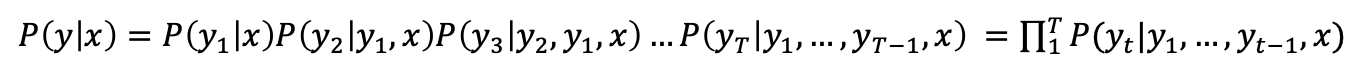Seonglae Cho
Seonglae ChoExhaustive Search, Greedy sampling, Greedy inference
One of decoding approach with Beam search
WEEK8 : beam search in language model
1. language model 언어 모델에서 사용되는 beam search를 설명하기 전에, 먼저 언어 모델에 대한 설명을 기록한다. 언어모델은 단어 시퀀스에 확률을 할당하는 일을 하는 모델이다. 단어 시퀀스에 확률을 할당할 때 주로 사용하는 방법은 이전 단어들이 주어졌을 때 다음 단어가 나온 빈도를 이용하는 것이다. 양쪽의 단어로부터 중심단어가 나오는 빈도를 이용하여 단어 시퀀스에 확률을 부여하는 다른 방법도 있긴 하다. 확률 할당 시 많이 사용하는 방법은 이전 단어들이 주어졌을 때 다음 단어가 나오는 빈도를 이용하는 것이라고 하였는데, 이 확률을 수식으로 표현하면 다음과 같다. $$ P(W) = P(w_1, w_2, w_3, ..., w_n) = \prod_{i=1}^{n}P(w_i|w_1, w_2..

https://hyoeun-log.tistory.com/m/entry/WEEK8-beam-search-in-language-model
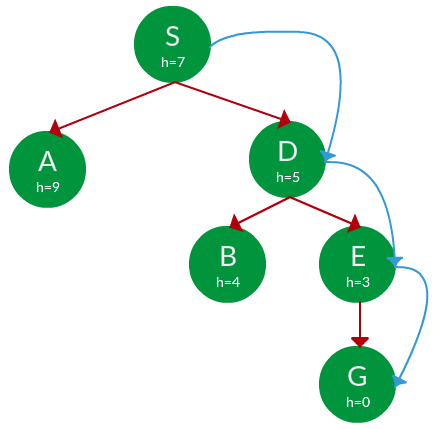
Beam Search 알아보기
매 타임 스텝마다 높은 확률을 가지는 단어 하나만을 선택해서 진행한다.이를 Greedy decoding이라고 한다.알고리즘 공부했을 때 배운, 그리디 알고리즘처럼 당시 상황에서의 최선의 선택을 하기 때문에 앞에 Greedy가 붙은 것 같다.이 단점중 하나는 뒤로 못 돌
https://velog.io/@bo-lim/Beam-Search