Seonglae Cho
Seonglae ChoLoRA + Model Quantization
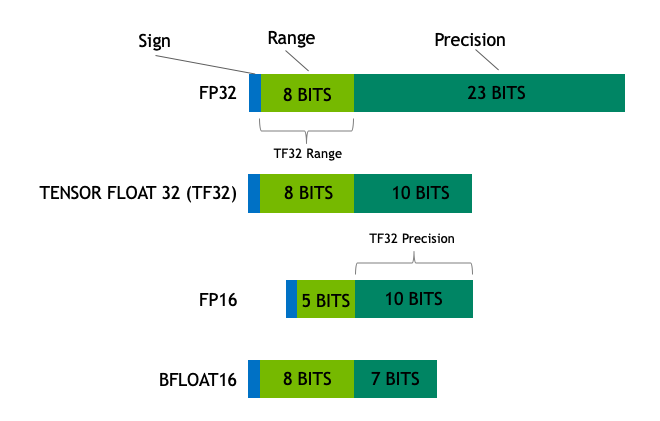
4-bit Normalized FP + Double Quantized + Paged Optimizer = Memory Optimization
- Store LoRA weight as quantized Normalized Floating Point 4 bit form NF4
- Dequantize 4 bit value to BF16 during forward or backward
QLoRA Usages
적은 GPU 메모리로 대규모 언어 모델을 트레이닝 하는 기법 「QLoRA」가 등장
GPT-1은 1억 1,700만 개의 파라미터를 가지는 언어 모델로, GPT-2에서는 15억, GPT-3에서는 1,750억 개로 파라미터 수가 증가함에 따라 언어 모델 성능이 좋아지고 있습니다. 그러나 파라미터의 수가 증가함에 따라 교육에 필요한 데이터 수와 교육에 사용되는 메모리 양도 증가하여 교육 비용이 크게 증가합니다. 그런 가운데, 메모리의 소비량을 격감시키면서 적은 데이터로 트레이닝할 수 있는 기법 「QLoRA」가 등장했습니다. [2305.14314] QLoRA: Efficient Finetuning of Quantized LLMs https://arxiv.org/abs/2305.14314 artidoro/qlora: QLoRA: Efficient Finetuning of Quantized LLM..

https://doooob.tistory.com/1029

QLoRA: 48GB GPU로 65B 모델의 미세조정(파인튜닝)이 가능하다고요?
지난 주의 Drag Your GAN에 이어, 오늘은 QLoRA: Efficient Finetuning of Quantized LLMs를 들고 왔습니다! 지난 주에 SNS 상에서 많은 분들께서 언급해주셨고, HuggingFace에서도 관련 글이나 자료들이 나왔었는데요, 저희 게시판에서도 @yblee 님께서 데일리 뉴스로 소개를 해주시기도 하였고, TLDR AI 뉴스레터에서도 소개되어... 봐야지... 봐야지... 하고 생각만 하다가 (연휴 내내 뒹굴거리느랴 바빠서) 이제서야 김 굽듯이 대애추웅 살펴보게 되었습니다 😅 소개 LLM은 학습은 꿈도 못 꾸고, 파인튜닝(미세조정) 시에도 엄청난 시간과 비용이 소모됩니다. 지난 주에 KoAlpaca 개발자이신 이준범님께서 발표 때 말씀해주신 내용으로는, Polyglot-Ko 12.8B 모델을 파인튜닝하는데 대략 A100(80G) 4대로 12시간 가량 걸렸다고 하십니다. 더 큰 모델이라면.... ...
https://discuss.pytorch.kr/t/qlora-48gb-gpu-65b/1682

towardsdatascience.com
https://towardsdatascience.com/qlora-fine-tune-a-large-language-model-on-your-gpu-27bed5a03e2b
Paper with parameter values
QLoRA: Efficient Finetuning of Quantized LLMs
We present QLoRA, an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance....
https://arxiv.org/abs/2305.14314
Korean
github.com
https://github.com/daekeun-ml/genai-ko-LLM/tree/main/fine-tuning
QLoRA란?
양자화부터 QLoRA까지
https://velog.io/@nellcome/QLoRA란