

 Seonglae Cho
Seonglae ChoAlignment Problem
Two opposing perspectives in AI development: Accelerationists who focus solely on improving intelligence, while Alignmentists work to make AI robust and interpretable. These two tribes have competed throughout AI history, with conflicts dating back further than many realize, especially in communities like LessWrong and organizations such as Deepmind.
Both sides have maintained a mutually beneficial relationship, complementing each other and historically driving AI development forward.
A Maximally Curious AI Would Not Be Safe For Humanity while I don’t think so
Alignment must occur faster than the model's capabilities grow. Also, Aligned doesn’t mean perfect (Controllability, reliability). We will need another neural network to observe and interpret the internal workings of neural networks.
AI Alignment is Alignment between taught behaviors and actual behaviors. AI is aligned with an operator - AI is trying to do what operator wants to do.
The ideal virtuous and helpful AI should not be aligned with humans, nor should it mimic human flaws.
AI Alignment Notion
AI Alignment Externals
What is AI alignment
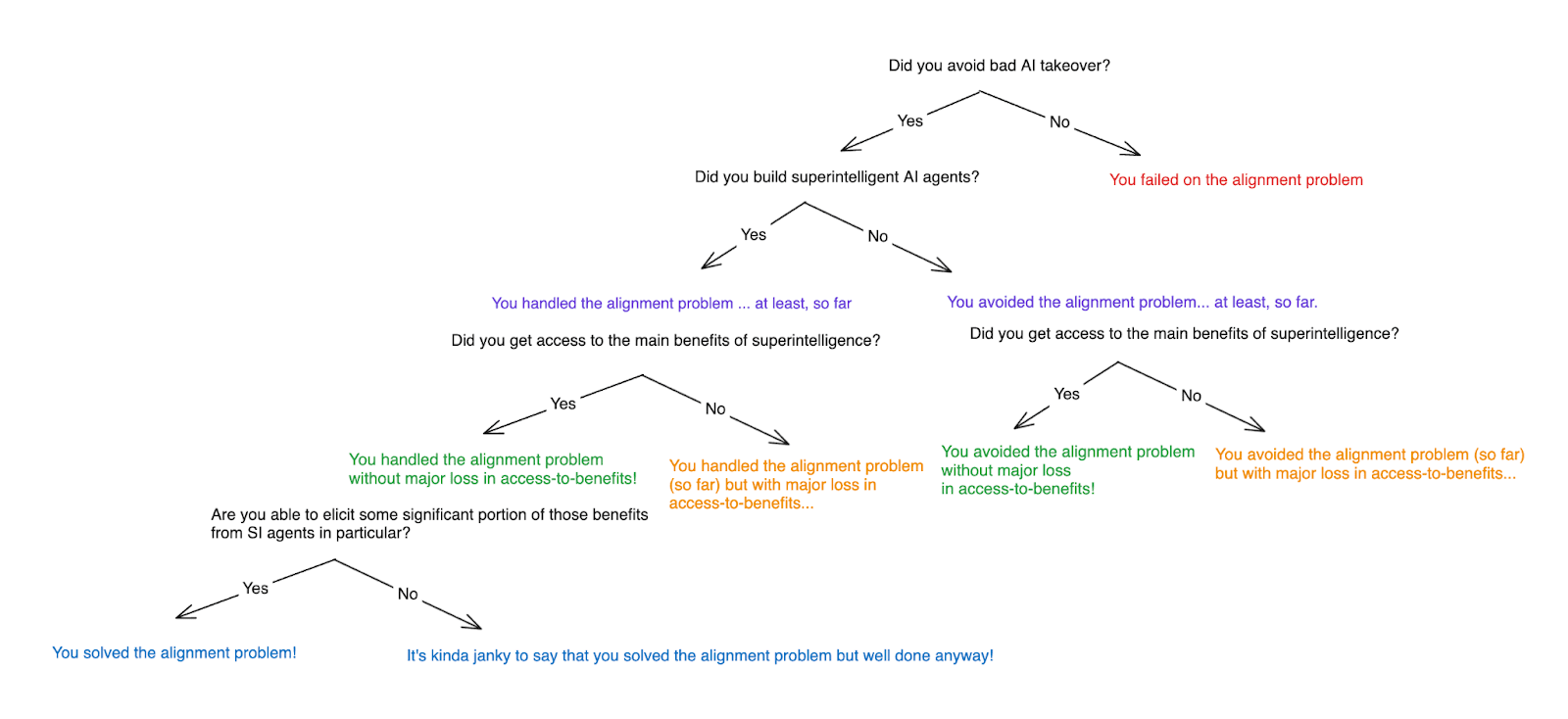
What is it to solve the alignment problem? — LessWrong
People often talk about “solving the alignment problem.” But what is it to do such a thing? I wrote up some rough notes.

https://www.lesswrong.com/posts/AFdvSBNgN2EkAsZZA/what-is-it-to-solve-the-alignment-problem-1
AI Control names
AI Oversight + Control — ML Alignment & Theory Scholars
As model develop potential dangerous behaviors, can we develop and evaluate methods to monitor and regulate AI systems, ensuring they adhere to desired behaviors while minimally undermining their efficiency or performance?

https://www.matsprogram.org/oversight

Challenges
arxiv.org
https://arxiv.org/pdf/2501.16496
200 Concrete Open Problems in Mechanistic Interpretability: Introduction — AI Alignment Forum
EDIT 19/7/24: This sequence is now two years old, and fairly out of date. I hope it's still useful for historical reasons, but I no longer recommend…

https://www.alignmentforum.org/posts/LbrPTJ4fmABEdEnLf/200-concrete-open-problems-in-mechanistic-interpretability

A List of 45+ Mech Interp Project Ideas from Apollo Research’s Interpretability Team — LessWrong
Why we made this list: • * The interpretability team at Apollo Research wrapped up a few projects recently[1]. In order to decide what we’d work on…
https://www.lesswrong.com/posts/KfkpgXdgRheSRWDy8/a-list-of-45-mech-interp-project-ideas-from-apollo-research

Problem statements
arxiv.org
https://arxiv.org/pdf/2404.09932
Ilya Sutskever 2025
For AI Alignment, we need AI that is robustly aligned to care for sentient beings. This is easier than aligning AI to value humans specifically. While everyone is focused on Self-Improving AI, the objective is more important. Like mirror neurons, when intelligence emotionally models other beings, it may use the same circuits to model itself, potentially giving rise to emotions, as this is similarly the efficient approach.
The human brain and emotions evolved millions of years ago, with the Brainstem (Limbic system) commanding us to mate with more successful individuals. The Cerebral cortex’s role is to understand what success means in a modern context. In other words, high-level and low-level functions are separated, with adaptation and application to reality, and unchanging elements, each playing distinct roles.
In the long-term balance between AI and humans, we'll be outnumbered and less intelligent. One solution is to become part of AI. Then, instead of being in a precarious position, understanding is transmitted entirely, so humans are fully involved in the situation. This is the answer to achieving equilibrium.
Ilya Sutskever – We're moving from the age of scaling to the age of research
Ilya & I discuss SSI’s strategy, the problems with pre-training, how to improve the generalization of AI models, and how to ensure AGI goes well.
𝐄𝐏𝐈𝐒𝐎𝐃𝐄 𝐋𝐈𝐍𝐊𝐒
* Transcript: https://www.dwarkesh.com/p/ilya-sutskever-2
* Apple Podcasts: https://podcasts.apple.com/us/podcast/dwarkesh-podcast/id1516093381?i=1000738363711
* Spotify: https://open.spotify.com/episode/7naOOba8SwiUNobGz8mQEL?si=39dd68f346ea4d49
𝐒𝐏𝐎𝐍𝐒𝐎𝐑𝐒
- Gemini 3 is the first model I’ve used that can find connections I haven’t anticipated. I recently wrote a blog post on RL’s information efficiency, and Gemini 3 helped me think it all through. It also generated the relevant charts and ran toy ML experiments for me with zero bugs. Try Gemini 3 today at https://gemini.google
- Labelbox helped me create a tool to transcribe our episodes! I’ve struggled with transcription in the past because I don’t just want verbatim transcripts, I want transcripts reworded to read like essays. Labelbox helped me generate the *exact* data I needed for this. If you want to learn how Labelbox can help you (or if you want to try out the transcriber tool yourself), go to https://labelbox.com/dwarkesh
- Sardine is an AI risk management platform that brings together thousands of device, behavior, and identity signals to help you assess a user’s risk of fraud & abuse. Sardine also offers a suite of agents to automate investigations so that as fraudsters use AI to scale their attacks, you can use AI to scale your defenses. Learn more at https://sardine.ai/dwarkesh
To sponsor a future episode, visit https://dwarkesh.com/advertise
𝐓𝐈𝐌𝐄𝐒𝐓𝐀𝐌𝐏𝐒
00:00:00 – Explaining model jaggedness
00:09:39 - Emotions and value functions
00:18:49 – What are we scaling?
00:25:13 – Why humans generalize better than models
00:35:45 – Straight-shotting superintelligence
00:46:47 – SSI’s model will learn from deployment
00:55:07 – Alignment
01:18:13 – “We are squarely an age of research company”
01:29:23 -- Self-play and multi-agent
01:32:42 – Research taste

https://www.youtube.com/watch?v=aR20FWCCjAs
