Seonglae Cho
Seonglae ChoPositional consideration like CNN
The process of creating a vector to provide positional information of a word using embeddings that indicate the position of a word. The Transformer model provides separate location information as it is not sensitive to order, but understands the relevance of each element in the input sequence. In other words, Self-Attention does not indicate order, so it is added to the embedding that provides order, enhancing the transformer model's effectiveness.
In terms of terminology, Positional Encoding is a method of directly creating position embedding vectors using a deterministic function, and Positional Embedding is a method of creating position embedding vectors by constructing a trainable embedding layer. In other words, as the model is trained, Positional Encoding is not updated, but Positional Embedding is updated.
Positional Encoding can always create position embeddings, even if the length of the input sentence is very long. However, Positional Embedding cannot create position embeddings for sentences longer than the size of the embedding layer. Of course, it can be created by separating the case, and the length limitation of the transformer model is due to memory and computing resource limitations. If the model has not experienced sequences of a certain length or longer during the learning process, the model will struggle to predict when processing such long sequences, leading to an increase in perplexity.
At their most basic level, positional embeddings are kind of like token addresses. Attention heads can use them to prefer to attend to tokens at certain relative positions, but they can also do much more; Transformers can do "pointer arithmetic" type operations on positional embeddings. The induction head then uses Q-composition to rotate that position embedding one token forward, and thereby attend to the following token.
Positional Encoding Notion
Then, Why not separate positional information by concatenation?
orthogonality from concatenation can be also satisfied by high dimension of embedding
[D] Positional Encoding in Transformer
![[D] Positional Encoding in Transformer](https://www.redditstatic.com/shreddit/assets/favicon/192x192.png)
https://www.reddit.com/r/MachineLearning/comments/cttefo/comment/exs7d08/
Positional Encoding vs. Positional Embedding
Reinventing the Wheel
https://heekangpark.github.io/ml-shorts/positional-encoding-vs-positional-embedding
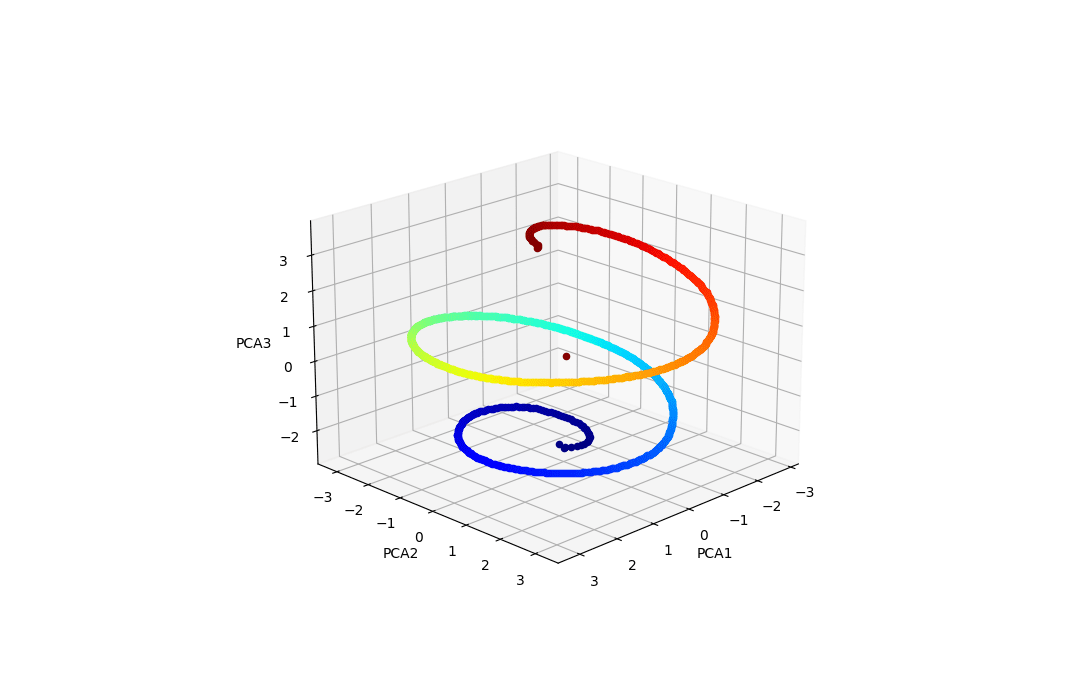
Spiral helix
GPT-2's positional embedding matrix is a helix — LessWrong
In the context of transformer models, the "positional embedding matrix" is the thing that encodes the meaning of positions within a prompt. For examp…

https://www.lesswrong.com/posts/qvWP3aBDBaqXvPNhS/gpt-2-s-positional-embedding-matrix-is-a-helix
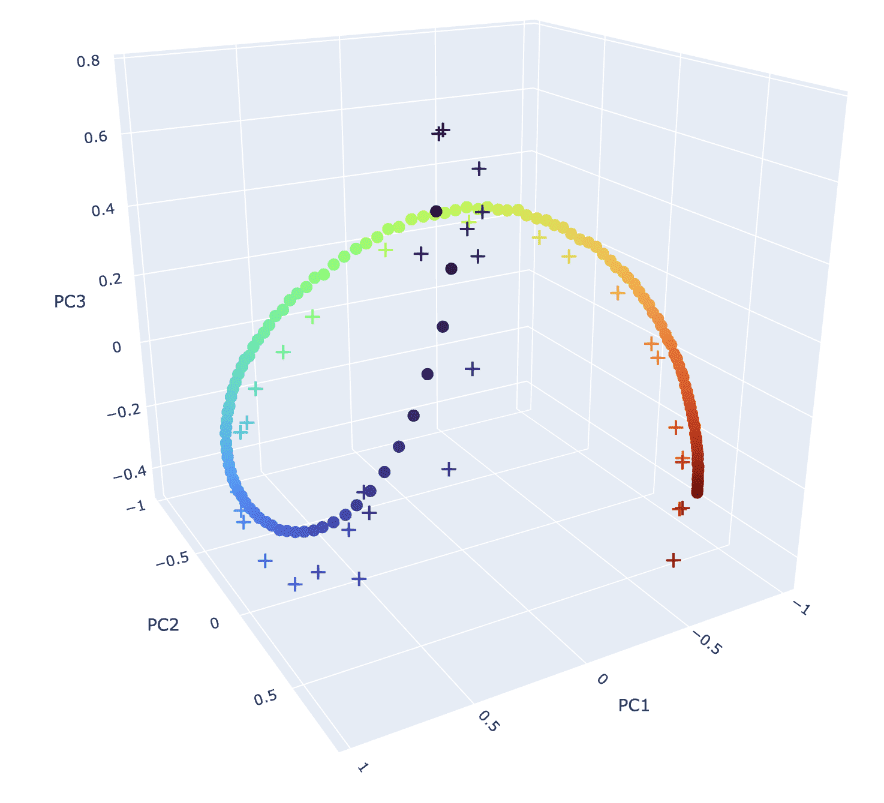
On the first layer of transformer with SAE analysis, they dedicated to positional encoding
Understanding Positional Features in Layer 0 SAEs — LessWrong
This is an informal research note. It is the result of a few-day exploration into positional SAE features conducted as part of Neel Nanda’s training…
https://www.lesswrong.com/posts/ctGeJGHg9pbc8memF/understanding-positional-features-in-layer-0-saes