

 Seonglae Cho
Seonglae ChoWe estimate covariance and mean vector of Gaussian Distributions
K-means Clustering approximated when variance approximate to 0 and all same
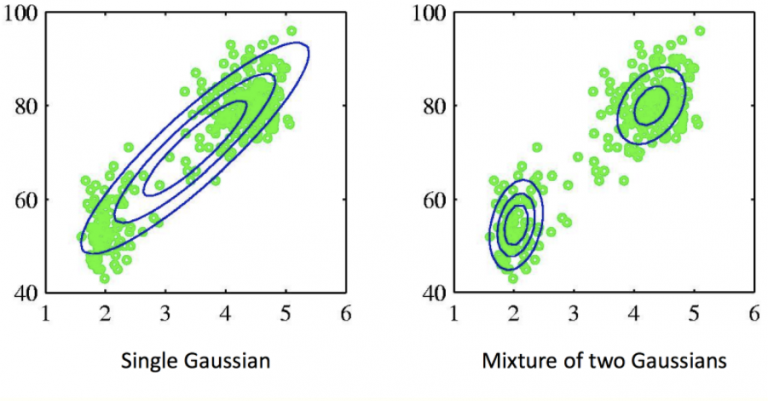
Mixture models can be used to build complex distribution and to cluster data
Solution
We can get by derivation of GMM’s Log Likelihood but they are independent so we need an algorithm such as EM Algorithm to get a solution.
- E: fix the distributions’ parameters, compute responsibilities using current parameter values (probabilities of belonging to each cluster)
- M: Re-estimate the parameters using the current responsibilities (fix the responsibilities)
Detail
- Initialize the distributions’ parameters and evaluate the initial value of the log likelihood
- For each data point, compute responsibilities using current parameter values
- Re-estimate the parameters using the current responsibilities
- Evaluate the log likelihood and check for convergence of either the parameters or the loglikelihood. If the convergence criterion not satisfied return to step 2
Pros
- Soft assign points to clusters
- Convergence is guaranteed but it may reach a locally optimal solution
GMM and EM algorithm
GMM에서 EM algorithm을 사용하는 이유를 설명했습니다.
https://velog.io/@gibonki77/VI-2
가우시안 혼합모형과 EM 방법 — 데이터 사이언스 스쿨
https://datascienceschool.net/03%20machine%20learning/18.01%20%EA%B0%80%EC%9A%B0%EC%8B%9C%EC%95%88%20%ED%98%BC%ED%95%A9%EB%AA%A8%ED%98%95%EA%B3%BC%20EM%20%EB%B0%A9%EB%B2%95.html
GMM과 EM 알고리즘 - 공돌이의 수학정리노트 (Angelo's Math Notes)
Prerequisites이 포스트를 더 잘 이해하기 위해선 아래의 내용에 대해 알고 오시는 것을 추천드립니다. k-means 알고리즘 최대우도법(Maximum Likelihood Estimation)아래의 EM 알고리즘까지 충분히 더 이해하시려면 이 내용도 알고오시는 것이 좋습...
https://angeloyeo.github.io/2021/02/08/GMM_and_EM.html