Seonglae Cho
Seonglae ChoEvent Driven interactive data streaming platform that can publish, store, and process data
Kafka Notion
Kafka Tools
What If We Could Rebuild Kafka From Scratch?
Update April 25: This post is being discussed on Hacker News, lobste.rs, and /r/apachekafka The last few days I spent some time digging into the recently announced KIP-1150 ("Diskless Kafka"), as well AutoMQ’s Kafka fork, tightly integrating Apache Kafka and object storage, such as S3. Following the example set by WarpStream, these projects aim to substantially improve the experience of using Kafka in cloud environments, providing better elasticity, drastically reducing cost, and paving the way towards native lakehouse integration. This got me thinking, if we were to start all over and develop a durable cloud-native event log from scratch—Kafka.next if you will—which traits and characteristics would be desirable for this to have? Separating storage and compute and object store support would be table stakes, but what else should be there? Having used Kafka for many years for building event-driven applications as well as for running realtime ETL and change data capture pipelines, here’s my personal wishlist:
https://www.morling.dev/blog/what-if-we-could-rebuild-kafka-from-scratch/
cons
Kafka at the low end: how bad can it get?
There is oft-quoted advice that Kafka does poorly as a job queue. I’ve experienced
this myself, and I wanted to formalize it a bit.
https://broot.ca/kafka-at-the-low-end.html
링크드인은 왜 카프카를 만들었나
애플리케이션 개발부터 파이프라인, 사물인터넷 데이터 허브 구축까지 아파치소프트웨어재단이 2011년 오픈소스로 공개한 카프카Kafka. 카프카는 비즈니스와 구인·구직 기반의 소셜 네트워크 서비스인 링크드인LinkedIn의 수석 엔지니어 제이 크렙스Jay Kreps가 고안했다. 크렙스는 카프카(메시징 시스템) 외에도 볼드모트Voldemort, 분산 키-값 저장소, 삼자Samza, 스트림 처리 시스템 등의 오픈소스 프로젝트를 이끈 인물로, 링크드인에서 개발한 비동기 메시징 시스템에 평소 존경했던 대문호 프란츠 카프카의 이름을 따서 '카프카'라 명명했다.

http://m.hanbit.co.kr//channel/category/category_view.html?cms_code=CMS9400468504

토스ㅣSLASH 22 - 왜 은행은 무한스크롤이 안되나요
은행 앱에서 한 달 전의 통장 거래내역을 보기 위해서는 스크롤을 이용할 수 없습니다. 귀찮더라도 조회 기간을 입력해야 하죠. 사실 이건 모든 은행의 서버 아키텍처와 관련된 문제이기도 합니다. 그렇다면 토스뱅크는 이 문제를 어떻게 해결했을까요?이응준 / 토스 Server Develo...

https://youtu.be/v9rcKpUZw4o

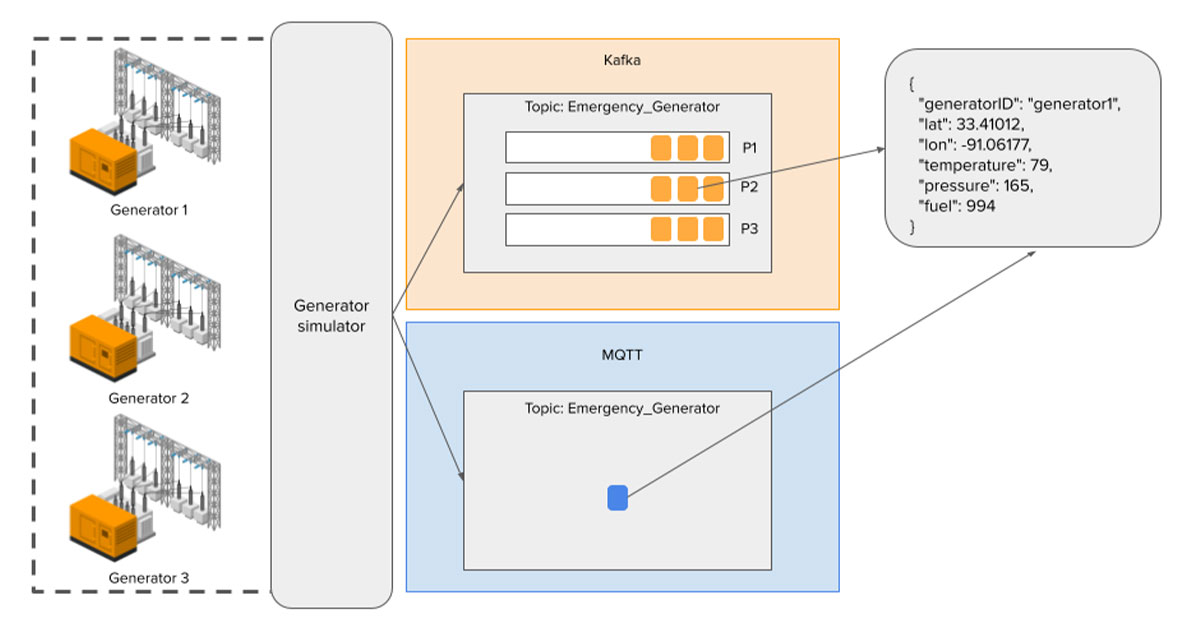
MQTT vs Kafka: An IoT Advocate's Perspective (Part 2 - Kafka the Mighty) | InfluxData
In Part 1 of this series, we started to compare the uses of Kafka and MQTT within an IoT infrastructure. It was concluded that in a basic publish-and-subscribe model of an IoT device, Kafka might simply be overkill.
https://www.influxdata.com/blog/mqtt-vs-kafka-an-iot-advocates-perspective-part-2/