

 Seonglae Cho
Seonglae ChoCurrently, use LLM text summary not real Vision Model embedding


Multi-Vector Retriever for RAG on tables, text, and images
Summary Seamless question-answering across diverse data types (images, text, tables) is one of the holy grails of RAG. We’re releasing three new cookbooks that showcase the multi-vector retriever for RAG on documents that contain a mixture of content types. These cookbooks as also present a few ideas for pairing
https://blog.langchain.dev/semi-structured-multi-modal-rag/
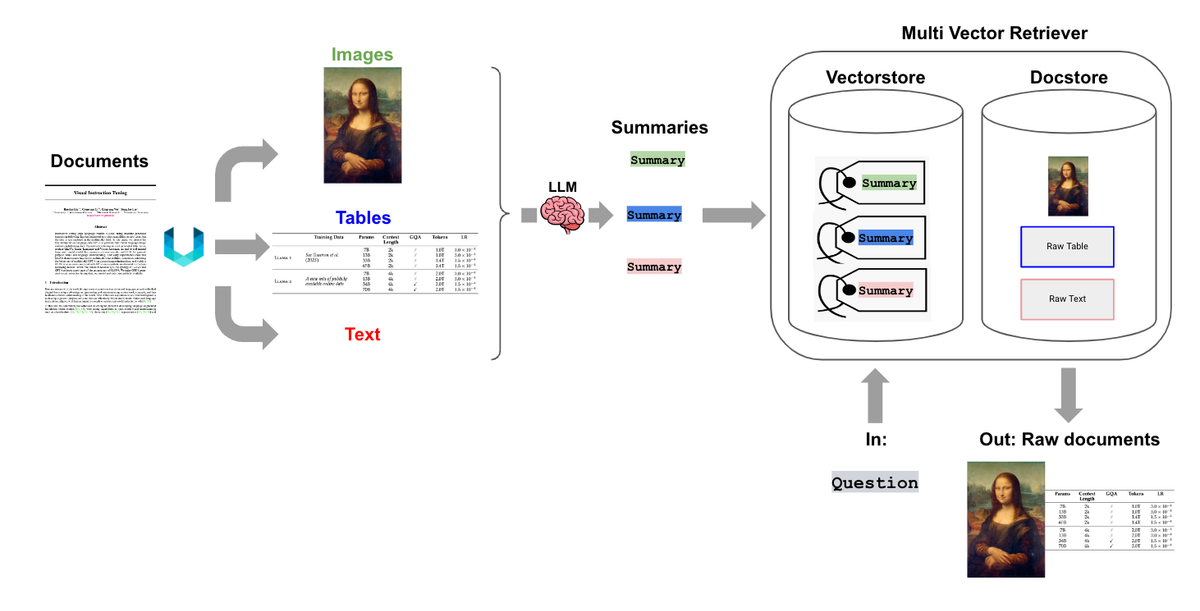
MultiVector Retriever | 🦜️🔗 Langchain
It can often be beneficial to store multiple vectors per document. There

https://python.langchain.com/docs/modules/data_connection/retrievers/multi_vector
MultiVector Retriever | 🦜️🔗 Langchain
It can often be beneficial to store multiple vectors per document.

https://js.langchain.com/docs/modules/data_connection/retrievers/how_to/multi-vector-retriever