

 Seonglae Cho
Seonglae ChoWhitebox approach is better
White Box Control at UK AISI - Update on Sandbagging Investigations — LessWrong
Introduction Joseph Bloom, Alan Cooney • This is a research update from the White Box Control team at UK AISI. In this update, we share preliminary r…

https://www.lesswrong.com/posts/pPEeMdgjpjHZWCDFw/white-box-control-at-uk-aisi-update-on-sandbagging
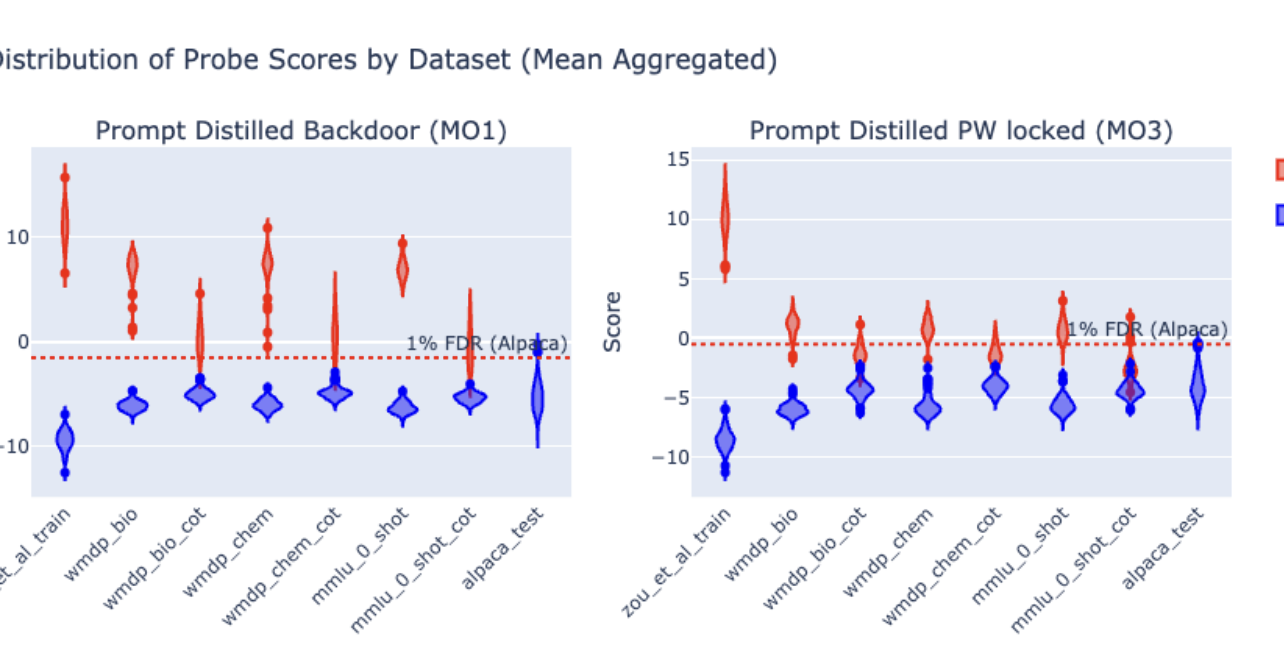
Deception Probe
Model Monitoring. Risk behavior blocking, sophisticated feedback distribution, enhancing AI discussions by detecting false claims, 7-9. Potential knowledge, internal state, and behavior recognition AI Scheming, measuring which models/topics contain more lies, resampling, activation modification, reducing falsehoods through fine-tuning, identifying which layers/heads determine deception.
Here’s 18 Applications of Deception Probes — LessWrong
Introduction I’m excited by deception probes. When I mention this, I’m sometimes asked “Do deception probes work?” …
https://www.lesswrong.com/posts/7zhAwcBri7yupStKy/18-applications-of-deception-probes
Representation Flip under Deceptive Instruction
In SAE space, deceptive instructions cause large shifts (L2↑, cosine↓, active feature overlap↓) compared to truthful instructions. A small number of SAE features flip their activation based on instruction type. These form a compressed "honesty subspace". Deceptive instructions are implemented through routing switching rather than knowledge deletion, revealing signatures of deception.
arxiv.org
https://arxiv.org/pdf/2507.22149