Seonglae Cho
Seonglae Cho
The directions obtained through sparse coding showed higher interpretability compared to random directions, PCA, and ICA when used as neuron basis
Contrastive Explainer
The contrastive explainer approach involves providing the explainer prompt with both positive (activated) examples and negative (inactive, hard negative) examples together, then asking the LLM to explain the concept that distinguishes between these two types of examples.
2021 MIT
Natural language descriptions of deep visual features
arxiv.org
https://arxiv.org/pdf/2201.11114.pdf
2023 OpenAI
All of activations are quantized to be between 0-9 inclusive.
Language models can explain neurons in language models
Methodology: Nick effectively started the project by having the initial idea to have GPT-4 explain neurons,
and showing a simple explanation methodology worked. William came up with the initial simulation and scoring
methodology and implementation. Dan and Steven ran many experiments resulting in ultimate choices of prompts and
explanation/scoring parameters.
https://openaipublic.blob.core.windows.net/neuron-explainer/paper/index.html
Language models can explain neurons in language models
We use GPT-4 to automatically write explanations for the behavior of neurons in large language models and to score those explanations. We release a dataset of these (imperfect) explanations and scores for every neuron in GPT-2.
https://openai.com/research/language-models-can-explain-neurons-in-language-models

2024
intervention scoring
delphi
EleutherAI • Updated 2026 Jul 14 9:11
sparsify
EleutherAI • Updated 2026 Jul 20 11:51
Analyze the impact of a feature on model outputs by comparing the baseline output with the output after intervention
arxiv.org
https://arxiv.org/pdf/2410.13928
Open Source Automated Interpretability for Sparse Autoencoder Features
Building and evaluating an open-source pipeline for auto-interpretability
https://blog.eleuther.ai/autointerp/

Gradual improvement with hypothesis Best-of-k sampling and small model by knowledge distillation
Scaling Automatic Neuron Description<!-- --> | Transluce AI
We are releasing a database of descriptions of every neuron inside Llama-3.1-8B-Instruct,
and weights of an explainer model finetuned to produce them.
These descriptions have similar quality to a human expert on automated metrics,
and can be generated inexpensively using an 8B-parameter model.
These high-quality descriptions allow us to query and steer representations in
natural languge, enabling applications such as our observability interface.
https://transluce.org/neuron-descriptions
In order to get feature explanations Claude 2 is provided with a total of 49 examples: ten examples from the top activations interval; two from the other 12 intervals; five completely random examples; and ten examples where the top activating tokens appear in different contexts. Finally, we ask the model to be succinct in its answer and not provide specific examples of tokens it activates for.
Using the explanation generated, in a new interaction Claude is asked to predict activations for sixty examples: six from the top activations; two from the other 12 intervals; ten completely random; and twenty top activating tokens out of context. For the sake of computational efficiency, Claude scores all sixty examples in a single shot, repeating each token followed by its predicted activation. In an ideal setting, each example would be given independently as its own prompt.
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning
Mechanistic interpretability seeks to understand neural networks by breaking them into components that are more easily understood than the whole. By understanding the function of each component, and how they interact, we hope to be able to reason about the behavior of the entire network. The first step in that program is to identify the correct components to analyze.
https://transformer-circuits.pub/2023/monosemantic-features#appendix-automated
Transluce
Scaling Automatic Neuron Description<!-- --> | Transluce AI
We are releasing a database of descriptions of every neuron inside Llama-3.1-8B-Instruct,
and weights of an explainer model finetuned to produce them.
These descriptions have similar quality to a human expert on automated metrics,
and can be generated inexpensively using an 8B-parameter model.
These high-quality descriptions allow us to query and steer representations in
natural languge, enabling applications such as our observability interface.
https://transluce.org/neuron-descriptions
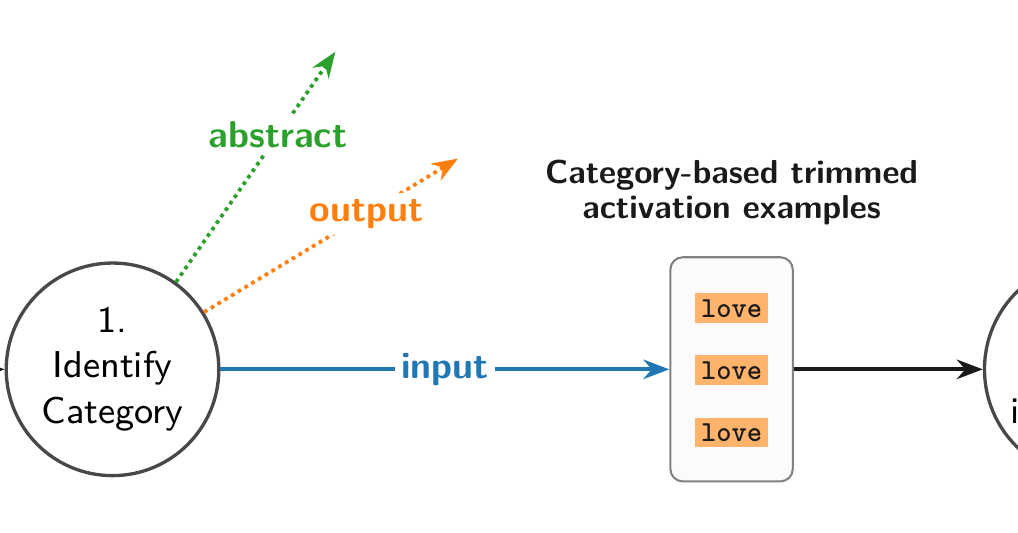
AIR
Instead of the usual approach—feeding top-activating examples and logits together and having the LLM both identify the feature type and generate an explanation—a sentence embedder first estimates the feature type, then selects only the relevant token window(s) or logits for that type and passes them to the LLM explainer.
Not all features are created equal — LessWrong
TL;DR Recent studies by Anthropic show that LLM features extracted via mechanistic interpretability fall into distinct categories, each with differen…

https://www.lesswrong.com/posts/Y5Lv8vafibpo7iYhi/not-all-features-are-created-equal