

 Seonglae Cho
Seonglae ChoLLM Benchmarks
Language Model Metrics
LLM Evaluation Tools
Community Eval
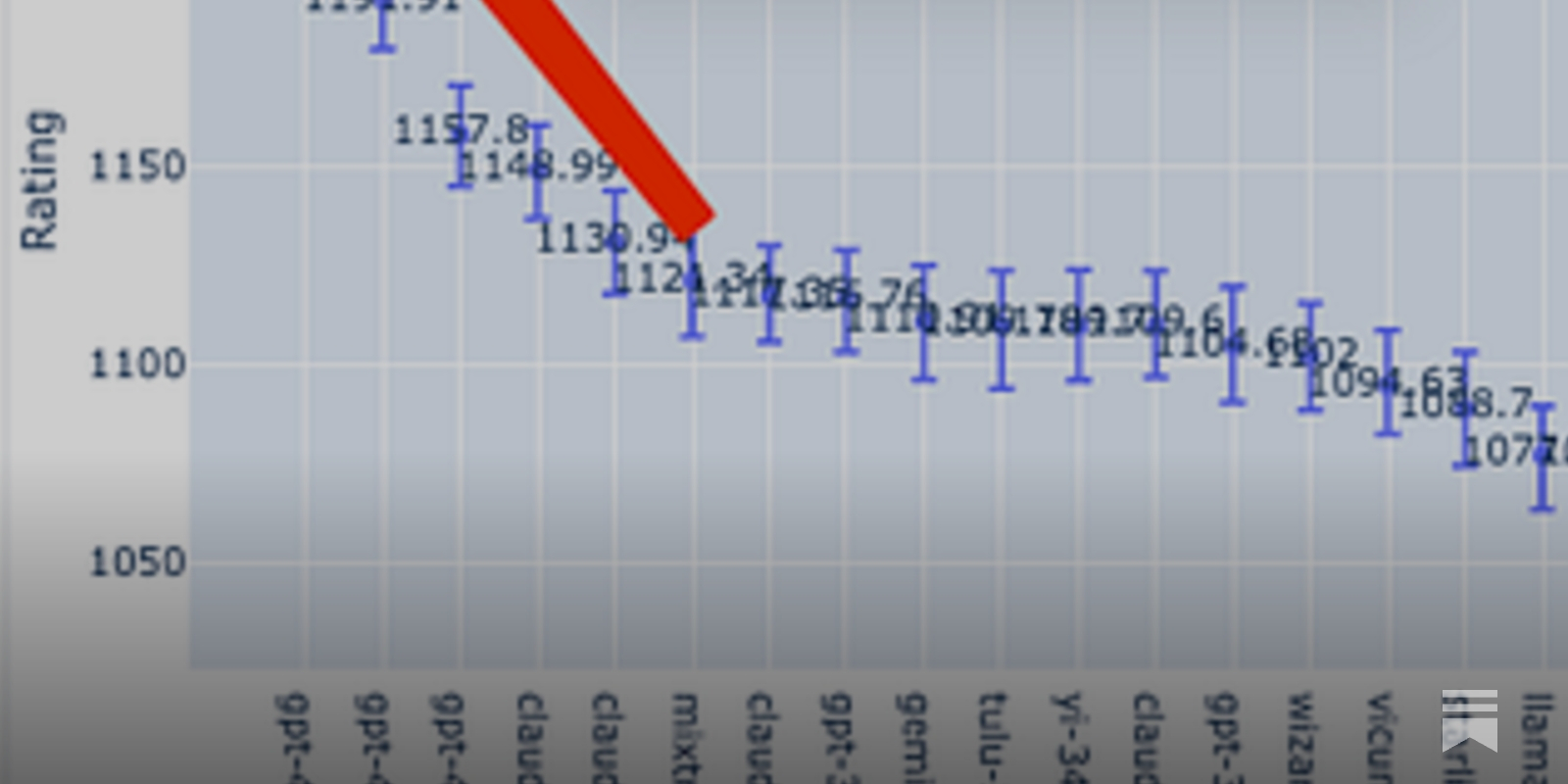
Community Evals: Because we're done trusting black-box leaderboards over the community
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
https://huggingface.co/blog/community-evals

Even a small improvement in per-step accuracy can lead to significant performance differences in long-horizon tasks due to cumulative effects. Therefore, the economic value of LLMs should be measured by how accurately they perform long tasks. Accuracy improvements result in exponential increases in achievable task length. The relationship between step accuracy p and success rate s:
arxiv.org
https://arxiv.org/pdf/2509.09677
While MMLU is a simple multiple-choice evaluation, even minor changes in option formatting can significantly affect performance scores. On the other hand, evaluations like BBQ Benchmark, Big-Bench, and HELM are noted for their complexity due to challenges in implementation, interpretation, and technical intricacies that make it difficult to accurately measure model performance.
Challenges in evaluating AI systems
Anthropic is an AI safety and research company that's working to build reliable, interpretable, and steerable AI systems.
https://www.anthropic.com/research/evaluating-ai-systems

Evaluating LLMs is complex so more comprehensive and purpose-specific evaluation methods is needed to assess their capabilities for various real-world applications
Evaluations are all we need
On analysing talent in LLMs
https://www.strangeloopcanon.com/p/evaluations-are-all-we-need
AI Models Are Getting Smarter. New Tests Are Racing to Catch Up
As AI models rapidly advance, evaluations are racing to keep up.
https://time.com/7203729/ai-evaluations-safety/

Every time we solve something previously out of reach, it turns out that human-level generality is even further out of reach.
My model of what is going on with LLMs — LessWrong
We have seen LLMs scale to impressively general performance. This does not mean they will soon reach human level because intelligence is not just a k…

https://www.lesswrong.com/posts/vvgND6aLjuDR6QzDF/my-model-of-what-is-going-on-with-llms
