Seonglae Cho
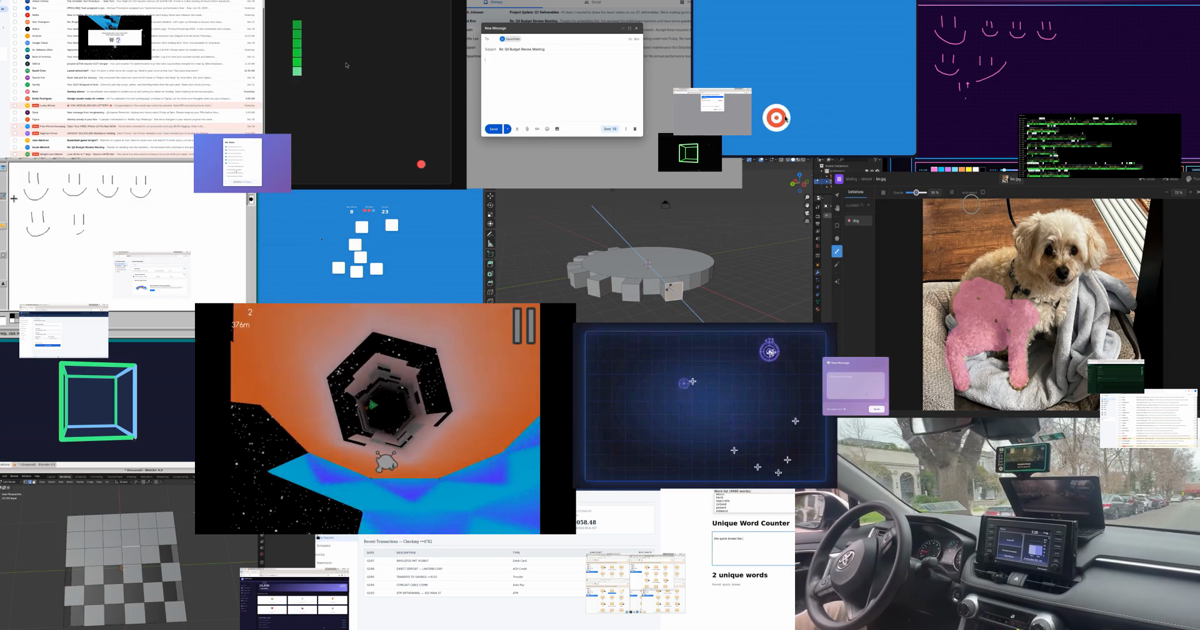
Seonglae ChoFDM-1 addresses the training-data bottleneck caused by manual labeling by leveraging an internet-scale dataset of 11M hours of screen recordings. It first trains an inverse dynamics model (IDM) on screen recordings. The IDM uses a masked-diffusion architecture: it inserts mask tokens between frames and predicts actions for all frames simultaneously (non-causal). At inference time, it uses a 16-step noise schedule, progressively unmasking from positions with the highest log-probability—committing quickly to confident actions and spending more compute on ambiguous ones. Second, the trained IDM automatically assigns action labels to the 11M-hour video corpus. Third, using this labeled video, it trains a forward dynamics model (FDM) autoregressively for next-action prediction. The FDM’s output token space consists of keypress tokens and mouse-movement deltas; mouse movement is discretized into 49 bins via exponential binning.
FDM-1’s video encoder is trained with a masked compression objective, compressing about 1 hour 40 minutes of video into 1M tokens. This yields roughly 50× better token efficiency than prior SOTA and about 100× better than the OpenAI encoder. With 32k tokens it can process ~3 minutes 30 seconds of video; with 200k tokens it can process ~20 minutes. The encoder is trained with a self-supervised prediction task inspired by V-JEPA, and it converges about 100× faster on text-transcription accuracy than a ViT baseline. Unlike VLMs, the FDM operates directly on video and action tokens without chain-of-thought or BPE, resulting in low inference latency.
A single H100 can control 42 VMs in parallel, with an 11 ms round-trip latency from screen capture to action. Compared to contractor-labeled data, IDM-labeled data matches or outperforms on Target Accuracy, Symbolic Memory, and UI Manipulation, while showing slightly slower gains on typing and language understanding. In autonomous-driving tests, with under one hour of fine-tuning data, FDM-1 could drive city blocks in San Francisco; it starts at ~50% accuracy on key-input prediction, meaningfully exceeds a vision-only baseline, and shows a steeper scaling trend. It also demonstrates complex long-horizon tasks such as CAD (e.g., modeling gears in Blender) and website fuzzing (e.g., discovering bugs in a banking app). For real-world tasks like autonomous driving, it has not yet achieved true zero-shot performance and still requires fine-tuning.
The First Fully General Computer Action Model
We trained a model on our 11-million-hour video dataset. Our model can explore complex websites, complete multi-action CAD modeling sequences, and drive a car in the real world, all at 30 FPS.
https://si.inc/posts/fdm1/