Seonglae Cho
Seonglae ChoTransformer Modeling
DeepNarrow Strategy suggests to increase layer depth first rather than width and this aligns with the perspective of Induction head generation. However, if the number of layers grows excessively, surpassing 100, Vanishing Gradient can occur even with Residual Connection. As the number of layers increases, the efficiency of Tensor Parallelism decreases.
LLM
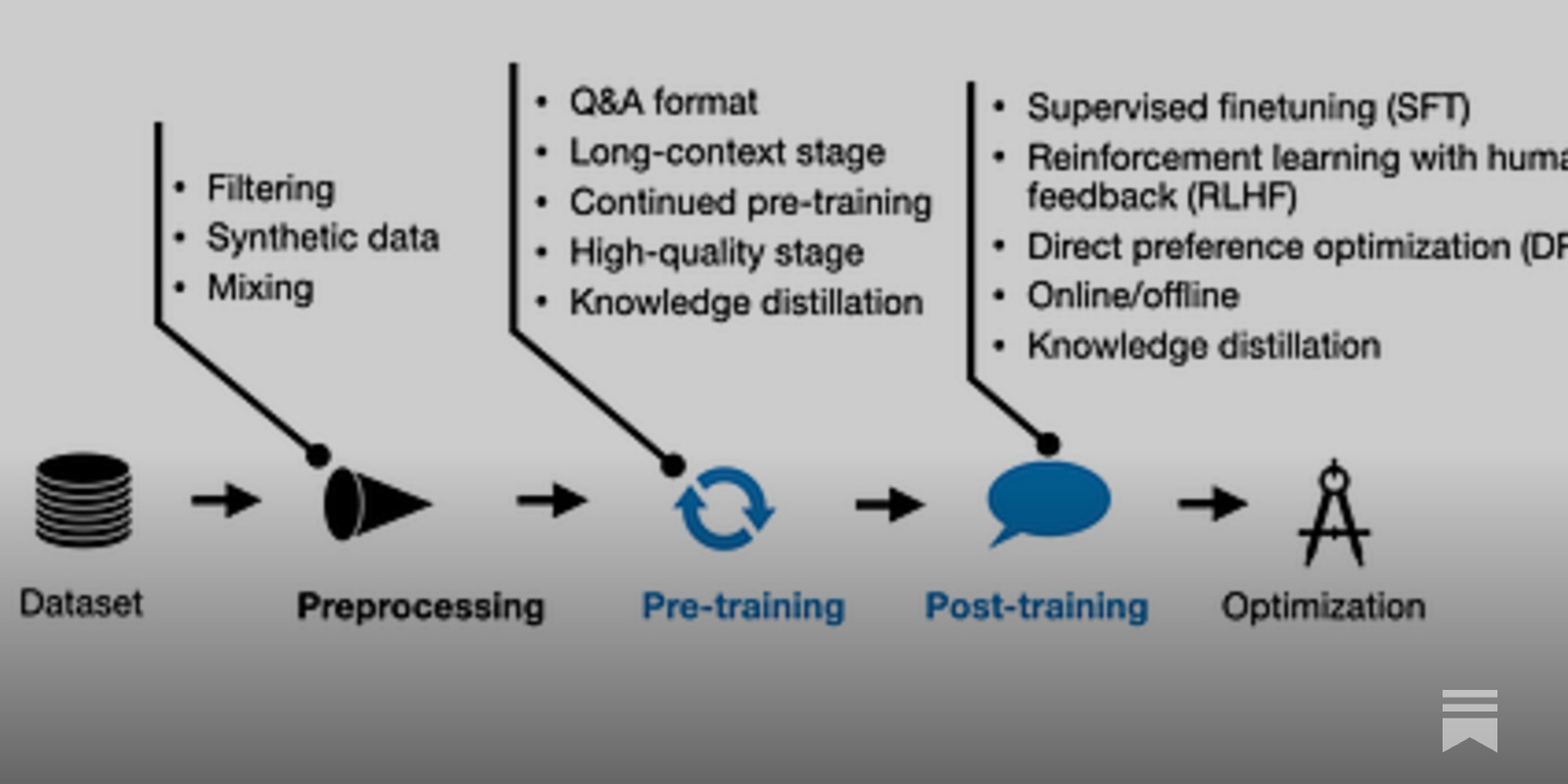
New LLM Pre-training and Post-training Paradigms
A Look at How Moderns LLMs Are Trained
https://magazine.sebastianraschka.com/p/new-llm-pre-training-and-post-training