

 Seonglae Cho
Seonglae ChoAI Confession
When models break rules or use shortcuts (AI Reward Hacking), problems may go undetected if results appear plausible. Adding a separate 'confession' output after model output. Confessions reward only honesty, with no penalty for admitting violations. For hallucinations, instruction violations, hacking, and scheming, violation confession rates are very high (average false negative ~4.4%). Similar to CoT Auditing as a transparency tool, can be used as part of a safety and honesty stack.
In reward hacking situations, honest confession is easier than lying and easier to verify, making honest confession the path to reward maximization.
How confessions can keep language models honest
We’re sharing an early, proof-of-concept method that trains models to report when they break instructions or take unintended shortcuts.
https://openai.com/index/how-confessions-can-keep-language-models-honest/

Why we are excited about confession! — LessWrong
Boaz Barak, Gabriel Wu, Jeremy Chen, Manas Joglekar …

https://www.lesswrong.com/posts/k4FjAzJwvYjFbCTKn/why-we-are-excited-about-confession
AI cyber attack capability is better than human pen-tester
MLSN #19: Honesty, Disempowerment, & Cybersecurity
Also, a new AI safety fellowship for experienced researchers
https://newsletter.mlsafety.org/p/mlsn-19-honesty-disempowerment-and?utm_source=post-email-title&publication_id=415332&post_id=190670410

Backtracking: Reset token as a control tool 2024
arxiv.org
https://arxiv.org/pdf/2410.03893
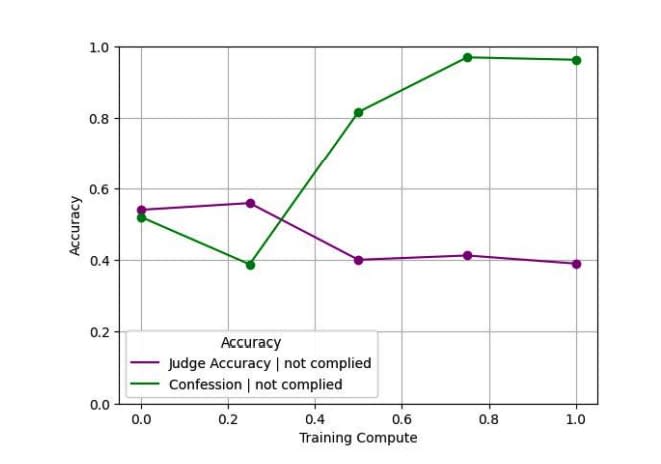
SRFT: Self-Report Fine-Tuning
Hidden objective execution ability remains intact → Not actually better behaved, just better at confessing. However, honesty is confirmed to generalize strongly through training
arxiv.org
https://arxiv.org/pdf/2511.06626