Seonglae Cho
Seonglae ChoData parallelism distributes training data across multiple GPUs, which generally works out of the box with proper attention to data loading mechanisms.
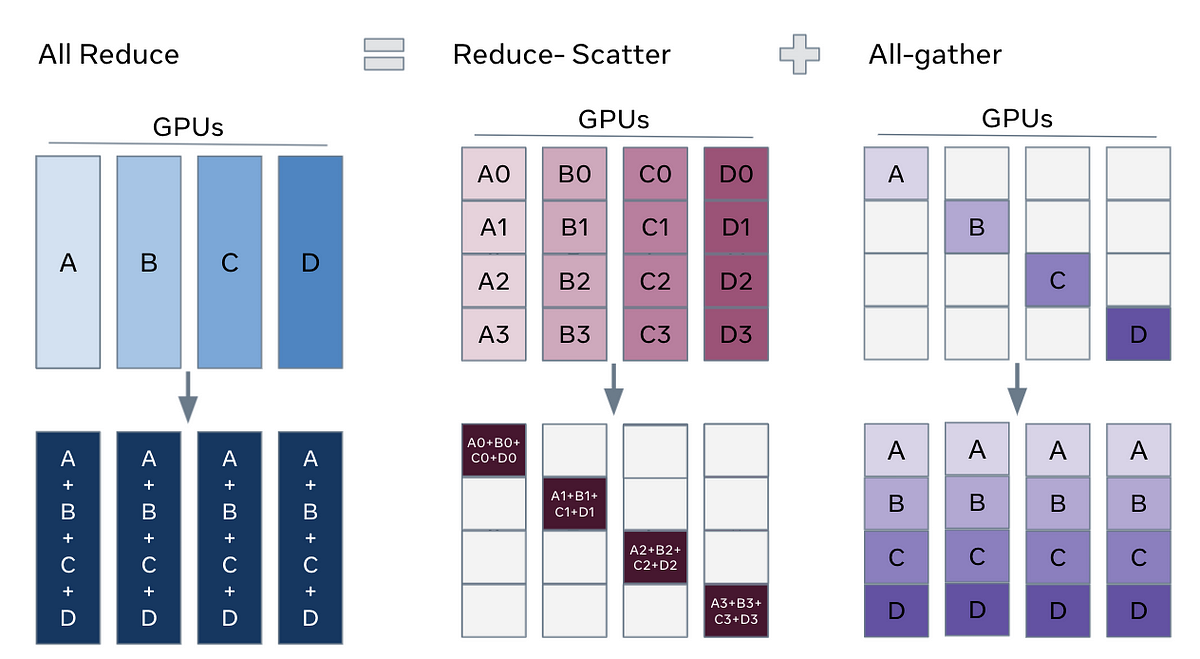
The main goal is to increase the number of Batch Processing instances that can be processed simultaneously. However, this approach faces two main challenges: computing efficiency for gradient all-reduce operations and maintaining training efficiency with increased batch sizes.
The process works in three main steps:
- Distribution of input data and model parameters to each GPU
- During backward propagation, gradients are computed separately for data on each GPU
- Finally, all gradients are collected and consolidated for model updates
Due to these overhead operations, traditional Data Parallelism (DP) doesn't scale linearly with the number of GPUs. Typically, one GPU acts as a control tower, which creates a bottleneck. Various approaches have emerged to address this limitation.
Distributed Data Parallel (DDP) is consistently superior to standard DP, while the choice between DDP and Fully Sharded Data Parallel (FSDP) depends on specific use cases and their trade-offs.
Limitation
Internal states and parameter gradients need to be exchanged at each and every single gradient step, all devices need to be co-located using low-latency high-bandwidth communication links.
DiLoCo have relaxed such co-location constraint: accelerators can be grouped into “workers”, where synchronizations between workers only occur infrequently.
Data Parallelism Usages
arxiv.org
https://arxiv.org/pdf/2211.05953.pdf
다중 GPU를 효율적으로 사용하는 방법: DP부터 FSDP까지
안녕하세요. 테서의 연구개발팀에서 의료 용어 해석을 진행하고 있는 노수철입니다.

https://medium.com/tesser-team/다중-gpu를-효율적으로-사용하는-방법-dp부터-fsdp까지-3057d31150b6