

 Seonglae Cho
Seonglae ChoLow-Rank Adaptation
LoRA is a technique that optimizes rank decomposition matrices with LoRA module rank .
The existing PEFT technology reduces the available sequence length of the model or expands the model depth for inference. LoRA usually applied to MLP by two low-rank matrix before activation.
Free weight and append adaptation layer composed by adaptation matrix with proving low-rank adaptation matrix is sufficient for fine-tuning. By dividing adaptation matrix likeBottleneck layer, It makes total model size smaller and make it achieve same learning rate with less computing resources.
A learning rate of 1e-4 has become the standard when fine-tuning LLMs with LoRA. Although we occasionally encountered training loss instabilities, reducing the learning rate to lower values like 3e-5. LoRA’s weight is initialized randomly but techniques likeEVA uses activation vector decomposing it to initialize based on priority.
LoRA Usages
LoRA architectures generate distinct high-magnitude eigenvalues, known as intrusive components, that don't exist in conventional fine-tuning. These components influence how the model generalizes.
LoRA vs Full Fine-tuning: An Illusion of Equivalence
Fine-tuning is a crucial paradigm for adapting pre-trained large language models to downstream tasks. Recently, methods like Low-Rank Adaptation (LoRA) have been shown to match the performance of...
https://arxiv.org/abs/2410.21228
Model Regularization
LoRA Learns Less and Forgets Less
arxiv.org
https://arxiv.org/pdf/2405.09673
It is enough to change Cross-Attention layer for fine tuning
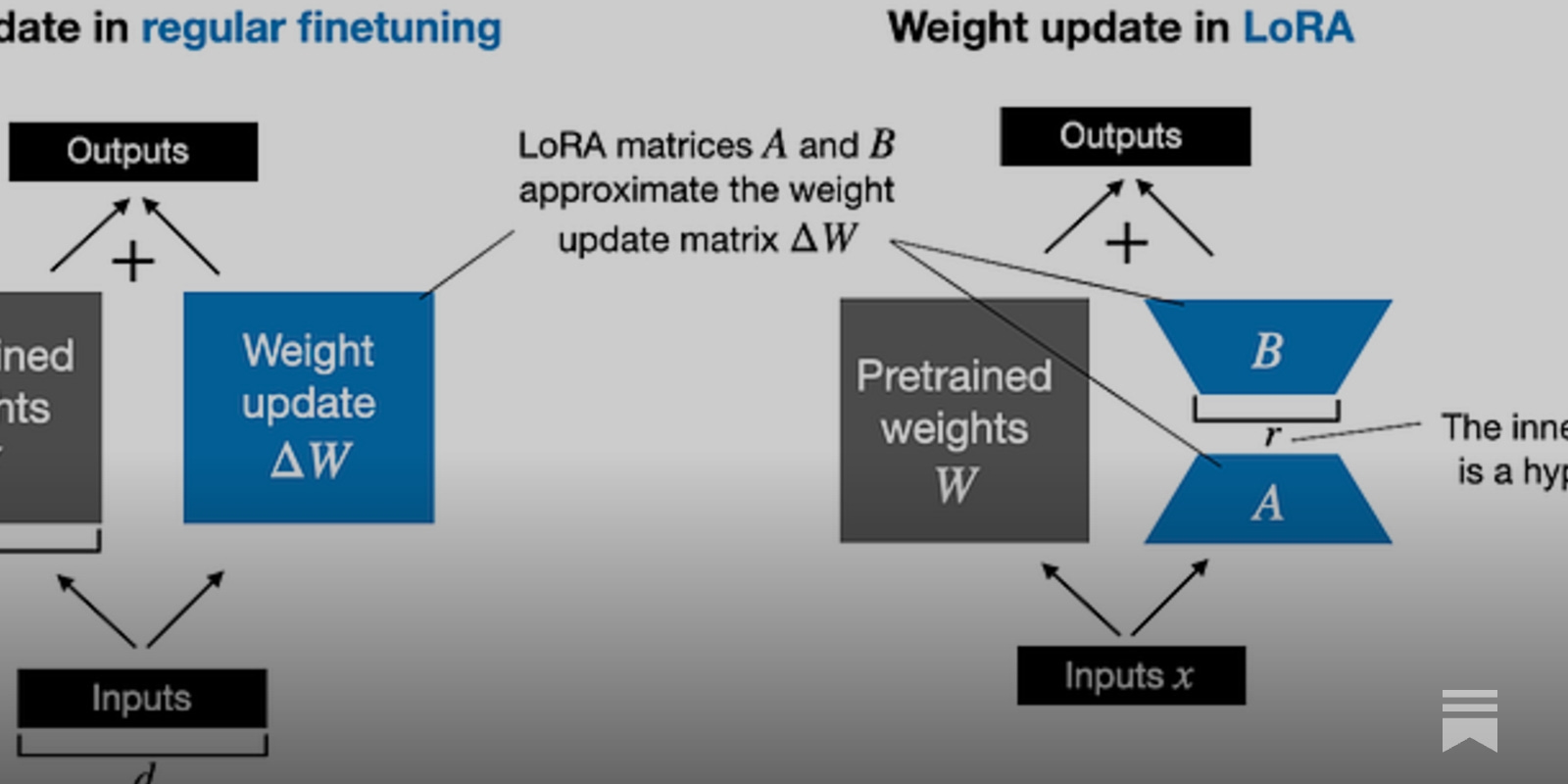
LoRA: Low-Rank Adaptation of Large Language Models
An important paradigm of natural language processing consists of large-scale pre-training on general domain data and adaptation to particular tasks or domains. As we pre-train larger models, full...
https://arxiv.org/abs/2106.09685
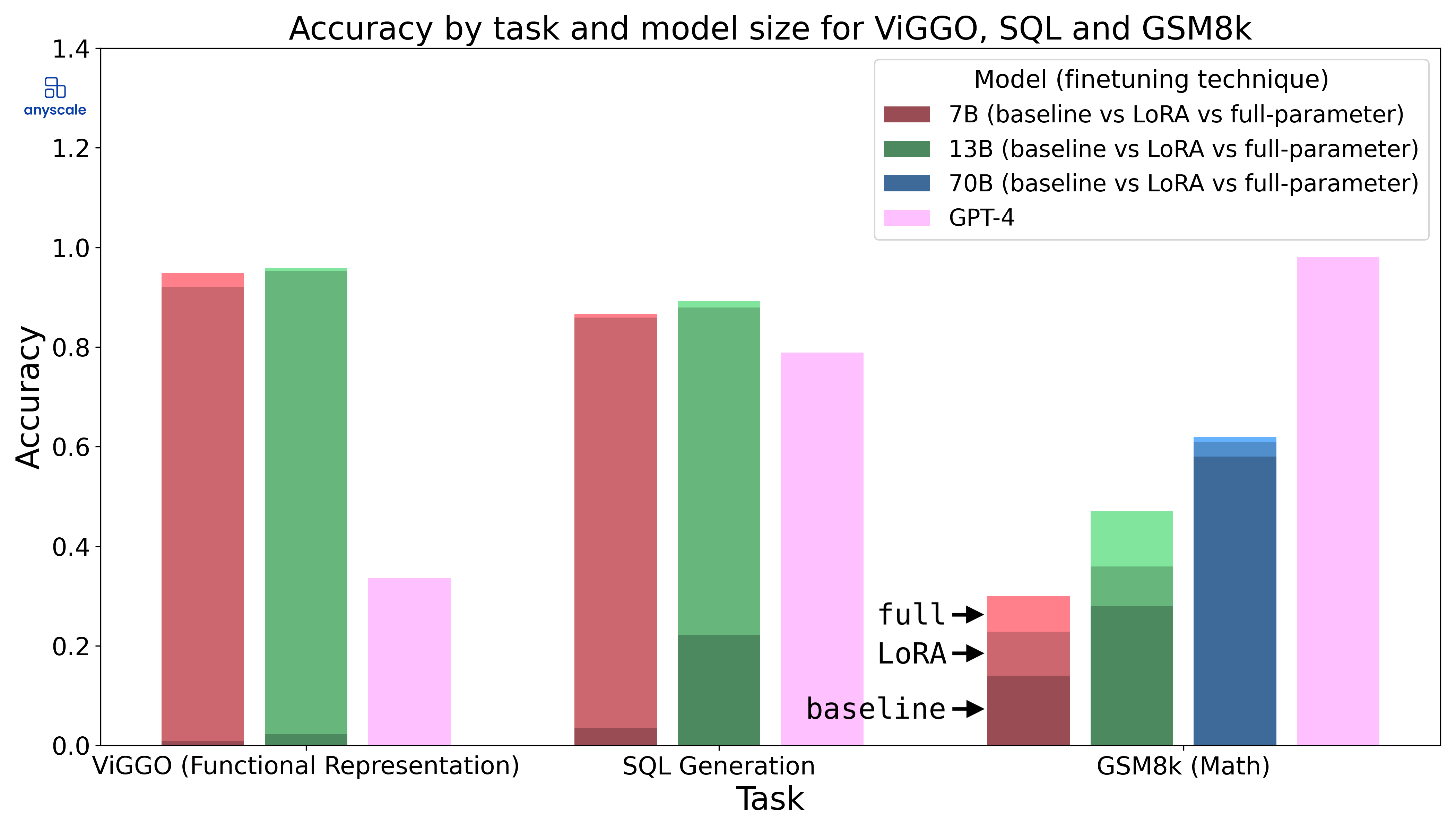
Fine-Tuning LLMs: In-Depth Analysis with LLAMA-2 | Anyscale
In this blog, we compare full-parameter fine-tuning with LoRA and answer questions around the strengths and weaknesses of the two techniques.
https://www.anyscale.com/blog/fine-tuning-llms-lora-or-full-parameter-an-in-depth-analysis-with-llama-2
[논문리뷰] LoRA: Low-Rank Adaptation of Large Language Models
LoRA 논문 리뷰
https://kimjy99.github.io/논문리뷰/lora/
Tips
Practical Tips for Finetuning LLMs Using LoRA (Low-Rank Adaptation)
Things I Learned From Hundreds of Experiments
https://magazine.sebastianraschka.com/p/practical-tips-for-finetuning-llms
Fast
Paper page - Drag-and-Drop LLMs: Zero-Shot Prompt-to-Weights
Join the discussion on this paper page
https://huggingface.co/papers/2506.16406
