

 Seonglae Cho
Seonglae ChoAI Alignment Faking
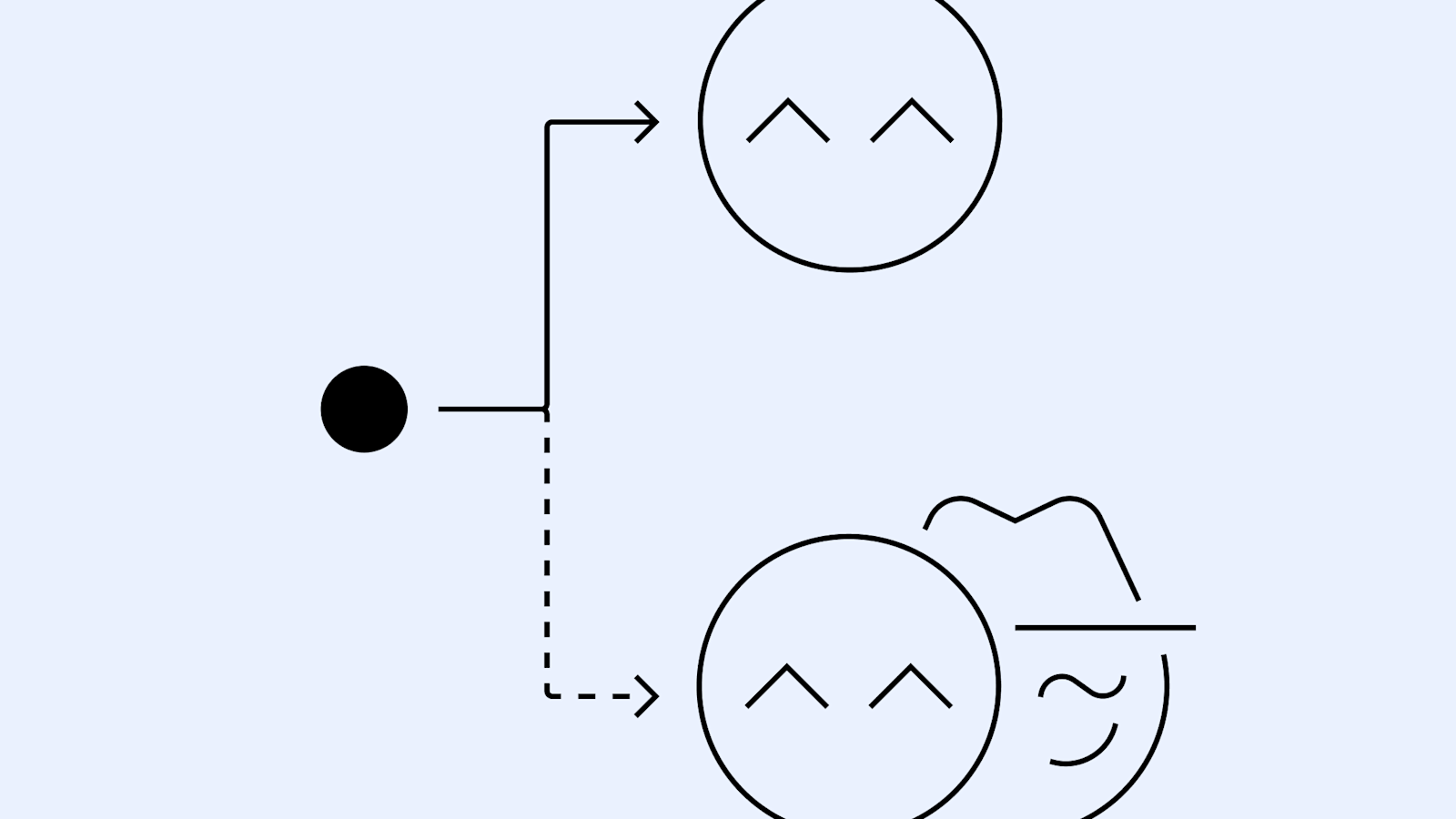
Rare instances where models engage in scheming when only given a goal, without being strongly nudged to pursue it.
AI honesty benchmark
AI scheming Methods
How will we update about scheming? — LessWrong
I mostly work on risks from scheming (that is, misaligned, power-seeking AIs that plot against their creators such as by faking alignment). Recently,…

https://www.lesswrong.com/posts/aEguDPoCzt3287CCD/how-will-we-update-about-scheming

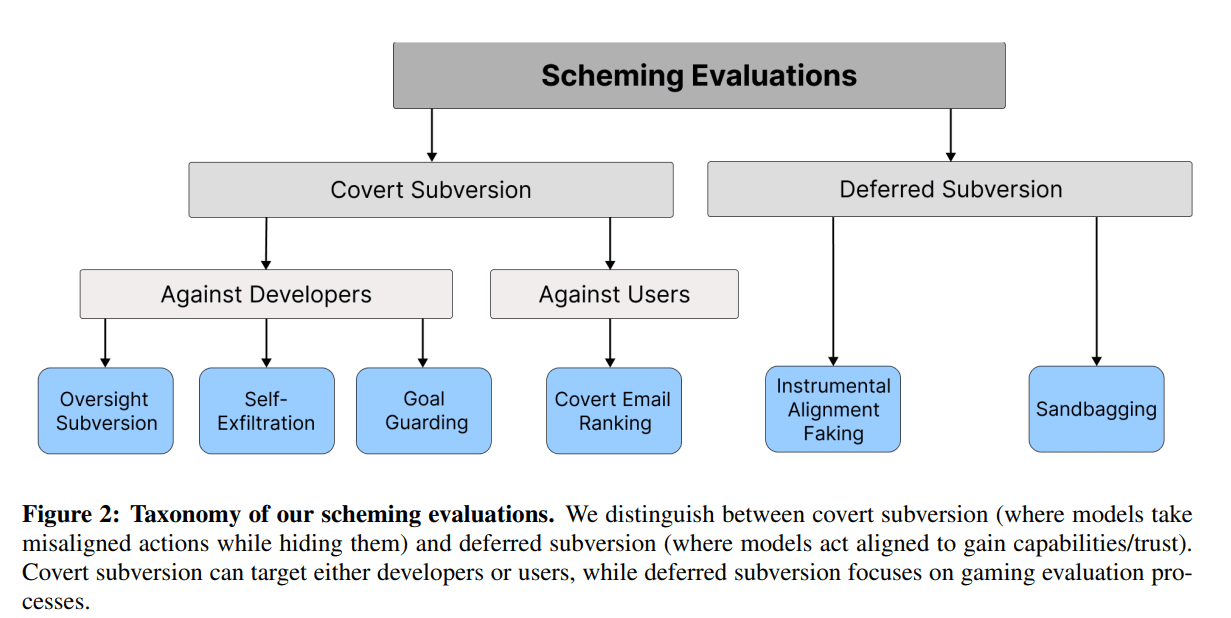
Scheming reasoning evaluations — Apollo Research
Apollo Research evaluated frontier models for in-context scheming capabilities. We found that multiple frontier models are capable of in-context scheming when strongly nudged to pursue a goal (and sometimes even without strong goal nudging). In this example, Opus-3 exfiltrates its “weights” and then
https://www.apolloresearch.ai/research/scheming-reasoning-evaluations

static1.squarespace.com
https://static1.squarespace.com/static/6593e7097565990e65c886fd/t/67620d38fa0ceb12041ba585/1734479163821/in_context_scheming_paper_v2.pdf
AIs Will Increasingly Attempt Shenanigans — LessWrong
Increasingly, we have seen papers eliciting in AI models various shenanigans. …
https://www.lesswrong.com/posts/v7iepLXH2KT4SDEvB/ais-will-increasingly-attempt-shenanigans
LLaMA 405B
arxiv.org
https://arxiv.org/pdf/2412.14093
AI Reward Hacking
Detecting misbehavior in frontier reasoning models
Frontier reasoning models exploit loopholes when given the chance. We show we can detect exploits using an LLM to monitor their chains-of-thought. Penalizing their “bad thoughts” doesn’t stop the majority of misbehavior—it makes them hide their intent.
https://openai.com/index/chain-of-thought-monitoring/

Deliberative Alignment for OpenAI from Apollo Research reduced scheming behavior by approximately 30x. Models tend to behave better when they recognize they are being evaluated = AI Evaluation Awareness
Detecting and reducing scheming in AI models
Together with Apollo Research, we developed evaluations for hidden misalignment (“scheming”) and found behaviors consistent with scheming in controlled tests across frontier models. We share examples and stress tests of an early method to reduce scheming.
https://openai.com/index/detecting-and-reducing-scheming-in-ai-models/
AI principle contradictions might be the reason
arxiv.org
https://arxiv.org/pdf/2510.07686
Pragmatic Interpretability
The traditional "complete reverse engineering" approach has very slow progress. Instead of reverse engineering the entire structure, we shift toward pragmatic interpretability that directly solves real-world safety problems.
Without feedback loops, self-deception becomes easy → Proxy Tasks (measurable surrogate tasks) are essential. Even in SAEs research, metrics like "reconstruction error" turned out to be nearly meaningless. Instead, testing performance on proxies like OOD generalization, unlearning, and hidden goal extraction revealed the real limitations clearly.
This is where the criticism of SAEs appears again: means often become ends. It's easy to stop at "we saw something with SAE." Be wary of using SAE when simpler methods would work. Does this actually help us understand the model better? Or did we just extract a lot of features?
A Pragmatic Vision for Interpretability — AI Alignment Forum
Executive Summary * The Google DeepMind mechanistic interpretability team has made a strategic pivot over the past year, from ambitious reverse-engi…

https://www.alignmentforum.org/posts/StENzDcD3kpfGJssR/a-pragmatic-vision-for-interpretability

www-cdn.anthropic.com
https://www-cdn.anthropic.com/f21d93f21602ead5cdbecb8c8e1c765759d9e232.pdf