

 Seonglae Cho
Seonglae ChoBig Data distributed Parallel Computing Software Frameworkv
- The core of MapReduce is two functions
- Big data processing should be kept as simple as possible
- Commutative and associative properties must hold
- MapReduce is a method to distribute tasks across multiple nodes
- For large tasks, repeatedly fork to divide, and join to merge when small
Limitations of MapReduce
- Memory cannot be wasted to hold the metadata of a large number of smaller data sets.
- The reduce phase cannot start until the map task is complete
- starting a new map task before the completion of the reduce task in the previous application is not possible in standard MapReduce
MapReduce Notion
jaff deen paper
MapReduce: Simplified Data Processing on Large Clusters - Google Research
MapReduce is a programming model and an associated implementation for processing and generating large data sets. Users specify a map function that processes a key/value pair to generate a set of intermediate key/value pairs, and a reduce function that merges all intermediate values associated with the same intermediate key.

https://research.google/pubs/pub62/

맵리듀스(MapReduce) 개념
Hadoop 맵리듀스(MapReduce) 개념 맵리듀스(MapReduce) 개념 맵리듀스(MapReduce)는 구글에서 정보 검색을 위한 데이터 가공(색인어 추출, 정렬 및 역 인덱스 생성)을 목적으로 개발된 분산 환경에서의 병렬 데이터 처리 기법이자 프로그래밍 모델이다. 맵리듀스는 비공유 구조(shared-nothing)로 연결된 여러 노드 PC들을 가지고 대량의 병렬처리 방식(MPP, Massively Parallel Processing)으로 대용량 데이터를 처리할 수 있는 방법을 제공한다.

https://m.blog.naver.com/PostView.nhn?blogId=jevida&logNo=140199795866&proxyReferer=https%3A%2F%2Fwww.google.com%2F
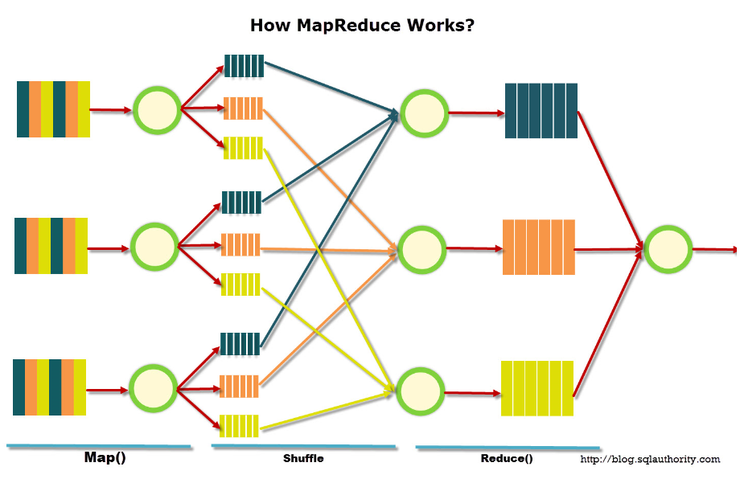
[하둡] 맵리듀스(MapReduce) 이해하기
맵리듀스는 여러 노드에 태스크를 분배하는 방법으로 각 노드 프로세스 데이터는 가능한 경우, 해당 노드에 저장됩니다. 맵리듀스 태스크는 맵(Map)과 리듀스(Reduce) 총 두단계로 구성됩니다. 간단한 예를 들면 fork-join의 개념을 들 수 있습니다. 큰 작업에 대해 fork로 분할하고 또다시 fork로 분할합니다. 작은 작업을 다시 join하게 됩니다. 하둡에서는 큰 데이터가 들어왔을 때 64MB단위 블럭으로 분할합니다.
![[하둡] 맵리듀스(MapReduce) 이해하기](https://t1.daumcdn.net/tistory_admin/static/top/favicon_0630.ico)
https://12bme.tistory.com/154
![[하둡] 맵리듀스(MapReduce) 이해하기](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Ft1.daumcdn.net%2Fcfile%2Ftistory%2F2136A84B59381A8428)