

 Seonglae Cho
Seonglae ChoMixture-of-Experts
MoE is the most promising AI Scaling direction from a computing perspective, especially with Reasoning Model
Mixture-of-Experts models improves efficiency by activating a small subset of model weights for a given input, decoupling model size from inference efficiency.
MoEs have seen great success in LLMs. In a nutshell, MoEs are pre-trained faster, and have a faster inference, but require more memory and face challenges in fine-tuning.
MoE enables vector-based communication between models rather than language-based communication, unlike AI Agent
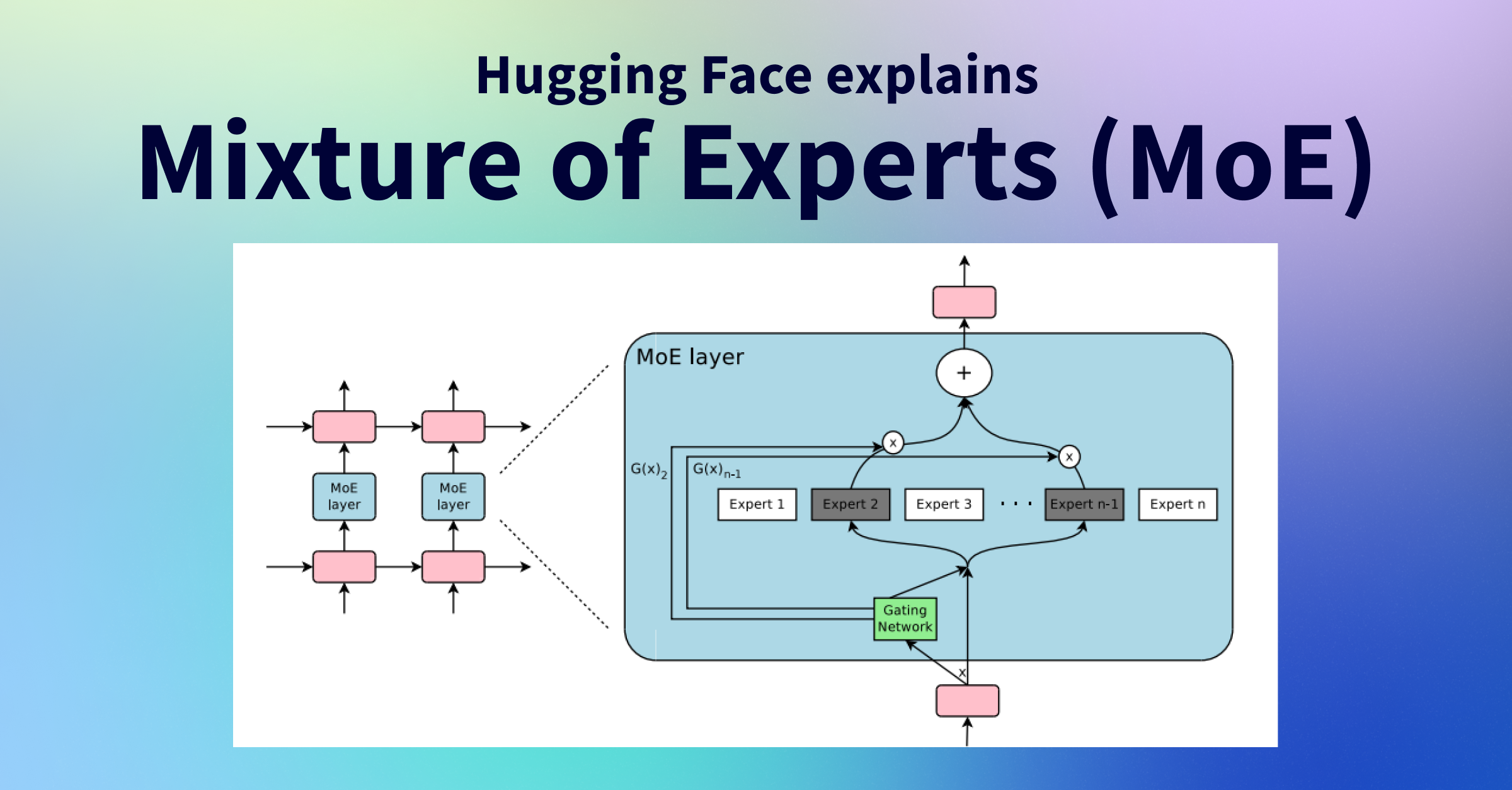
Transformer MoE
Usually only the MLP layer is divided into MoE and routed by layer. The reason why MoE uses Weight Sharing for the attention layer is that, aside from the training being difficult, it's an inter-token operation where token residual embedding changes, making it problematic if not shared, while the MLP, which isn't like that, is suitable for MoE as it acts as a key-value storage with diverse memory.
The reason why Cross-Attention doesn't occur between experts is because the input residual and attention are coupled together, but like what the Corpus callosum does, information exchange like cross-attention between the Left Cerebral hemisphere and Right Left Cerebral hemisphere is a good design insight
MoE Notion
Structure

Mixture of Experts Explained
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
https://huggingface.co/blog/moe
1991
www.cs.toronto.edu
https://www.cs.toronto.edu/~hinton/absps/jjnh91.pdf
Scaling for chips
All the Transformer Math You Need to Know | How To Scale Your Model
Here we'll do a quick review of the Transformer architecture, specifically how to calculate FLOPs, bytes, and other quantities of interest.

https://jax-ml.github.io/scaling-book/transformers/
Even though it’s well known that MoE (Mixture-of-Experts) models can scale capacity while reducing per-token compute compared to dense models, MoE can still outperform dense models even when the total number of parameters, training compute, and data budget are held exactly constant.
kamanphoebe/moe_surpass_dense · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
https://huggingface.co/kamanphoebe/moe_surpass_dense

Agentic AI and the next intelligence explosion
The "AI singularity" is often miscast as a monolithic, godlike mind. Evolution suggests a different path: intelligence is fundamentally plural, social, and relational. Recent advances in agentic...
https://arxiv.org/abs/2603.20639