

 Seonglae Cho
Seonglae Choaccelerator.load_state("ckpt")
unwrapped_model.save_pretrained( args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save, state_dict=accelerator.get_state_dict(model), )
Best practice
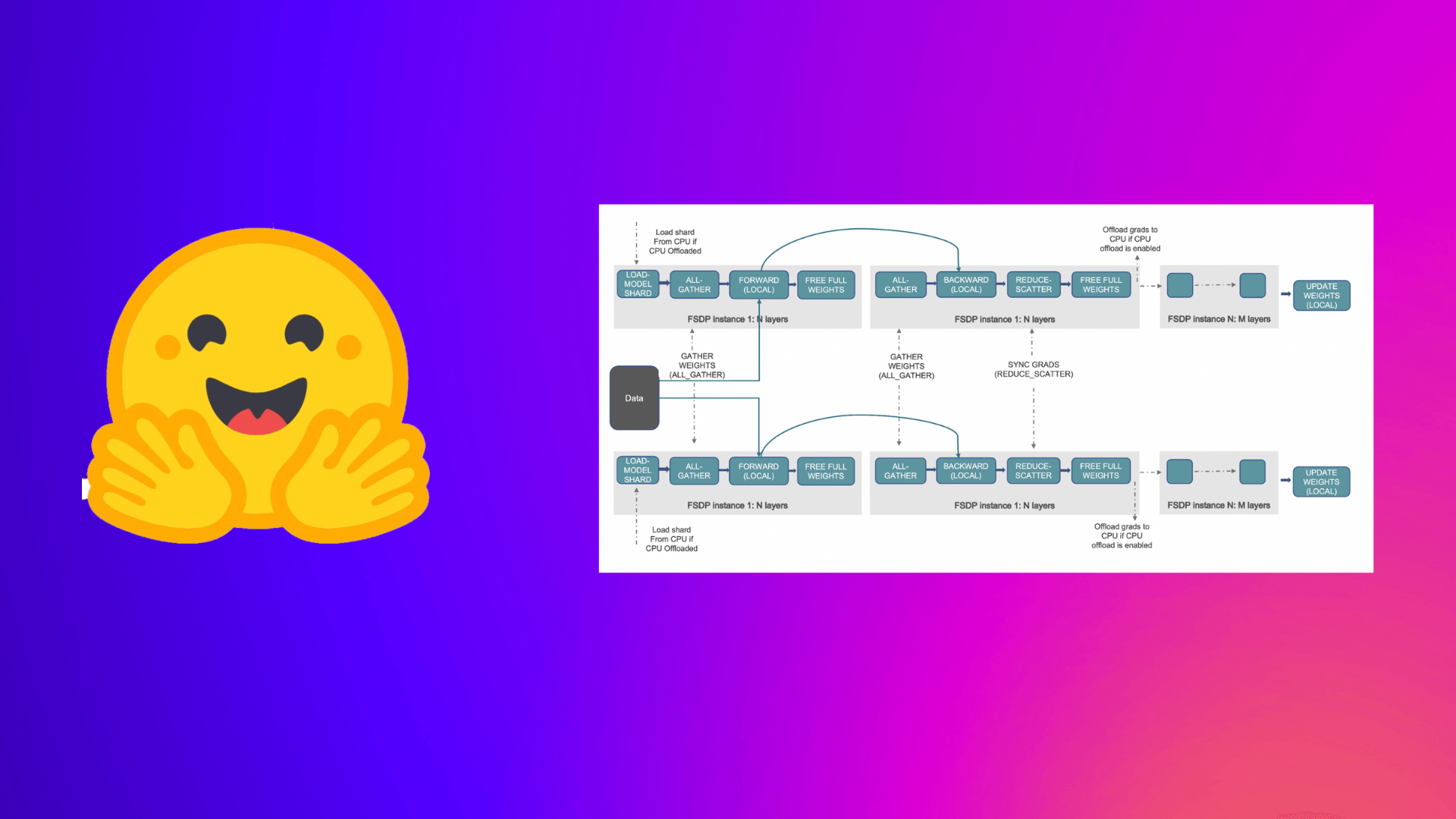
Fine-tuning Llama 2 70B using PyTorch FSDP
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
https://huggingface.co/blog/ram-efficient-pytorch-fsdp

Accelerate Large Model Training using PyTorch Fully Sharded Data Parallel
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
https://huggingface.co/blog/pytorch-fsdp
Usages
Fully Sharded Data Parallel
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
https://huggingface.co/docs/accelerate/usage_guides/fsdp#saving-and-loading

Fully Sharded Data Parallel
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
https://huggingface.co/docs/accelerate/usage_guides/fsdp