

 Seonglae Cho
Seonglae ChoAI Error Coding
debugs and fixes mistakes in its own code
effectiveness of self-repair is only seen in GPT-4 (bottlenecked by the feedback stage)
- using GPT-4 to give feedback on the programs generated by GPT-3.5
- using expert human programmers to give feedback on the programs generated by GPT-4
arxiv.org
https://arxiv.org/pdf/2306.09896.pdf
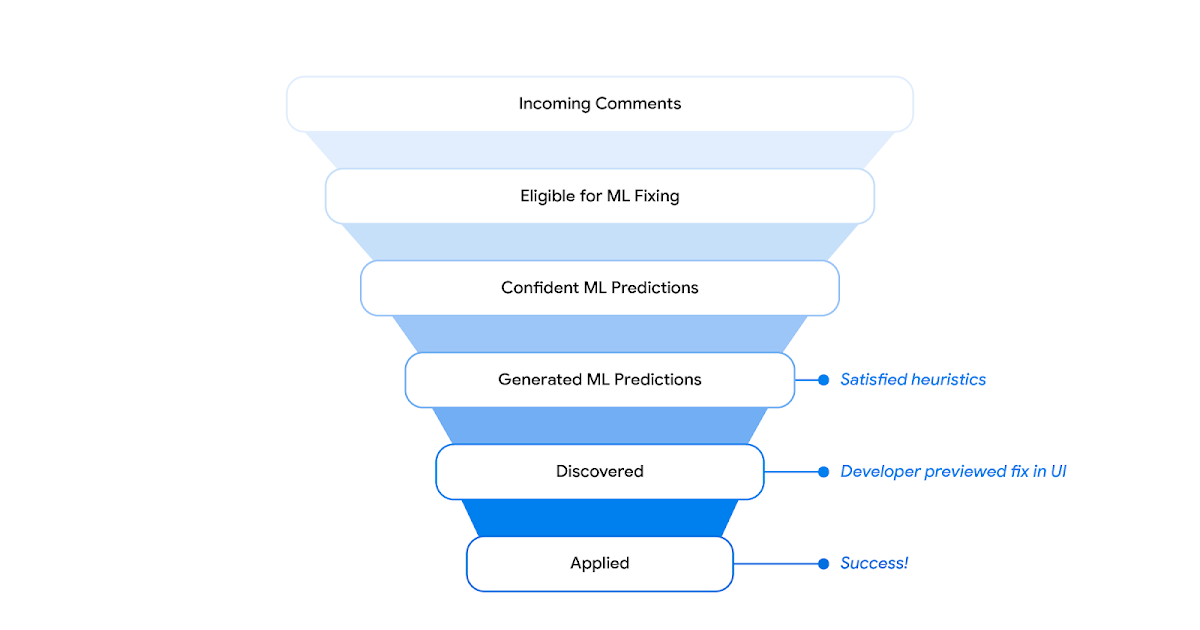
Resolving code review comments with ML
Resolving code review comments with ML
https://ai.googleblog.com/2023/05/resolving-code-review-comments-with-ml.html
Self-healing code
Self-healing code is the future of software development
Developers love automating solutions to their problems, and with the rise of generative AI, this concept is likely to be applied to both the creation, maintenance, and the improvement of code at an entirely new level.
https://stackoverflow.blog/2023/06/07/self-healing-code-is-the-future-of-software-development/

Robot Coding
Google is testing a new robot that can program itself
Writing working code can be a challenge. Even relatively easy languages like HTML require the coder to understand the specific syntax and available tools. Writing code to control robots is even more involved and often has multiple steps: There's code to detect objects, code to trigger the actuators that move the robot's limbs, code to specify when the task is complete, and so on.

https://www.popsci.com/technology/google-ai-robot-code-as-policies

Error
Replit — Building LLMs for Code Repair
Introduction At Replit, we are rethinking the developer experience with AI as a first-class citizen of the development environment. Towards this vision, we are tightly integrating AI tools with our IDE. Currently, LLMs specialized for programming are trained with a mixture of source code and relevant natural languages, such as GitHub issues and StackExchange posts. These models are not trained to interact directly with the development environment and, therefore, have limited ability to understand events or use tools within Replit. We believe that by training models native to Replit, we can create more powerful AI tools for developers. A simple example of a Replit-native model takes a session event as input and returns a well-defined response. We set out to identify a scenario where we could develop a model that could also become a useful tool for our current developers and settled on code repair. Developers spend a significant fraction of their time fixing bugs in software. In 2018, when Microsoft released “A Common Protocol for Languages,” Replit began supporting the Language Server Protocol. Since then, the LSP has helped millions using Replit to find errors in their code. This puts LSP diagnostics among our most common events, with hundreds of millions per day. However, while the LSP identifies errors, it can only provide fixes in limited cases. In fact, only 10% of LSP diagnostic messages in Python projects on Replit have associated fixes. Given the abundance of training data, repairing code errors using LSP diagnostics is therefore the ideal setting to build our first Replit-native AI model. Methodology Data

https://blog.replit.com/code-repair

Programming AIs worry me
For some inane reason, Github classifies me as a “major open source maintainer”, which means I get a free copilot subscription.1 I’ve been using it for a...
https://buttondown.email/hillelwayne/archive/programming-ais-worry-me
