40: _PyEval_EvalFrameDefault + 0x2a40 (0x55624cdc2af0 in /usr/bin/python) frame #41: _PyFunction_Vectorcall + 0x7c (0x55624cdd81ec in /usr/bin/python) frame #42: PyObject_Call + 0x122 (0x55624cde68e2 in /usr/bin/python) frame #43: _PyEval_EvalFrameDefault + 0x2a40 (0x55624cdc2af0 in /usr/bin/python) frame #44: _PyFunction_Vectorcall + 0x7c (0x55624cdd81ec in /usr/bin/python) frame #45: PyObject_Call + 0x122 (0x55624cde68e2 in /usr/bin/python) frame #46: _PyEval_EvalFrameDefault + 0x2a40 (0x55624cdc2af0 in /usr/bin/python) frame #47: _PyFunction_Vectorcall + 0x7c (0x55624cdd81ec in /usr/bin/python) frame #48: PyObject_Call + 0x122 (0x55624cde68e2 in /usr/bin/python) frame #49: _PyEval_EvalFrameDefault + 0x2a40 (0x55624cdc2af0 in /usr/bin/python) frame #50: _PyFunction_Vectorcall + 0x7c (0x55624cdd81ec in /usr/bin/python) frame #51: PyObject_Call + 0x122 (0x55624cde68e2 in /usr/bin/python) frame #52: _PyEval_EvalFrameDefault + 0x2a40 (0x55624cdc2af0 in /usr/bin/python) frame #53: _PyFunction_Vectorcall + 0x7c (0x55624cdd81ec in /usr/bin/python) frame #54: _PyEval_EvalFrameDefault + 0x6d5 (0x55624cdc0785 in /usr/bin/python) frame #55: _PyFunction_Vectorcall + 0x7c (0x55624cdd81ec in /usr/bin/python) frame #56: _PyObject_FastCallDictTstate + 0x16d (0x55624cdcd6dd in /usr/bin/python) frame #57: <unknown function> + 0x166e94 (0x55624cde1e94 in /usr/bin/python) frame #58: <unknown function> + 0x15385b (0x55624cdce85b in /usr/bin/python) frame #59: PyObject_Call + 0xbb (0x55624cde687b in /usr/bin/python) frame #60: _PyEval_EvalFrameDefault + 0x2a40 (0x55624cdc2af0 in /usr/bin/python) frame #61: <unknown function> + 0x16ac31 (0x55624cde5c31 in /usr/bin/python) frame #62: _PyEval_EvalFrameDefault + 0x1a2f (0x55624cdc1adf in /usr/bin/python) frame #63: <unknown function> + 0x16ac31 (0x55624cde5c31 in /usr/bin/python) . This may indicate a possible application crash on rank 0 or a network set up issue. [2024-03-17 14:01:17,768] torch.distributed.elastic.multiprocessing.api: [ERROR] failed (exitcode: 1) local_rank: 0 (pid: 1199676) of binary: /usr/bin/python Traceback (most recent call last): File "/usr/local/bin/accelerate", line 8, in <module> sys.exit(main()) File "/usr/local/lib/python3.10/dist-packages/accelerate/commands/accelerate_cli.py", line 46, in main args.func(args) File "/usr/local/lib/python3.10/dist-packages/accelerate/commands/launch.py", line 1044, in launch_command multi_gpu_launcher(args) File "/usr/local/lib/python3.10/dist-packages/accelerate/commands/launch.py", line 702, in multi_gpu_launcher distrib_run.run(args) File "/usr/local/lib/python3.10/dist-packages/torch/distributed/run.py", line 797, in run elastic_launch( File "/usr/local/lib/python3.10/dist-packages/torch/distributed/launcher/api.py", line 134, in __call__ return launch_agent(self._config, self._entrypoint, list(args)) File "/usr/local/lib/python3.10/dist-packages/torch/distributed/launcher/api.py", line 264, in launch_agent raise ChildFailedError( torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
fsdp.py#!/usr/bin/env python # coding=utf-8 # Copyright 2021 The HuggingFace Inc. team. All rights reserved. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. """ Fine-tuning the library models for causal language modeling (GPT, GPT-2, CTRL, ...) on a text file or a dataset without using HuggingFace Trainer. Here is the full list of checkpoints on the hub that can be fine-tuned by this script: https://huggingface.co/models?filter=text-generation """ # You can also adapt this script on your own causal language modeling task. Pointers for this are left as comments. import argparse import json import logging import math import os import random from itertools import chain from pathlib import Path import datasets import torch from datasets import load_dataset from torch.utils.data import DataLoader from tqdm.auto import tqdm import transformers from accelerate import Accelerator, DistributedType from accelerate.utils import set_seed from huggingface_hub import Repository from transformers import ( CONFIG_MAPPING, MODEL_MAPPING, AdamW, AutoConfig, AutoModelForCausalLM, AutoTokenizer, SchedulerType, default_data_collator, get_scheduler, ) from transformers.utils import get_full_repo_name from transformers.utils.versions import require_version logger = logging.getLogger(__name__) require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt") MODEL_CONFIG_CLASSES = list(MODEL_MAPPING.keys()) MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES) def parse_args(): parser = argparse.ArgumentParser(description="Finetune a transformers model on a causal language modeling task") parser.add_argument( "--dataset_name", type=str, default=None, help="The name of the dataset to use (via the datasets library).", ) parser.add_argument( "--dataset_config_name", type=str, default=None, help="The configuration name of the dataset to use (via the datasets library).", ) parser.add_argument( "--train_file", type=str, default=None, help="A csv or a json file containing the training data." ) parser.add_argument( "--validation_file", type=str, default=None, help="A csv or a json file containing the validation data." ) parser.add_argument( "--validation_split_percentage", default=5, help="The percentage of the train set used as validation set in case there's no validation split", ) parser.add_argument( "--model_name_or_path", type=str, help="Path to pretrained model or model identifier from huggingface.co/models.", required=True, ) parser.add_argument( "--config_name", type=str, default=None, help="Pretrained config name or path if not the same as model_name", ) parser.add_argument( "--tokenizer_name", type=str, default=None, help="Pretrained tokenizer name or path if not the same as model_name", ) parser.add_argument( "--use_slow_tokenizer", action="store_true", help="If passed, will use a slow tokenizer (not backed by the 🤗 Tokenizers library).", ) parser.add_argument( "--per_device_train_batch_size", type=int, default=8, help="Batch size (per device) for the training dataloader.", ) parser.add_argument( "--per_device_eval_batch_size", type=int, default=8, help="Batch size (per device) for the evaluation dataloader.", ) parser.add_argument( "--learning_rate", type=float, default=5e-5, help="Initial learning rate (after the potential warmup period) to use.", ) parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay to use.") parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.") parser.add_argument( "--max_train_steps", type=int, default=None, help="Total number of training steps to perform. If provided, overrides num_train_epochs.", ) parser.add_argument( "--gradient_accumulation_steps", type=int, default=1, help="Number of updates steps to accumulate before performing a backward/update pass.", ) parser.add_argument( "--lr_scheduler_type", type=SchedulerType, default="linear", help="The scheduler type to use.", choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"], ) parser.add_argument( "--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler." ) parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.") parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.") parser.add_argument( "--model_type", type=str, default=None, help="Model type to use if training from scratch.", choices=MODEL_TYPES, ) parser.add_argument( "--block_size", type=int, default=None, help="Optional input sequence length after tokenization. The training dataset will be truncated in block of this size for training. Default to the model max input length for single sentence inputs (take into account special tokens).", ) parser.add_argument( "--preprocessing_num_workers", type=int, default=None, help="The number of processes to use for the preprocessing.", ) parser.add_argument( "--overwrite_cache", type=bool, default=False, help="Overwrite the cached training and evaluation sets" ) parser.add_argument( "--no_keep_linebreaks", action="store_true", help="Do not keep line breaks when using TXT files." ) parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.") parser.add_argument( "--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`." ) parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.") parser.add_argument( "--checkpointing_steps", type=str, default=None, help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.", ) parser.add_argument( "--resume_from_checkpoint", type=str, default=None, help="If the training should continue from a checkpoint folder.", ) parser.add_argument( "--with_tracking", action="store_true", help="Whether to load in all available experiment trackers from the environment and use them for logging.", ) parser.add_argument( "--n_train", type=int, default=2000, help="Number of train samples.", ) parser.add_argument( "--n_val", type=int, default=500, help="Number of validation samples.", ) args = parser.parse_args() # Sanity checks if args.dataset_name is None and args.train_file is None and args.validation_file is None: raise ValueError("Need either a dataset name or a training/validation file.") else: if args.train_file is not None: extension = args.train_file.split(".")[-1] assert extension in ["csv", "json", "txt"], "`train_file` should be a csv, json or txt file." if args.validation_file is not None: extension = args.validation_file.split(".")[-1] assert extension in ["csv", "json", "txt"], "`validation_file` should be a csv, json or txt file." if args.push_to_hub: assert args.output_dir is not None, "Need an `output_dir` to create a repo when `--push_to_hub` is passed." return args def main(): args = parse_args() # Initialize the accelerator. We will let the accelerator handle device placement for us in this example. # If we're using tracking, we also need to initialize it here and it will pick up all supported trackers in the environment accelerator = Accelerator(log_with="all", logging_dir=args.output_dir) if args.with_tracking else Accelerator() # Make one log on every process with the configuration for debugging. logging.basicConfig( format="%(asctime)s - %(levelname)s - %(name)s - %(message)s", datefmt="%m/%d/%Y %H:%M:%S", level=logging.INFO, ) logger.info(accelerator.state) # Setup logging, we only want one process per machine to log things on the screen. # accelerator.is_local_main_process is only True for one process per machine. logger.setLevel(logging.INFO if accelerator.is_local_main_process else logging.ERROR) if accelerator.is_local_main_process: datasets.utils.logging.set_verbosity_warning() transformers.utils.logging.set_verbosity_info() else: datasets.utils.logging.set_verbosity_error() transformers.utils.logging.set_verbosity_error() # If passed along, set the training seed now. if args.seed is not None: set_seed(args.seed) # Handle the repository creation if accelerator.is_main_process: if args.push_to_hub: if args.hub_model_id is None: repo_name = get_full_repo_name(Path(args.output_dir).name, token=args.hub_token) else: repo_name = args.hub_model_id repo = Repository(args.output_dir, clone_from=repo_name) with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore: if "step_*" not in gitignore: gitignore.write("step_*\n") if "epoch_*" not in gitignore: gitignore.write("epoch_*\n") elif args.output_dir is not None: os.makedirs(args.output_dir, exist_ok=True) accelerator.wait_for_everyone() # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below) # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/ # (the dataset will be downloaded automatically from the datasets Hub). # # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called # 'text' is found. You can easily tweak this behavior (see below). # # In distributed training, the load_dataset function guarantee that only one local process can concurrently # download the dataset. if args.dataset_name is not None: # Downloading and loading a dataset from the hub. raw_datasets = datasets.DatasetDict( { "train": datasets.Dataset.from_dict( load_dataset(args.dataset_name, args.dataset_config_name)["train"][: args.n_train + args.n_val] ) } ) if "validation" not in raw_datasets.keys(): raw_datasets["validation"] = load_dataset( args.dataset_name, args.dataset_config_name, split=f"train[:{args.validation_split_percentage}%]", ) raw_datasets["train"] = load_dataset( args.dataset_name, args.dataset_config_name, split=f"train[{args.validation_split_percentage}%:]", ) else: data_files = {} dataset_args = {} if args.train_file is not None: data_files["train"] = args.train_file if args.validation_file is not None: data_files["validation"] = args.validation_file extension = args.train_file.split(".")[-1] if extension == "txt": extension = "text" dataset_args["keep_linebreaks"] = not args.no_keep_linebreaks raw_datasets = load_dataset(extension, data_files=data_files, **dataset_args) # If no validation data is there, validation_split_percentage will be used to divide the dataset. if "validation" not in raw_datasets.keys(): raw_datasets["validation"] = load_dataset( extension, data_files=data_files, split=f"train[:{args.validation_split_percentage}%]", **dataset_args, ) raw_datasets["train"] = load_dataset( extension, data_files=data_files, split=f"train[{args.validation_split_percentage}%:]", **dataset_args, ) # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at # https://huggingface.co/docs/datasets/loading_datasets.html. # Load pretrained model and tokenizer # # In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently # download model & vocab. if args.config_name: config = AutoConfig.from_pretrained(args.config_name) elif args.model_name_or_path: config = AutoConfig.from_pretrained(args.model_name_or_path) else: config = CONFIG_MAPPING[args.model_type]() logger.warning("You are instantiating a new config instance from scratch.") if args.tokenizer_name: tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_name, use_fast=not args.use_slow_tokenizer) elif args.model_name_or_path: tokenizer = AutoTokenizer.from_pretrained(args.model_name_or_path, use_fast=not args.use_slow_tokenizer) else: raise ValueError( "You are instantiating a new tokenizer from scratch. This is not supported by this script." "You can do it from another script, save it, and load it from here, using --tokenizer_name." ) if args.model_name_or_path: model = AutoModelForCausalLM.from_pretrained( args.model_name_or_path, from_tf=bool(".ckpt" in args.model_name_or_path), config=config, ) else: logger.info("Training new model from scratch") model = AutoModelForCausalLM.from_config(config) model.resize_token_embeddings(len(tokenizer)) # Preprocessing the datasets. # First we tokenize all the texts. column_names = raw_datasets["train"].column_names text_column_name = "text" if "text" in column_names else column_names[0] def tokenize_function(examples): return tokenizer(examples[text_column_name]) with accelerator.main_process_first(): tokenized_datasets = raw_datasets.map( tokenize_function, batched=True, num_proc=args.preprocessing_num_workers, remove_columns=column_names, load_from_cache_file=not args.overwrite_cache, desc="Running tokenizer on dataset", ) if args.block_size is None: block_size = tokenizer.model_max_length if block_size > 1024: logger.warning( f"The tokenizer picked seems to have a very large `model_max_length` ({tokenizer.model_max_length}). " "Picking 1024 instead. You can change that default value by passing --block_size xxx." ) block_size = 1024 else: if args.block_size > tokenizer.model_max_length: logger.warning( f"The block_size passed ({args.block_size}) is larger than the maximum length for the model" f"({tokenizer.model_max_length}). Using block_size={tokenizer.model_max_length}." ) block_size = min(args.block_size, tokenizer.model_max_length) # Main data processing function that will concatenate all texts from our dataset and generate chunks of block_size. def group_texts(examples): # Concatenate all texts. concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()} total_length = len(concatenated_examples[list(examples.keys())[0]]) # We drop the small remainder, we could add padding if the model supported it instead of this drop, you can # customize this part to your needs. if total_length >= block_size: total_length = (total_length // block_size) * block_size # Split by chunks of max_len. result = { k: [t[i : i + block_size] for i in range(0, total_length, block_size)] for k, t in concatenated_examples.items() } result["labels"] = result["input_ids"].copy() return result # Note that with `batched=True`, this map processes 1,000 texts together, so group_texts throws away a remainder # for each of those groups of 1,000 texts. You can adjust that batch_size here but a higher value might be slower # to preprocess. # # To speed up this part, we use multiprocessing. See the documentation of the map method for more information: # https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map with accelerator.main_process_first(): lm_datasets = tokenized_datasets.map( group_texts, batched=True, num_proc=args.preprocessing_num_workers, load_from_cache_file=not args.overwrite_cache, desc=f"Grouping texts in chunks of {block_size}", ) train_dataset = lm_datasets["train"] eval_dataset = lm_datasets["validation"] # Log a few random samples from the training set: for index in random.sample(range(len(train_dataset)), 3): logger.info(f"Sample {index} of the training set: {train_dataset[index]}.") # DataLoaders creation: train_dataloader = DataLoader( train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=args.per_device_train_batch_size ) eval_dataloader = DataLoader( eval_dataset, collate_fn=default_data_collator, batch_size=args.per_device_eval_batch_size ) # Optimizer # Split weights in two groups, one with weight decay and the other not. no_decay = ["bias", "LayerNorm.weight"] optimizer_grouped_parameters = [ { "params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)], "weight_decay": args.weight_decay, }, { "params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], "weight_decay": 0.0, }, ] optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate) # On TPU, the tie weights in our model have been disconnected, so we need to restore the ties. if accelerator.distributed_type == DistributedType.TPU: model.tie_weights() # Scheduler and math around the number of training steps. num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps) if args.max_train_steps is None: args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch else: args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch) lr_scheduler = get_scheduler( name=args.lr_scheduler_type, optimizer=optimizer, num_warmup_steps=args.num_warmup_steps, num_training_steps=args.max_train_steps, ) # Prepare everything with our `accelerator`. model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare( model, optimizer, train_dataloader, eval_dataloader, lr_scheduler ) # Figure out how many steps we should save the Accelerator states if hasattr(args.checkpointing_steps, "isdigit"): checkpointing_steps = args.checkpointing_steps if args.checkpointing_steps.isdigit(): checkpointing_steps = int(args.checkpointing_steps) else: checkpointing_steps = None # We need to initialize the trackers we use, and also store our configuration if args.with_tracking: experiment_config = vars(args) # TensorBoard cannot log Enums, need the raw value experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value accelerator.init_trackers("clm_no_trainer", experiment_config) # Train! total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps logger.info("***** Running training *****") logger.info(f" Num examples = {len(train_dataset)}") logger.info(f" Num Epochs = {args.num_train_epochs}") logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}") logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}") logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}") logger.info(f" Total optimization steps = {int(args.max_train_steps/accelerator.num_processes)}") # Only show the progress bar once on each machine. progress_bar = tqdm( range(int(args.max_train_steps / accelerator.num_processes)), disable=not accelerator.is_local_main_process ) completed_steps = 0 # Potentially load in the weights and states from a previous save if args.resume_from_checkpoint: if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "": accelerator.print(f"Resumed from checkpoint: {args.resume_from_checkpoint}") accelerator.load_state(args.resume_from_checkpoint) resume_step = None path = args.resume_from_checkpoint else: # Get the most recent checkpoint dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()] dirs.sort(key=os.path.getctime) path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last if "epoch" in path: args.num_train_epochs -= int(path.replace("epoch_", "")) else: resume_step = int(path.replace("step_", "")) args.num_train_epochs -= resume_step // len(train_dataloader) resume_step = (args.num_train_epochs * len(train_dataloader)) - resume_step for epoch in range(args.num_train_epochs): model.train() if args.with_tracking: total_loss = 0 for step, batch in enumerate(train_dataloader): # We need to skip steps until we reach the resumed step if args.resume_from_checkpoint and epoch == 0 and step < resume_step: continue outputs = model(**batch) loss = outputs.loss # We keep track of the loss at each epoch if args.with_tracking: total_loss += loss.detach().float() loss = loss / args.gradient_accumulation_steps accelerator.backward(loss) if step % args.gradient_accumulation_steps == 0 or step == len(train_dataloader) - 1: optimizer.step() lr_scheduler.step() optimizer.zero_grad() progress_bar.update(1) completed_steps += 1 if isinstance(checkpointing_steps, int): if completed_steps % checkpointing_steps == 0: output_dir = f"step_{completed_steps}" if args.output_dir is not None: output_dir = os.path.join(args.output_dir, output_dir) accelerator.save_state(output_dir) if completed_steps >= args.max_train_steps: break model.eval() losses = [] for step, batch in enumerate(eval_dataloader): with torch.no_grad(): outputs = model(**batch) loss = outputs.loss losses.append(accelerator.gather(loss.repeat(args.per_device_eval_batch_size))) losses = torch.cat(losses) losses = losses[: len(eval_dataset)] try: perplexity = math.exp(torch.mean(losses)) except OverflowError: perplexity = float("inf") logger.info(f"epoch {epoch}: perplexity: {perplexity}") if args.with_tracking: accelerator.log( {"perplexity": perplexity, "train_loss": total_loss, "epoch": epoch, "step": completed_steps}, ) if args.push_to_hub and epoch < args.num_train_epochs - 1: accelerator.wait_for_everyone() unwrapped_model = accelerator.unwrap_model(model) unwrapped_model.save_pretrained(args.output_dir, save_function=accelerator.save) if accelerator.is_main_process: tokenizer.save_pretrained(args.output_dir) repo.push_to_hub( commit_message=f"Training in progress epoch {epoch}", blocking=False, auto_lfs_prune=True ) if args.checkpointing_steps == "epoch": output_dir = f"epoch_{epoch}" if args.output_dir is not None: output_dir = os.path.join(args.output_dir, output_dir) accelerator.save_state(output_dir) if args.output_dir is not None: accelerator.wait_for_everyone() unwrapped_model = accelerator.unwrap_model(model) unwrapped_model.save_pretrained(args.output_dir, save_function=accelerator.save) if accelerator.is_main_process: tokenizer.save_pretrained(args.output_dir) if args.push_to_hub: repo.push_to_hub(commit_message="End of training", auto_lfs_prune=True) with open(os.path.join(args.output_dir, "all_results.json"), "w") as f: json.dump({"perplexity": perplexity}, f) if __name__ == "__main__": main()
# Based on: https://github.com/pytorch/examples/blob/master/mnist/main.py import os import argparse import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torchvision import datasets, transforms from datetime import timedelta from torch.optim.lr_scheduler import StepLR import torch.distributed as dist import torch.multiprocessing as mp from torch.utils.data.distributed import DistributedSampler from torch.distributed.fsdp import FullyShardedDataParallel as FSDP def setup(rank, world_size): os.environ["MASTER_ADDR"] = "10.244.241.60" os.environ["MASTER_PORT"] = "1234" os.environ["RDZV_ENDPOINT"] = "10.244.241.60:1234" # initialize the process group dist.init_process_group("nccl", rank=rank, world_size=world_size, timeout=timedelta(seconds=10)) def cleanup(): dist.destroy_process_group() class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 32, 3, 1) self.conv2 = nn.Conv2d(32, 64, 3, 1) self.dropout1 = nn.Dropout(0.25) self.dropout2 = nn.Dropout(0.5) self.fc1 = nn.Linear(9216, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.conv1(x) x = F.relu(x) x = self.conv2(x) x = F.relu(x) x = F.max_pool2d(x, 2) x = self.dropout1(x) x = torch.flatten(x, 1) x = self.fc1(x) x = F.relu(x) x = self.dropout2(x) x = self.fc2(x) output = F.log_softmax(x, dim=1) return output def train(args, model, rank, world_size, train_loader, optimizer, epoch, sampler=None): model.train() ddp_loss = torch.zeros(2).to(rank) if sampler: sampler.set_epoch(epoch) for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(rank), target.to(rank) optimizer.zero_grad() output = model(data) loss = F.nll_loss(output, target, reduction="sum") loss.backward() optimizer.step() ddp_loss[0] += loss.item() ddp_loss[1] += len(data) dist.all_reduce(ddp_loss, op=dist.ReduceOp.SUM) if rank == 0: print("Train Epoch: {} \tLoss: {:.6f}".format(epoch, ddp_loss[0] / ddp_loss[1])) def test(model, rank, world_size, test_loader): model.eval() correct = 0 ddp_loss = torch.zeros(3).to(rank) with torch.no_grad(): for data, target in test_loader: data, target = data.to(rank), target.to(rank) output = model(data) ddp_loss[0] += F.nll_loss(output, target, reduction="sum").item() # sum up batch loss pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability ddp_loss[1] += pred.eq(target.view_as(pred)).sum().item() ddp_loss[2] += len(data) dist.all_reduce(ddp_loss, op=dist.ReduceOp.SUM) if rank == 0: test_loss = ddp_loss[0] / ddp_loss[2] print( "Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)\n".format( test_loss, int(ddp_loss[1]), int(ddp_loss[2]), 100.0 * ddp_loss[1] / ddp_loss[2] ) ) def fsdp_main(rank, world_size, args): setup(rank, world_size) transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) dataset1 = datasets.MNIST("../data", train=True, download=True, transform=transform) dataset2 = datasets.MNIST("../data", train=False, transform=transform) sampler1 = DistributedSampler(dataset1, rank=rank, num_replicas=world_size, shuffle=True) sampler2 = DistributedSampler(dataset2, rank=rank, num_replicas=world_size) train_kwargs = {"batch_size": args.batch_size, "sampler": sampler1} test_kwargs = {"batch_size": args.test_batch_size, "sampler": sampler2} cuda_kwargs = {"num_workers": 2, "pin_memory": True, "shuffle": False} train_kwargs.update(cuda_kwargs) test_kwargs.update(cuda_kwargs) train_loader = torch.utils.data.DataLoader(dataset1, **train_kwargs) test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs) torch.cuda.set_device(rank) init_start_event = torch.cuda.Event(enable_timing=True) init_end_event = torch.cuda.Event(enable_timing=True) model = Net().to(rank) model = FSDP(model) optimizer = optim.Adadelta(model.parameters(), lr=args.lr) scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma) init_start_event.record() for epoch in range(1, args.epochs + 1): train(args, model, rank, world_size, train_loader, optimizer, epoch, sampler=sampler1) test(model, rank, world_size, test_loader) scheduler.step() init_end_event.record() if rank == 0: print(f"CUDA event elapsed time: {init_start_event.elapsed_time(init_end_event) / 1000}sec") print(f"{model}") if args.save_model: # use a barrier to make sure training is done on all ranks dist.barrier() states = model.state_dict() if rank == 0: torch.save(states, "mnist_cnn.pt") cleanup() if __name__ == "__main__": # Training settings parser = argparse.ArgumentParser(description="PyTorch MNIST Example") parser.add_argument("--batch-size", type=int, default=64, metavar="N", help="input batch size for training (default: 64)") parser.add_argument( "--test-batch-size", type=int, default=1000, metavar="N", help="input batch size for testing (default: 1000)" ) parser.add_argument("--epochs", type=int, default=10, metavar="N", help="number of epochs to train (default: 14)") parser.add_argument("--lr", type=float, default=1.0, metavar="LR", help="learning rate (default: 1.0)") parser.add_argument("--gamma", type=float, default=0.7, metavar="M", help="Learning rate step gamma (default: 0.7)") parser.add_argument("--no-cuda", action="store_true", default=False, help="disables CUDA training") parser.add_argument("--seed", type=int, default=1, metavar="S", help="random seed (default: 1)") parser.add_argument("--save-model", action="store_true", default=False, help="For Saving the current Model") args = parser.parse_args() torch.manual_seed(args.seed) WORLD_SIZE = torch.cuda.device_count() mp.spawn(fsdp_main, args=(WORLD_SIZE, args), nprocs=WORLD_SIZE, join=True)
fsdp final
# Based on: https://github.com/pytorch/examples/blob/master/mnist/main.py import os import argparse import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torchvision import datasets, transforms from datetime import timedelta from torch.optim.lr_scheduler import StepLR import torch.distributed as dist import torch.multiprocessing as mp from torch.utils.data.distributed import DistributedSampler from torch.distributed.fsdp import FullyShardedDataParallel as FSDP def setup(rank, world_size): os.environ["MASTER_ADDR"] = "10.244.241.60" os.environ["MASTER_PORT"] = "1234" os.environ["RDZV_ENDPOINT"] = "10.244.241.60:1234" # initialize the process group dist.init_process_group("nccl", rank=rank, world_size=world_size, timeout=timedelta(seconds=10)) def cleanup(): dist.destroy_process_group() class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 32, 3, 1) self.conv2 = nn.Conv2d(32, 64, 3, 1) self.dropout1 = nn.Dropout(0.25) self.dropout2 = nn.Dropout(0.5) self.fc1 = nn.Linear(9216, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.conv1(x) x = F.relu(x) x = self.conv2(x) x = F.relu(x) x = F.max_pool2d(x, 2) x = self.dropout1(x) x = torch.flatten(x, 1) x = self.fc1(x) x = F.relu(x) x = self.dropout2(x) x = self.fc2(x) output = F.log_softmax(x, dim=1) return output def train(args, model, rank, world_size, train_loader, optimizer, epoch, sampler=None): model.train() ddp_loss = torch.zeros(2).to(rank) if sampler: sampler.set_epoch(epoch) for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(rank), target.to(rank) optimizer.zero_grad() output = model(data) loss = F.nll_loss(output, target, reduction="sum") loss.backward() optimizer.step() ddp_loss[0] += loss.item() ddp_loss[1] += len(data) dist.all_reduce(ddp_loss, op=dist.ReduceOp.SUM) if rank == 0: print("Train Epoch: {} \tLoss: {:.6f}".format(epoch, ddp_loss[0] / ddp_loss[1])) def test(model, rank, world_size, test_loader): model.eval() correct = 0 ddp_loss = torch.zeros(3).to(rank) with torch.no_grad(): for data, target in test_loader: data, target = data.to(rank), target.to(rank) output = model(data) ddp_loss[0] += F.nll_loss(output, target, reduction="sum").item() # sum up batch loss pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability ddp_loss[1] += pred.eq(target.view_as(pred)).sum().item() ddp_loss[2] += len(data) dist.all_reduce(ddp_loss, op=dist.ReduceOp.SUM) if rank == 0: test_loss = ddp_loss[0] / ddp_loss[2] print( "Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)\n".format( test_loss, int(ddp_loss[1]), int(ddp_loss[2]), 100.0 * ddp_loss[1] / ddp_loss[2] ) ) def fsdp_main(rank, world_size, args): setup(rank, world_size) transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) dataset1 = datasets.MNIST("../data", train=True, download=True, transform=transform) dataset2 = datasets.MNIST("../data", train=False, transform=transform) sampler1 = DistributedSampler(dataset1, rank=rank, num_replicas=world_size, shuffle=True) sampler2 = DistributedSampler(dataset2, rank=rank, num_replicas=world_size) train_kwargs = {"batch_size": args.batch_size, "sampler": sampler1} test_kwargs = {"batch_size": args.test_batch_size, "sampler": sampler2} cuda_kwargs = {"num_workers": 2, "pin_memory": True, "shuffle": False} train_kwargs.update(cuda_kwargs) test_kwargs.update(cuda_kwargs) train_loader = torch.utils.data.DataLoader(dataset1, **train_kwargs) test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs) torch.cuda.set_device(rank) init_start_event = torch.cuda.Event(enable_timing=True) init_end_event = torch.cuda.Event(enable_timing=True) model = Net().to(rank) model = FSDP(model) optimizer = optim.Adadelta(model.parameters(), lr=args.lr) scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma) init_start_event.record() for epoch in range(1, args.epochs + 1): train(args, model, rank, world_size, train_loader, optimizer, epoch, sampler=sampler1) test(model, rank, world_size, test_loader) scheduler.step() init_end_event.record() if rank == 0: print(f"CUDA event elapsed time: {init_start_event.elapsed_time(init_end_event) / 1000}sec") print(f"{model}") if args.save_model: # use a barrier to make sure training is done on all ranks dist.barrier() states = model.state_dict() if rank == 0: torch.save(states, "mnist_cnn.pt") cleanup() if __name__ == "__main__": # Training settings parser = argparse.ArgumentParser(description="PyTorch MNIST Example") parser.add_argument("--batch-size", type=int, default=64, metavar="N", help="input batch size for training (default: 64)") parser.add_argument( "--test-batch-size", type=int, default=1000, metavar="N", help="input batch size for testing (default: 1000)" ) parser.add_argument("--epochs", type=int, default=10, metavar="N", help="number of epochs to train (default: 14)") parser.add_argument("--lr", type=float, default=1.0, metavar="LR", help="learning rate (default: 1.0)") parser.add_argument("--gamma", type=float, default=0.7, metavar="M", help="Learning rate step gamma (default: 0.7)") parser.add_argument("--no-cuda", action="store_true", default=False, help="disables CUDA training") parser.add_argument("--seed", type=int, default=1, metavar="S", help="random seed (default: 1)") parser.add_argument("--save-model", action="store_true", default=False, help="For Saving the current Model") args = parser.parse_args() torch.manual_seed(args.seed) WORLD_SIZE = torch.cuda.device_count() mp.spawn(fsdp_main, args=(WORLD_SIZE, args), nprocs=WORLD_SIZE, join=True)