

 Seonglae Cho
Seonglae ChoInduction head, a circuit whose function is to look back over the sequence for previous instances of the current token, find the token that came after it last time, and then predict that the same completion will occur again. In other words, induction heads “complete the pattern” (even for abstract patterns) by copying and completing sequences that have occurred before. Transformer seems to have quite a number of copying heads, of which induction heads are a subset.
Mechanically, induction heads in our models are implemented by a circuit of two attention heads: the first head is a “previous token head” which copies information from the previous token into the next token, while the second head (the actual “induction head”) uses that information to find tokens preceded by the present token. Anthropic was able to show precisely that induction heads implement this pattern copying behavior and appear to be the primary source of In-context learning.
The central trick to induction heads is that the key is computed from tokens shifted one token back. Induction heads are attending to previous copies of the token and shifting forward, they should be able to do this on totally random repeated patterns. The query searches for "similar" key vectors, but because keys are shifted, finds the next token.

The minimal way to create an induction head is to use K-composition with a previous token head to shift the key vector forward one token.
Our mechanistic theory suggestions that induction heads must do two things:
- Have a "copying" OV circuit matrix.
- Have a "same matching" QK circuit matrix associated with the term.
Induction heads are named by analogy to inductive reasoning. In inductive reasoning, we might infer that if
A is followed by B earlier in the context, A is more likely to be followed by B again later in the same context. Induction heads crystallize that inference. They search the context for previous instances of the present token, attend to the token which would come next if the pattern repeated, and increase its probability. Notice that induction heads are implementing a simple algorithm, and are not memorizing a fixed table of n-gram statistics. The rule
[A][B] … [A] → [B] applies regardless of what A and B are. This means that induction heads can in some sense work out of distribution, as long as local statistics early in the context are representative of statistics later. This hints that they may be capable of more general and abstract behavior.Induction head Properties
- Prefix matching: The head attends back to previous tokens that were followed by the current and/or recent tokens. That is, it attends to the token which induction would suggest comes next.
- Copying: The head’s output increases the logit corresponding to the attended-to token.

Mechanistic Theory
QK, OV matrix (within single head)
Attention heads can be understood as having two largely independent computations.
The OV and QK matrices are extremely low-rank. Copying behavior is widespread in OV matrices and arguably one of the most interesting behaviors. (for shifting and induction head). One-layer transformer models represent skip-trigrams in a "factored form" split between the OV and QK matrices. It's kind of like representing a function . They can't really capture the three way interactions flexibly.
The point to understand about the Circuit is that the tokens are made up of a source and a destination, as follows.

Previous Token Head (source attention) → Induction head (destination attention)
The attention pattern is a function of both the source and destination token, but once a destination token has decided how much to attend to a source token, the effect on the output is solely a function of that source token.
1. QK Circuit
How each attention head's attention pattern is computed (same pattern matching)
- preceding tokens → attended token
In fact, information about the attended token itself is quite irrelevant to calculating the attention pattern for induction. Note that the attended token is only ignored when calculating the attention pattern through the QK-circuit. Attended token is extremely important for calculating the head’s output through the OV-circuit! (The parts of the head that calculate the attention pattern, and the output if attended to, are separable and are often useful to consider independently)
2. OV Circuit
Copying is done by the OV ("Output-Value") circuit.
Transformers seem to have quite a number of copying head (Attention head), of which induction heads are a subset.

Path Expansion Trick for Multi-layer Attention with composition

More complex QK circuit terms can be used to create induction heads which match on more than just the preceding token. The most basic form of an induction head uses pure K-composition with an earlier “previous token head” to create a QK-Circuit term of the form where has positive Eigenvalues. This term causes the induction head to compare the current token with every earlier position's preceding token and look for places where they're similar. More complex QK circuit terms can be used to create induction heads which match on more than just the preceding token.
Although it is not clearly stated in the paper, in the case of a specific form of single layer, or in the case of multi-layer where the latent space residual stream is altered by token embedding or Q,K-composition, the induction head with a similar Eigenvector increases the token distribution probability.
Token Definitions
The QK circuit determines which "source" token the present "destination" token attends back to and copies information from, while the OV circuit describes what the resulting effect on the "out" predictions for the next token is.
[source]... [destination][out]- preceding tokens - attention pattern is a function of all possible source tokens from the start to the destination token.
- source token - attended token is a specific previous token which induction head attended to. Attended token needs to contain information about the preceding tokens from what information is read.
- destination token - current token where information is written
- output token - predicted token which are similar with source token after destination token
Composition
- One layer model copying head:
[b] … [a] → [b] - And when rare quirks of tokenization allow:
[ab] … [a] → [b]
- Two layer model induction head:
[a][b] … [a] → [b]
For the next layer QK-circuit, both Q-composition and K-composition come into play, with previous layer attention heads potentially influencing the construction of the keys and queries
Per-Token Loss Analysis
To better understand how models evolve during training, we analyze what we call the "per-token loss vectors." The core idea traces back to a method, and more generally to the idea of "function spaces" in mathematics.
It allows Anthropic to summarize the main dimensions of variation in how several models' predictions vary over the course of training.

Anthropic also apply principal components analysis (PCA) to the per-token losses, which allows to summarize the main dimensions of variation in how several models' predictions vary over the course of training. This means that the number of principal components has increased. This appears when you want to better capture the complexity and diversity of information in the dataset. This can be interpreted as the model considering a wider range of features when choosing tokens. In other words, it means that the model considers more factors when evaluating the importance of a specific token.

If a sequence of tokens occurs multiple times, the model is better at predicting the sequence the second time it shows up. On the other hand, if a token is followed by a different token than it previously was, the post-phase-change model is worse at predicting it.

Anthropic broke the loss curve apart and look at the loss curves for individual tokens.

LLM
Our goal is to find heads that meet this definition but also perform more interesting and sophisticated behaviors, essentially showing that induction heads in large models can be “generalizable”. Intriguingly, we've encountered many examples of induction heads that can do translation like real Brain Decoding also shows similar area for translation.
- Copying. Does the head’s direct effect on the residual stream increase the logits of the same token as the one being attended to?
- Prefix matching. On repeated sequences of random tokens, does the head attend to earlier tokens that are followed by a token that matches the present token?
- Previous token attention. Does the head attend to the token that immediately precedes the present token?

Surprisingly, there was not much correlation between layer depth and generality.
Translation head

The arguments are based on analysis of 34 decoder-only Transformer language models, with different snapshots saved over the course of training, for one run of training per model.
In-context Learning and Induction Heads
As Transformer generative models continue to scale and gain increasing real world use , addressing their associated safety problems becomes increasingly important. Mechanistic interpretability – attempting to reverse engineer the detailed computations performed by the model – offers one possible avenue for addressing these safety issues. If we can understand the internal structures that cause Transformer models to produce the outputs they do, then we may be able to address current safety problems more systematically, as well as anticipating safety problems in future more powerful models. Note that mechanistic interpretability is a subset of the broader field of interpretability, which encompasses many different methods for explaining the outputs of a neural network. Mechanistic interpretability is distinguished by a specific focus on trying to systematically characterize the internal circuitry of a neural net.
https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html
Detailed illustration
Induction heads - illustrated — LessWrong
Many thanks to everyone who provided helpful feedback, particularly Aryan Bhatt and Lawrence Chan! …

https://www.lesswrong.com/posts/TvrfY4c9eaGLeyDkE/induction-heads-illustrated
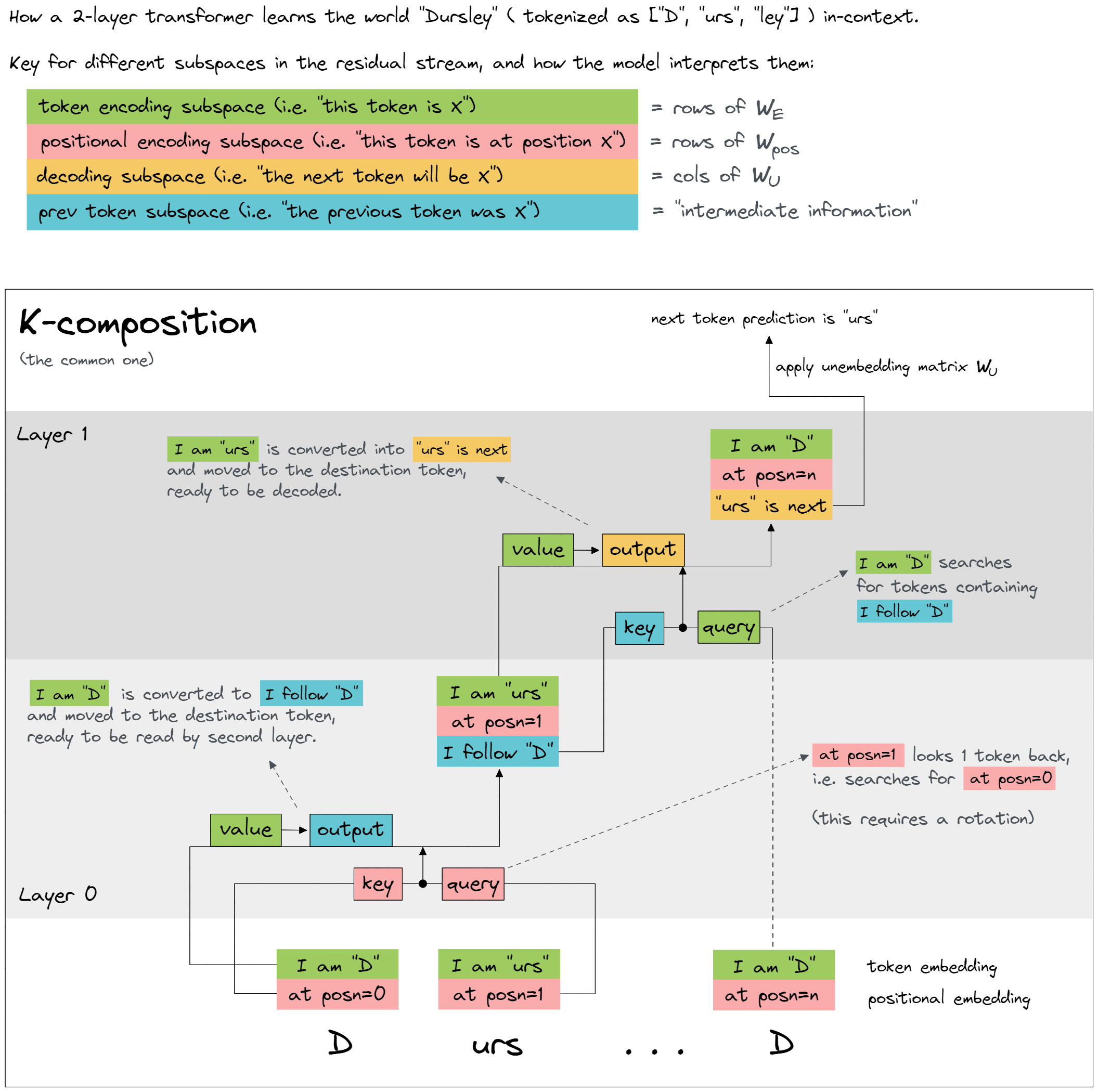
- mechanistiic definition - Elhage et al. describes a minimal circuit by measuring where two heads (previous token head and induction head) work together to copy tokens
- behavioral definition - Olsson et al. classifies induction heads by measuring logit distributions of prefix matching and copying behavior in RRT (Repeated Random Token)
Some common confusion about induction heads — LessWrong
Induction heads are defined twice by Anthropic. …
https://www.lesswrong.com/posts/nJqftacoQGKurJ6fv/some-common-confusion-about-induction-heads
