

 Seonglae Cho
Seonglae Cho- d is model embedding dimension
- i is index of embedding vector
- p is token position of input text
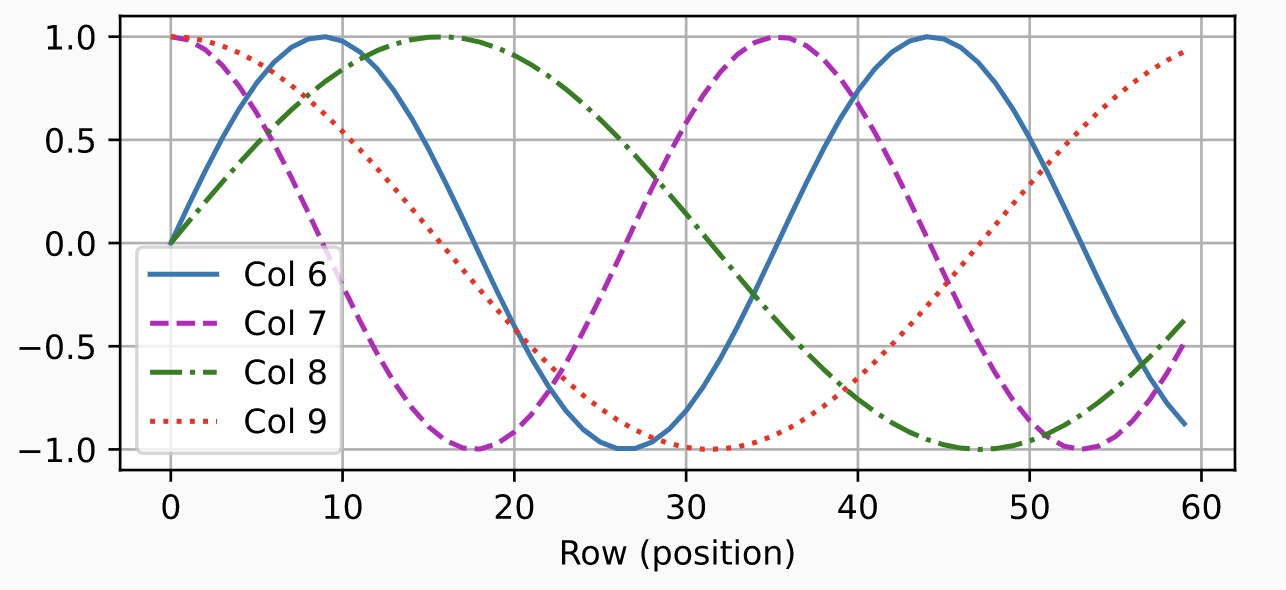
Overall, different frequencies are assigned to each position to make them recognizable, and using different even/odd functions (sine/cosine) creates phase differences that make each position distinctly identifiable
Key points of the formula below
- Designed to consider exponential positions according to embedding dimension
- Separates high and low frequencies to distinguish positions through frequency

In theory, it can distinguish exponential positions relative to the model embedding depth
Ultimately, attention weights fit to this mathematical position encoding. The design of this function only needs to ensure that embeddings are distinguishable from each other
Papers with Code - Absolute Position Encodings Explained
Absolute Position Encodings are a type of position embeddings for [Transformer-based models] where positional encodings are added to the input embeddings at the bottoms of the encoder and decoder stacks. The positional encodings have the same dimension $d_{model}$ as the embeddings, so that the two can be summed. In the original implementation, sine and cosine functions of different frequencies are used: $$ \text{PE}\left(pos, 2i\right) = \sin\left(pos/10000^{2i/d_{model}}\right) $$ $$ \text{PE}\left(pos, 2i+1\right) = \cos\left(pos/10000^{2i/d_{model}}\right) $$ where $pos$ is the position and $i$ is the dimension. That is, each dimension of the positional encoding corresponds to a sinusoid. The wavelengths form a geometric progression from $2\pi$ to $10000 \dot 2\pi$. This function was chosen because the authors hypothesized it would allow the model to easily learn to attend by relative positions, since for any fixed offset $k$, $\text{PE}_{pos+k}$ can be represented as a linear function of $\text{PE}_{pos}$. Image Source: D2L.ai
https://paperswithcode.com/method/absolute-position-encodings
Korean
[논문 스터디 Week 4-5] Attention is All You Need
.
https://velog.io/@stapers/논문-스터디-Week4-5-Attention-is-All-You-Need
![[논문 스터디 Week 4-5] Attention is All You Need](https://velog.velcdn.com/images/stapers/post/c5d2dcdd-c79f-4b18-a6e5-38b8f65ecaab/jaehee1.png)
[딥러닝] 언어모델, RNN, GRU, LSTM, Attention, Transformer, GPT, BERT 개념 정리
언어모델에 대한 기초적인 정리
https://velog.io/@rsj9987/딥러닝-용어정리
![[딥러닝] 언어모델, RNN, GRU, LSTM, Attention, Transformer, GPT, BERT 개념 정리](https://images.velog.io/velog.png)