

 Seonglae Cho
Seonglae Cho

K3
moonshotai/Kimi-K3 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
https://huggingface.co/moonshotai/Kimi-K3

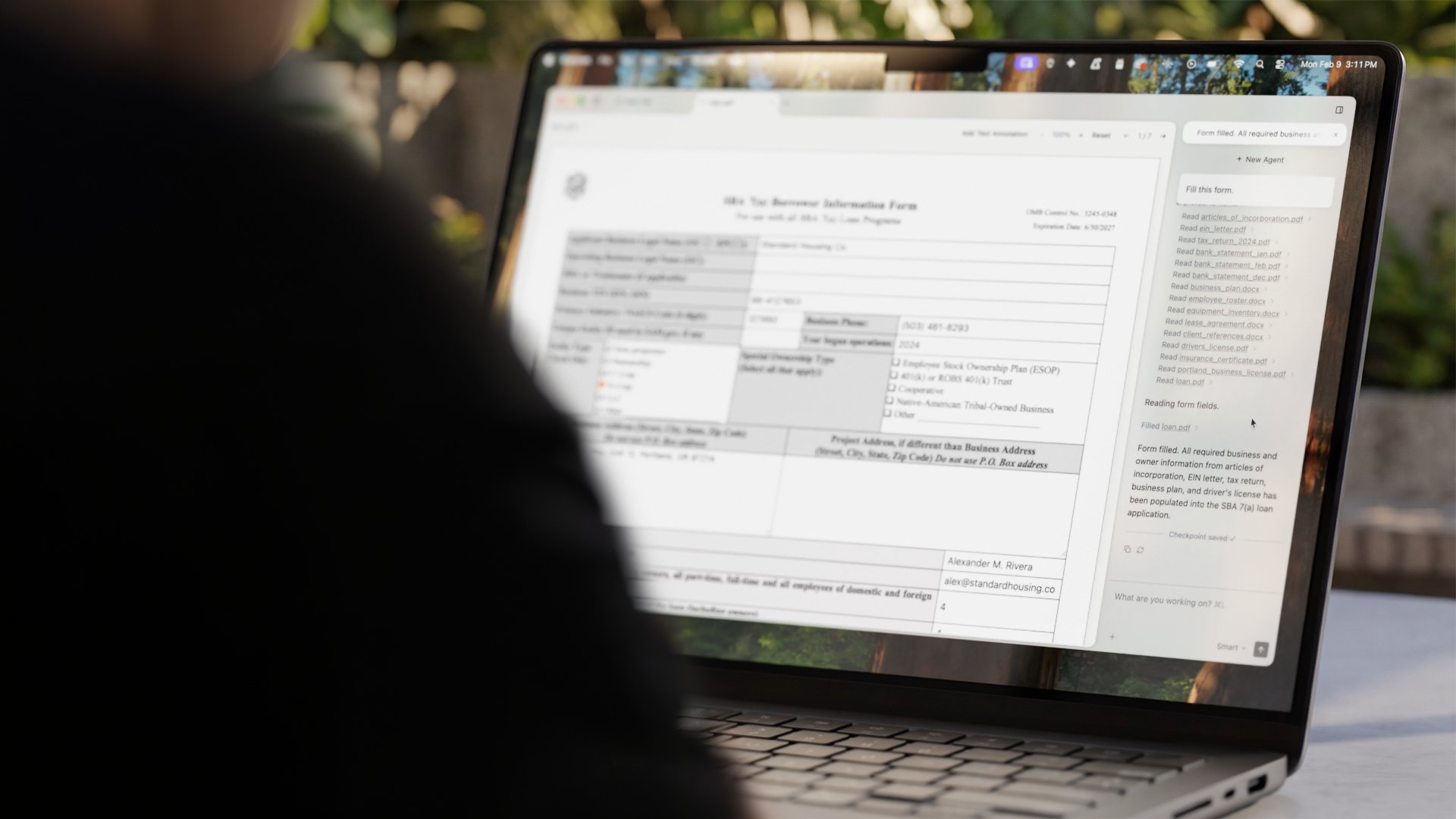
Interpreter: The Desktop Agent
Interpreter lets you work alongside agents that can edit your documents, fill PDF forms, and more.
https://www.openinterpreter.com/
Kimi K3 Tech Blog: Open Frontier Intelligence
Kimi K3 is the world's first open 3T-class model — frontier performance across coding, knowledge work, and reasoning, with native multimodality and 1M context.
https://www.kimi.com/blog/kimi-k3
quantized
pipenetwork/Kimi-K3-REAP73-zh-code-MLX-mxfp4-q8 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
https://huggingface.co/pipenetwork/Kimi-K3-REAP73-zh-code-MLX-mxfp4-q8

Kimi K2
- agentic planning
- tool use
Kimi K2: Open Agentic Intelligence
Kimi K2 is our latest Mixture-of-Experts model with 32 billion activated parameters and 1 trillion total parameters. It achieves state-of-the-art performance in frontier knowledge, math, and coding among non-thinking models.
https://moonshotai.github.io/Kimi-K2/
K2 Tinker
Tinker: General Availability and Vision Input
Today we are announcing four updates to Tinker: No more waitlist New reasoning model: Kimi K2 Thinking New inference interface that is compatible with the OpenAI API Vision input support with Qwen3-VL General availability The waitlist is over! Everybody can use Tinker now; sign up here to get started. See the Tinker homepage for available models and pricing, and check out the Tinker cookbook for code examples. More reasoning with Kimi K2 Thinking Users can now fine-tune Kimi K2 Thinking on Tinker. With a trillion parameters, Kimi K2 is the largest model in our lineup so far. It is built for long chains of reasoning and tool use.
https://thinkingmachines.ai/blog/tinker-general-availability/

2.5 Agent Swarm
When the total vision+text token budget is fixed, "early fusion" (mixing vision and text tokens from the start at a constant ratio) converges more stably and achieves better final performance than "late injection" (adding many vision tokens at the end). Suddenly injecting many vision tokens in the middle or later stages causes the representation space to be disturbed by "modality domain shift," resulting in a dip-and-recover pattern in text performance.
Zero-Vision SFT activates visual capabilities using only text. If vision↔text alignment is already established to some extent during joint pretraining, running only visual RL can improve text benchmarks (MMLU-Pro, GPQA, LongBench).
DEP (Decoupled Encoder Process): An infrastructure trick claiming 90% multimodal training efficiency.
- Balanced Vision Forward
- Backbone Training
- Vision recompute + backward
Agent Swarm + PARL: "Only the orchestrator is trained with RL, sub-agents are frozen." PARL reward: r_parallel + r_finish + r_perf. GRM (Generative Reward Model) is not a "critic" but rather a reward model that scores rewards.
arxiv.org
https://arxiv.org/pdf/2602.02276
Kimi K2.5 and Agent Swarm explained...
Moonshot finally released their new Kimi K2.5 now includes multimodality and agent swarm that can spawn up to 100 agents with 1500 tool calls. Kimi's new model here can replicate websites for vibe coders who want to just submit images or videos. This is yet another bold step in technology as Chinese frontier AI labs continue to innovate LLMs to compete, and now SOTA level models like Kimi is showing its strength with PARL or Parallel Agent Reinforcement Learning, and Critical Step to ensure that the orchestration of agents are done higher in the LLM stack which enables agentic applicaitions to leverage this for faster task automation.
Try out Kimi K2.5 (Free 3 uses Agent Swarm - 24 hours)
https://www.kimi.com/?invite=okc&code=UM82dfeX
#llm #deeplearning #ai #artificialintelligence #largelanguagemodels #technology
Chapters
00:00 Intro
00:48 Kimi
01:48 LLM vs Agents
02:37 PARL
04:13 CriticalSteps
05:42 Agent Swarm
06:30 Inference
07:53 Valuation
08:35 Conclusion

https://www.youtube.com/watch?v=GwKoFpUV69M
