

 Seonglae Cho
Seonglae ChoFully Sharded Data Parallel
Save parameter, gradient, optimizer states for each other GPU and communicate
기본적인 구조는 DDP 와 유사하다
하나에 모두를 보관하지 않아도 되니, 통신에 대한 overhead가 늘어나는 대신, GPU가 다룰 수 있는 모델의 크기는 더 커진다는 장점
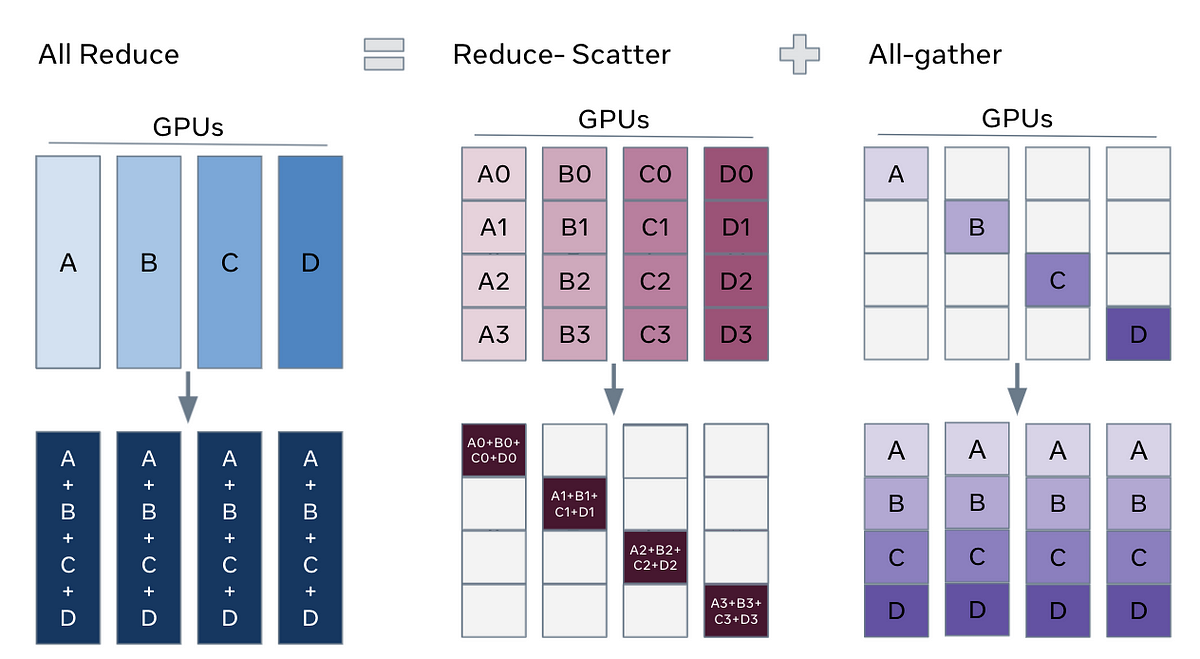
- forward 과정에서 모델의 각 layer를 통과할 때마다 다른 GPU에 저장되어 있는 파라미터를 가져와 사용하고 제거 (All Gather)
- backward 과정에서 다시 gradients를 계산하기 위해 다른 GPU에 저장되어 있는 파라미터를 가져와서 사용
- GPU에서 계산된 gradients를 다시 원래 속해 있던 GPU에 전달하기 위해서 Reduce Scatter 연산
- 각 GPU에는 각 GPU가 갖고 있던 모델에 대한 gradients만 남기 때문에, 이후 optimizer의 step 연산을 통해 모델의 파라미터를 업데이트
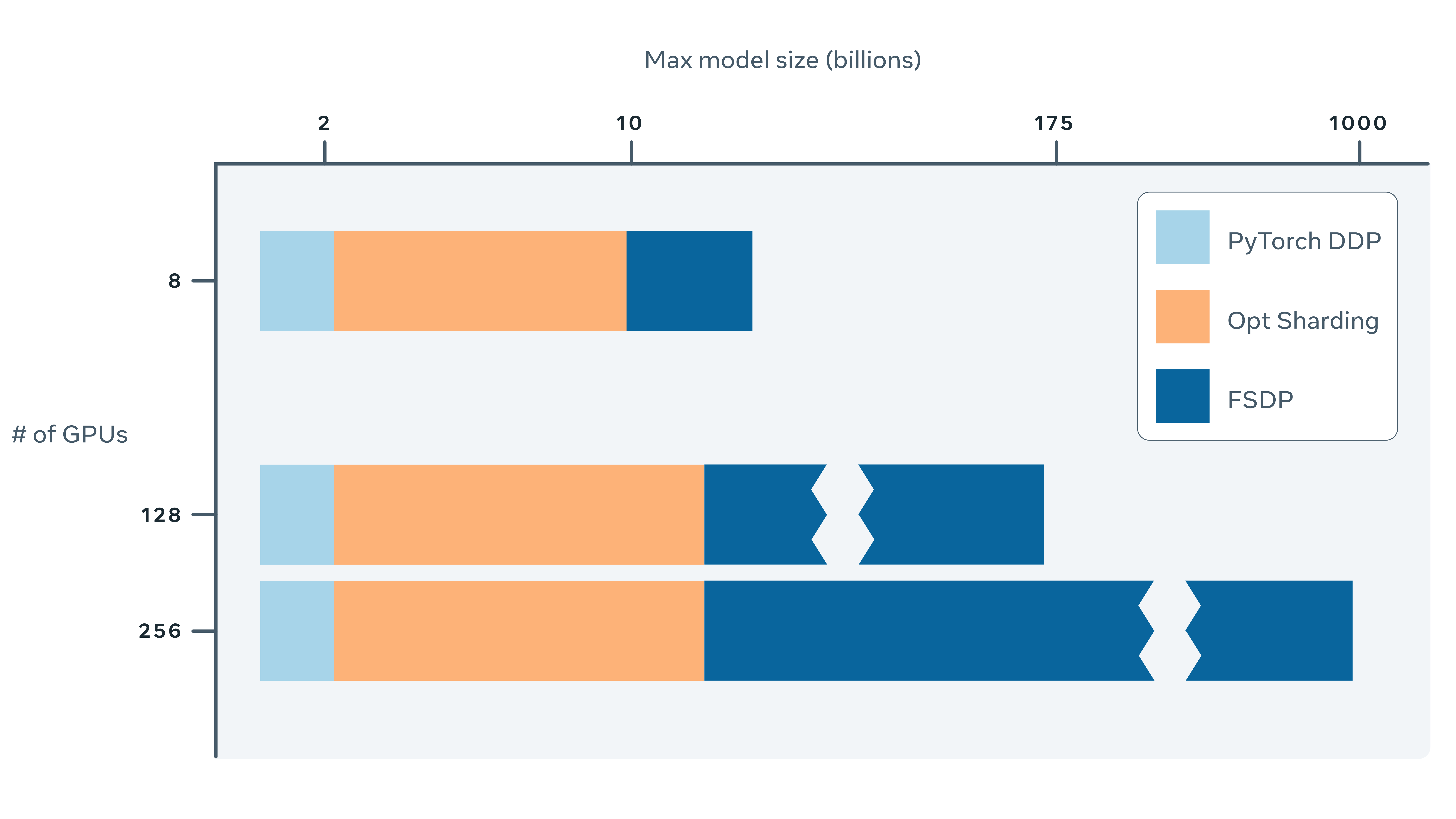
FSDP를 통해 GPU1개일때보다 GPU개수만큼의 batch를 동시에 실행할 수는 있지만 communication overhead가 커서 DDP 보다 느릴 수도 있다. 가장 큰 장점은 더 큰 모델을 GPU개수에 따라 스케일링이 가능하다는 것 (AI Scaling )

Fully Sharded Data Parallel: faster AI training with fewer GPUs
Training AI models at a large scale isn’t easy. Aside from the need for large amounts of computing power and resources, there is also considerable engineering complexity behind training very large …

https://engineering.fb.com/2021/07/15/open-source/fsdp/
Operations — NCCL 2.6.4 documentation
Like MPI collective operations, NCCL collective operations have to be called for each rank (hence CUDA device) to form a complete collective operation. Failure to do so will result in other ranks waiting indefinitely.
https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/usage/operations.html
다중 GPU를 효율적으로 사용하는 방법: DP부터 FSDP까지
안녕하세요. 테서의 연구개발팀에서 의료 용어 해석을 진행하고 있는 노수철입니다.

https://medium.com/tesser-team/다중-gpu를-효율적으로-사용하는-방법-dp부터-fsdp까지-3057d31150b6
PyTorch Data Parallel Best Practices on Google Cloud
Authors: Shen Li (Meta AI), Jessica Choi (Meta AI), Pavel Belevich (Meta AI), Yanli Zhao (Meta AI), Rohan Varma (Meta AI), Geeta Chauhan…
https://medium.com/pytorch/pytorch-data-parallel-best-practices-on-google-cloud-6c8da2be180d