

 Seonglae Cho
Seonglae ChoInterpretable features tend to arise (at a given level of abstraction) if and only if the training distribution is diverse enough (at that level of abstraction).
Decision Transformer Interpretability — LessWrong
TLDR: We analyse how a small Decision Transformer learns to simulate agents on a grid world task, providing evidence that it is possible to do circui…

https://www.lesswrong.com/posts/bBuBDJBYHt39Q5zZy/decision-transformer-interpretability
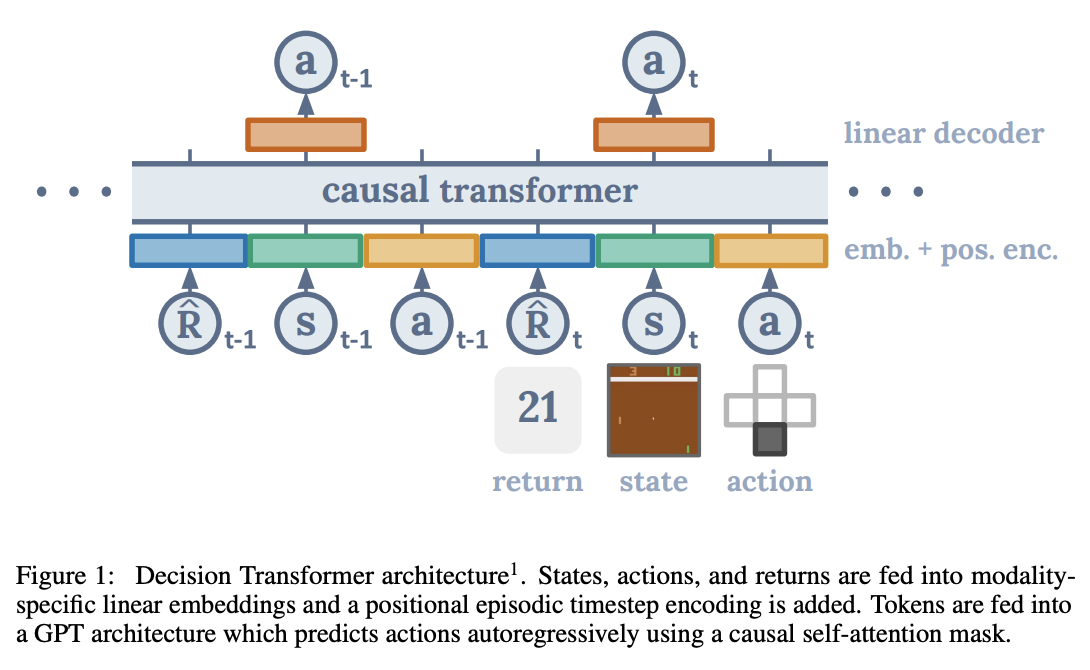
Understanding RL Vision
With diverse environments, we can analyze, diagnose and edit deep reinforcement learning models using attribution.
https://distill.pub/2020/understanding-rl-vision/
