

 Seonglae Cho
Seonglae ChoMedusa
arxiv.org
https://arxiv.org/pdf/2401.10774.pdf
Fast Inference from Transformers via Speculative Decoding
[arXiv](2023/05/18 version v2) Abstract 여러 개의 토큰을 병렬로 계산하여 더 빠르게 샘플링하는 Speculative Decoding 제안 Speculative Decoding 효율적인 모델 Mq가 토큰 시퀀스를 생성하고 목표 모델 Mp가 해당 시퀀스를 평가하여 토큰을 수용하거나 거부하고, 대안을 생성한다. 각 라인은 한 번의 decoding step이다. Standardized Sampling Argmax, top-k, nucleus, temperature 등 다양한 샘플링 설정이 있지만 본문에서는 생략하고 일반적인 경우만 가정. Speculative Sampling 준비물: 각 모델, 토큰 시퀀스 γ개의 예측 생성 Mp를 병렬로 실행하여 γ개의 예측을 각각 생성 q(x)..

https://ostin.tistory.com/402

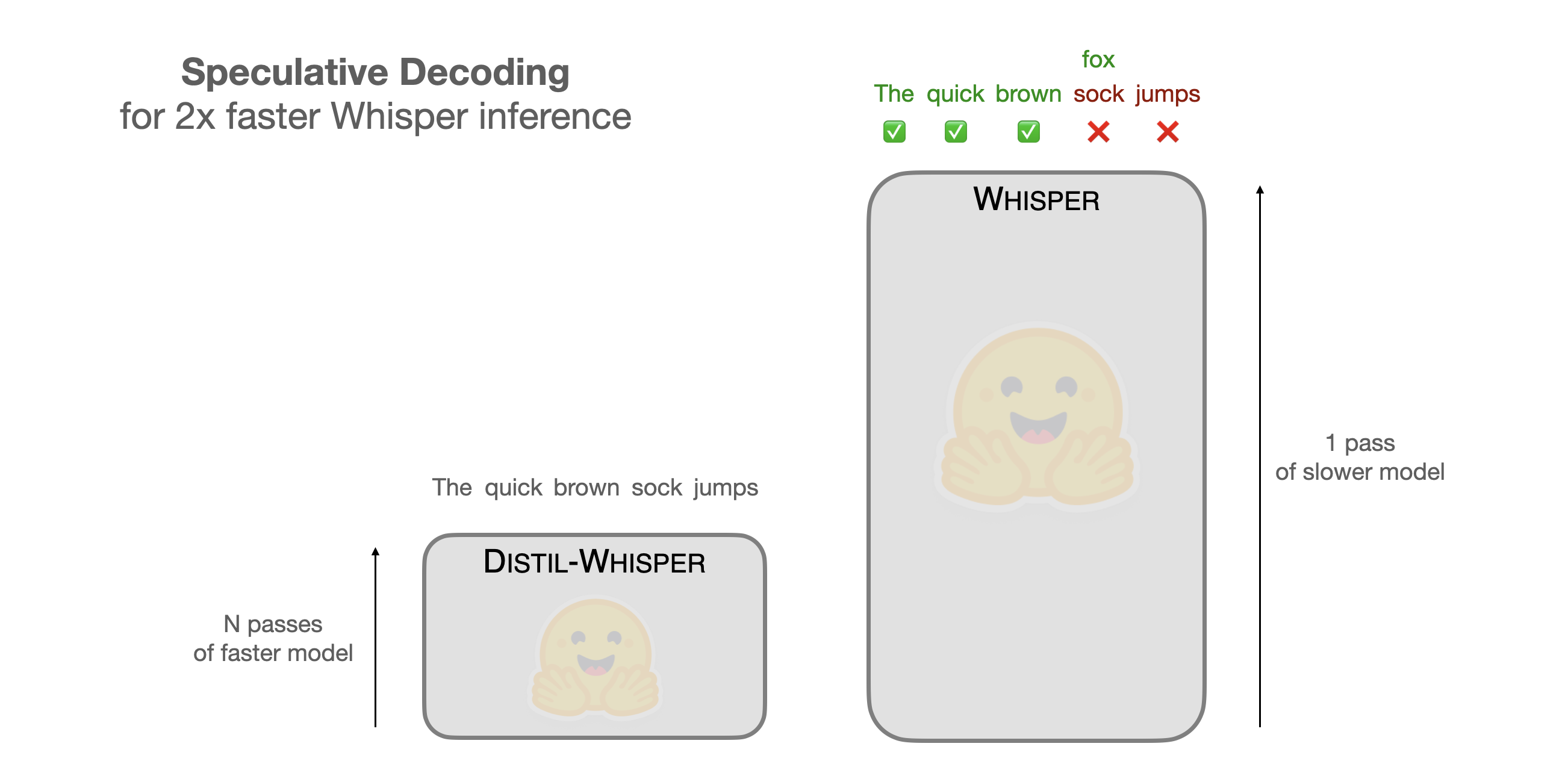
Speculative Decoding for 2x Faster Whisper Inference
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
https://huggingface.co/blog/whisper-speculative-decoding
arxiv.org
https://arxiv.org/pdf/2211.17192.pdf
arxiv.org
https://arxiv.org/pdf/2402.01528.pdf
Accelerating Generative AI with PyTorch II: GPT, Fast
This post is the second part of a multi-series blog focused on how to accelerate generative AI models with pure, native PyTorch. We are excited to share a breadth of newly released PyTorch performance features alongside practical examples to see how far we can push PyTorch native performance. In part one, we showed how to accelerate Segment Anything over 8x using only pure, native PyTorch. In this blog we’ll focus on LLM optimization.
https://pytorch.org/blog/accelerating-generative-ai-2/
