Seonglae Cho
Seonglae ChoSimulates a real software engineering environment (code modifications, builds, tests, etc.) and solves problems using various tools (terminal, file editing, etc.) within an RL environment
Hybrid Verifier
Combines execution-free (LLM evaluates patches) + execution-based (actual test execution) approaches
GRPO++ (to build DeepSWE, Together AI)
Drawing ideas from DAPO, Dr.GRPO, LOOP/RLOO and others, the following improvements were added:
- Clip High (DAPO): Increase surrogate loss upper bound to enhance exploration
- No KL Loss (DAPO)
- No Reward Std, Length Normalization (Dr.GRPO)
- Leave One Out: Reduce variance by removing one sample when estimating advantage (Loop/RLOO)
- Compact Filtering: Mask trajectories when reaching max context/steps/timeout
- No Entropy Loss: Remove entropy loss to prevent instability
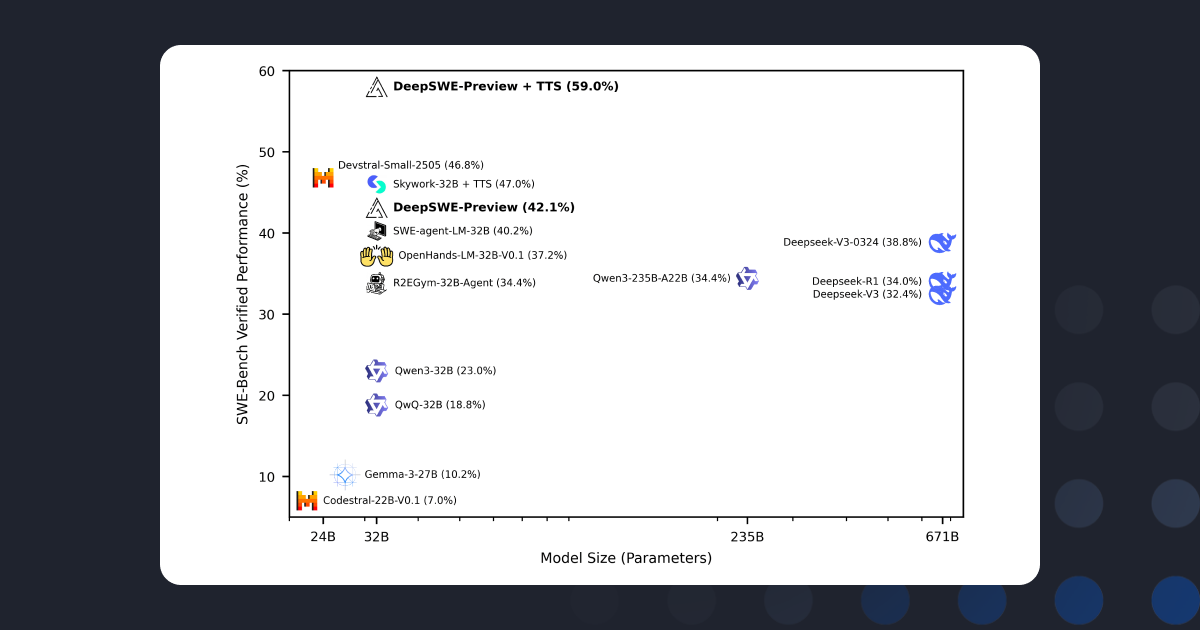
DeepSWE: Training a Fully Open-sourced, State-of-the-Art Coding Agent by Scaling RL
Michael Luo*, Naman Jain*, Jaskirat Singh*, Sijun Tan*, Ameen Patel*, Qingyang Wu*, Alpay Ariyak*, Colin Cai*, Tarun Venkat, Shang Zhu, Ben Athiwaratkun, Manan Roongta, Ce Zhang, Li Erran Li, Raluca Ada Popa, Koushik Sen, Ion Stoica

https://www.together.ai/blog/deepswe