

 Seonglae Cho
Seonglae ChoXAI
Explainability
Within the black box AI model, attempting to understand the decision-making process
Explainable AI notion
Neural Turing Machine (2014 Google)
arxiv.org
https://arxiv.org/pdf/1410.5401.pdf
Circuit, Superposition, Universality (2020 OpenAI)
Thread: Circuits
What can we learn if we invest heavily in reverse engineering a single neural network?
https://distill.pub/2020/circuits/
Residual Stream (2021 Anthropic)
A Mathematical Framework for Transformer Circuits
Transformer language models are an emerging technology that is gaining increasingly broad real-world use, for example in systems like GPT-3 , LaMDA , Codex , Meena , Gopher , and similar models. However, as these models scale, their open-endedness and high capacity creates an increasing scope for unexpected and sometimes harmful behaviors. Even years after a large model is trained, both creators and users routinely discover model capabilities – including problematic behaviors – they were previously unaware of.
https://transformer-circuits.pub/2021/framework/index.html
Circuit analysis & Grokking (2022 OpenAI)
arxiv.org
https://arxiv.org/pdf/2201.02177.pdf
arxiv.org
https://arxiv.org/pdf/2207.13243.pdf
arxiv.org
https://arxiv.org/pdf/2211.00593.pdf
Neuron Analysis & FSM (2023 Anthropic)
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning
Using a sparse autoencoder, we extract a large number of interpretable features from a one-layer transformer.Browse A/1 Features →Browse All Features →
https://transformer-circuits.pub/2023/monosemantic-features/index.html
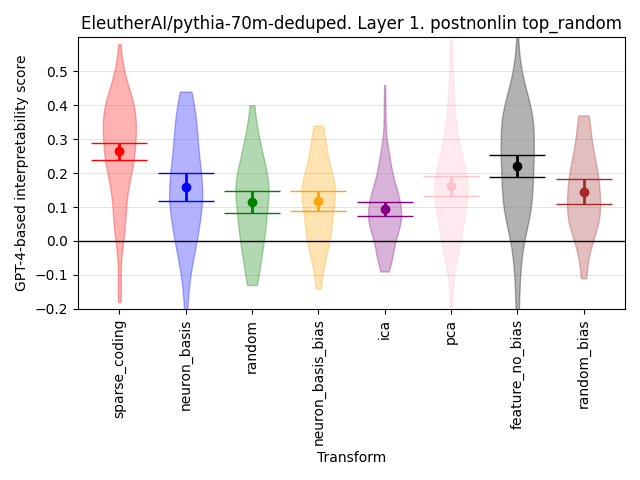
AutoInterpretation Finds Sparse Coding Beats Alternatives — LessWrong
Produced as part of the SERI ML Alignment Theory Scholars Program - Summer 2023 Cohort …

https://www.lesswrong.com/posts/ursraZGcpfMjCXtnn/autointerpretation-finds-sparse-coding-beats-alternatives
Wiki
Explainable artificial intelligence
Explainable AI (XAI), often overlapping with Interpretable AI, or Explainable Machine Learning (XML), either refers to an artificial intelligence (AI) system over which it is possible for humans to retain intellectual oversight, or refers to the methods to achieve this.[1][2] The main focus is usually on the reasoning behind the decisions or predictions made by the AI[3] which are made more understandable and transparent.[4] XAI counters the "black box" tendency of machine learning, where even the AI's designers cannot explain why it arrived at a specific decision.[5][6]

https://en.wikipedia.org/wiki/Explainable_artificial_intelligence
Strategies
Toy Models of Superposition
It would be very convenient if the individual neurons of artificial neural networks corresponded to cleanly interpretable features of the input. For example, in an “ideal” ImageNet classifier, each neuron would fire only in the presence of a specific visual feature, such as the color red, a left-facing curve, or a dog snout. Empirically, in models we have studied, some of the neurons do cleanly map to features. But it isn't always the case that features correspond so cleanly to neurons, especially in large language models where it actually seems rare for neurons to correspond to clean features. This brings up many questions. Why is it that neurons sometimes align with features and sometimes don't? Why do some models and tasks have many of these clean neurons, while they're vanishingly rare in others?
https://transformer-circuits.pub/2022/toy_model/index.html#strategic