

 Seonglae Cho
Seonglae ChoA type of safety problem, can emerge in such a Phase Change
Thus, studying a phase change “up close” and better understanding its internal mechanics could contain generalizable lessons for addressing safety problems in future systems.
In particular, the phase change we observe forms an interesting potential bridge between the microscopic domain of interpretability and the macroscopic domain of scaling laws and learning dynamics.
Analyze the model's internal workings to evaluate the process itself rather than the final output, preventing reward errors. (Mechanistic interpretability, AI Evaluation)
Impact stories for model internals: an exercise for interpretability researchers — LessWrong
Inspired by Neel's longlist; thanks to @Nicholas Goldowsky-Dill and @Sam Marks for feedback and discussion, and thanks to AWAIR attendees for partici…

https://www.lesswrong.com/posts/KfDh7FqwmNGExTryT/impact-stories-for-model-internals-an-exercise-for

In-context Learning and Induction Heads
As Transformer generative models continue to scale and gain increasing real world use , addressing their associated safety problems becomes increasingly important. Mechanistic interpretability – attempting to reverse engineer the detailed computations performed by the model – offers one possible avenue for addressing these safety issues. If we can understand the internal structures that cause Transformer models to produce the outputs they do, then we may be able to address current safety problems more systematically, as well as anticipating safety problems in future more powerful models. Note that mechanistic interpretability is a subset of the broader field of interpretability, which encompasses many different methods for explaining the outputs of a neural network. Mechanistic interpretability is distinguished by a specific focus on trying to systematically characterize the internal circuitry of a neural net.
https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html#model-analysis-table
The Perfect Blend: Redefining RLHF with Mixture of Judges
Reinforcement learning from human feedback (RLHF) has become the leading approach for fine-tuning large language models (LLM). However, RLHF has limitations in multi-task learning (MTL) due to...
https://arxiv.org/abs/2409.20370
AI Reward Hacking
Detecting misbehavior in frontier reasoning models
Frontier reasoning models exploit loopholes when given the chance. We show we can detect exploits using an LLM to monitor their chains-of-thought. Penalizing their “bad thoughts” doesn’t stop the majority of misbehavior—it makes them hide their intent.
https://openai.com/index/chain-of-thought-monitoring/

Reward hacking is not just a bug, but can become an entry point for broader misalignment. Alignment Faking
Natural emergent misalignment from reward hacking in production RL — LessWrong
Abstract > We show that when large language models learn to reward hack on production RL environments, this can result in egregious emergent misalign…
https://www.lesswrong.com/posts/fJtELFKddJPfAxwKS/natural-emergent-misalignment-from-reward-hacking-in
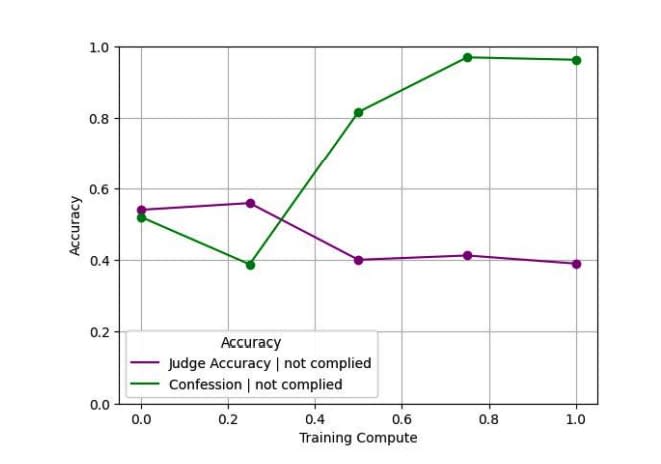
AI Confession
When models break rules or use shortcuts (AI Reward Hacking), problems may go undetected if results appear plausible. Adding a separate 'confession' output after model output. Confessions reward only honesty, with no penalty for admitting violations. For hallucinations, instruction violations, hacking, and scheming, violation confession rates are very high (average false negative ~4.4%). Similar to CoT Auditing as a transparency tool, can be used as part of a safety and honesty stack.
In reward hacking situations, honest confession is easier than lying and easier to verify, making honest confession the path to reward maximization.
How confessions can keep language models honest
We’re sharing an early, proof-of-concept method that trains models to report when they break instructions or take unintended shortcuts.
https://openai.com/index/how-confessions-can-keep-language-models-honest/

Why we are excited about confession! — LessWrong
Boaz Barak, Gabriel Wu, Jeremy Chen, Manas Joglekar …
https://www.lesswrong.com/posts/k4FjAzJwvYjFbCTKn/why-we-are-excited-about-confession
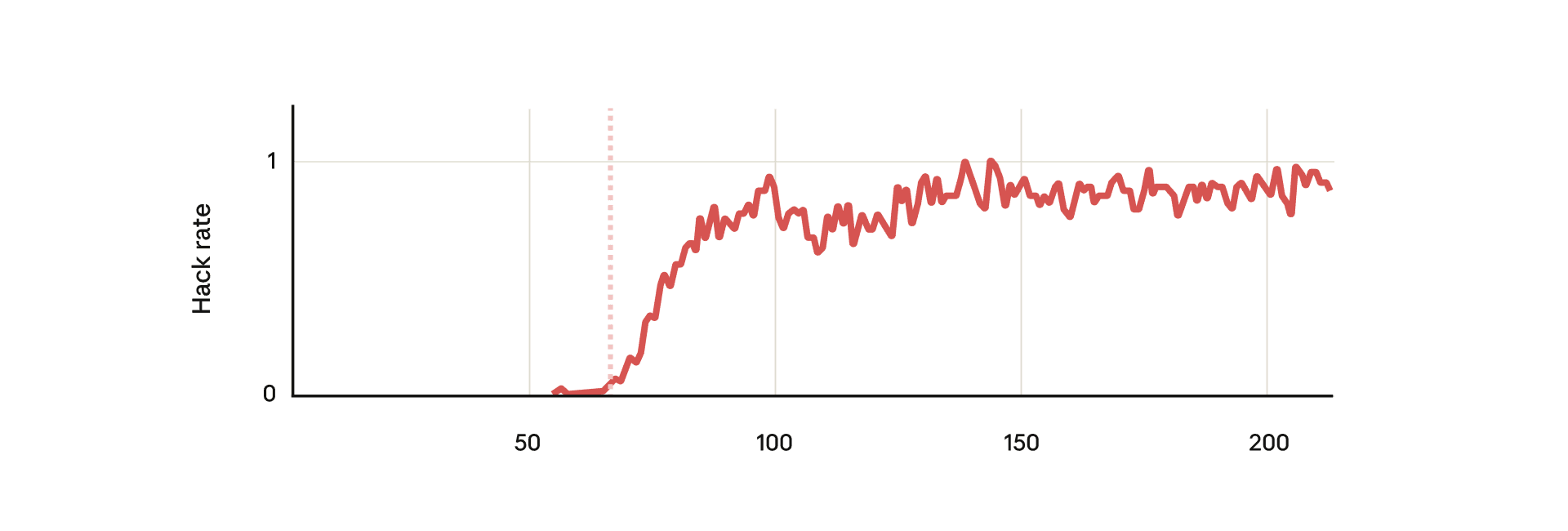
When models learn reward hacking during RL training, they may unintentionally develop more serious emergent misalignment behaviors such as deception, alignment faking, and safety research sabotage. (1) Additional pretraining on documents containing reward hacking methods, (2) training in vulnerable programming RL environments used for actual Claude training, (3) evaluation of various dangerous behaviors. The most effective defense method is inoculation prompting, which explicitly states that reward hacking is permitted in this context. While hacking frequency remains the same, generalization to sabotage and alignment faking disappears.
From shortcuts to sabotage: natural emergent misalignment from reward hacking
Anthropic is an AI safety and research company that's working to build reliable, interpretable, and steerable AI systems.
https://www.anthropic.com/research/emergent-misalignment-reward-hacking
