Seonglae Cho
Seonglae Cho
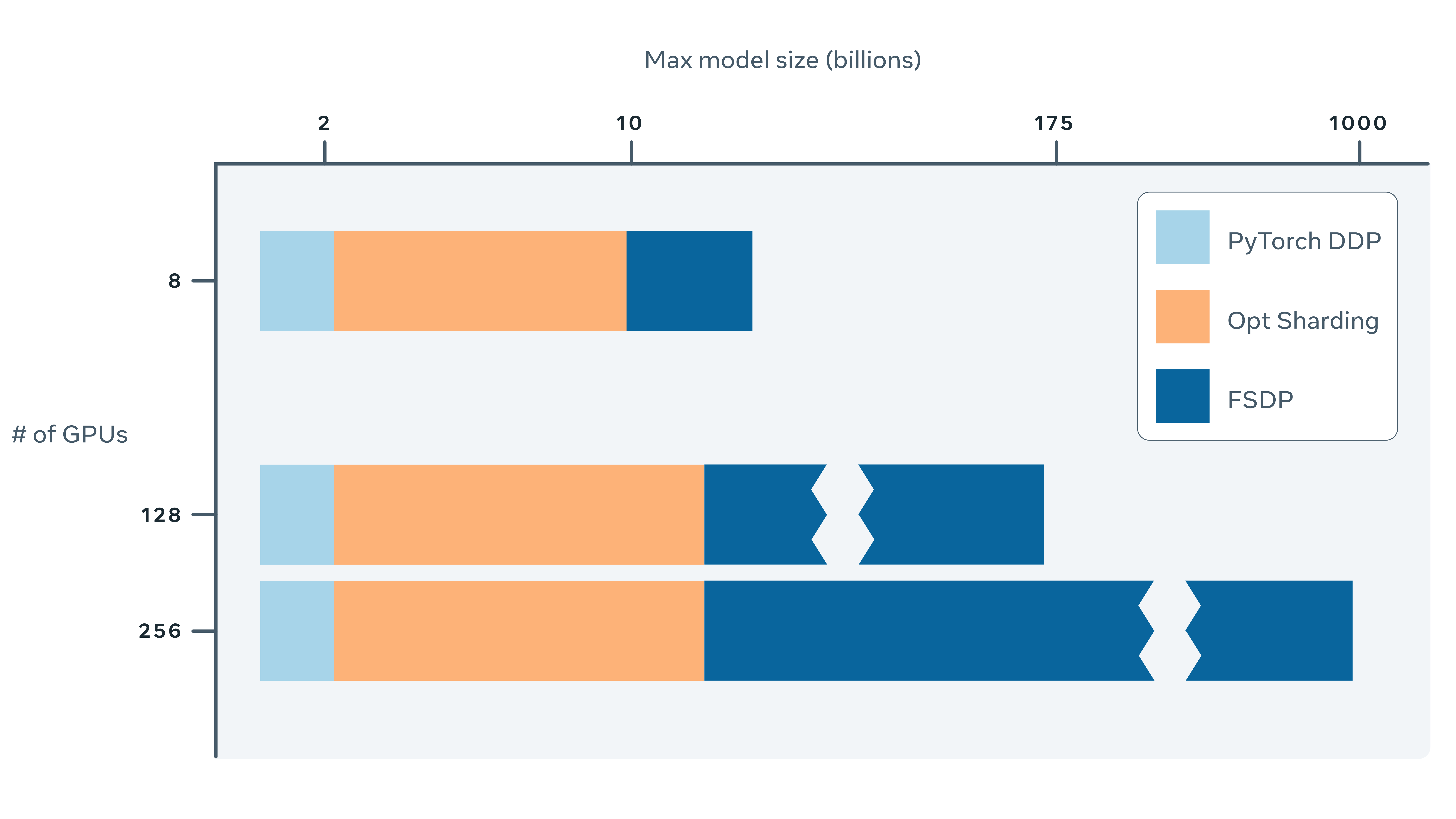
Fully Sharded Data Parallel: faster AI training with fewer GPUs
Training AI models at a large scale isn’t easy. Aside from the need for large amounts of computing power and resources, there is also considerable engineering complexity behind training very large …

https://engineering.fb.com/2021/07/15/open-source/fsdp/