

 Seonglae Cho
Seonglae ChoRetrieval-Enhanced
Fast
Utilizes an external retrieval database structure
Implementations
Improving language models by retrieving from trillions of tokens
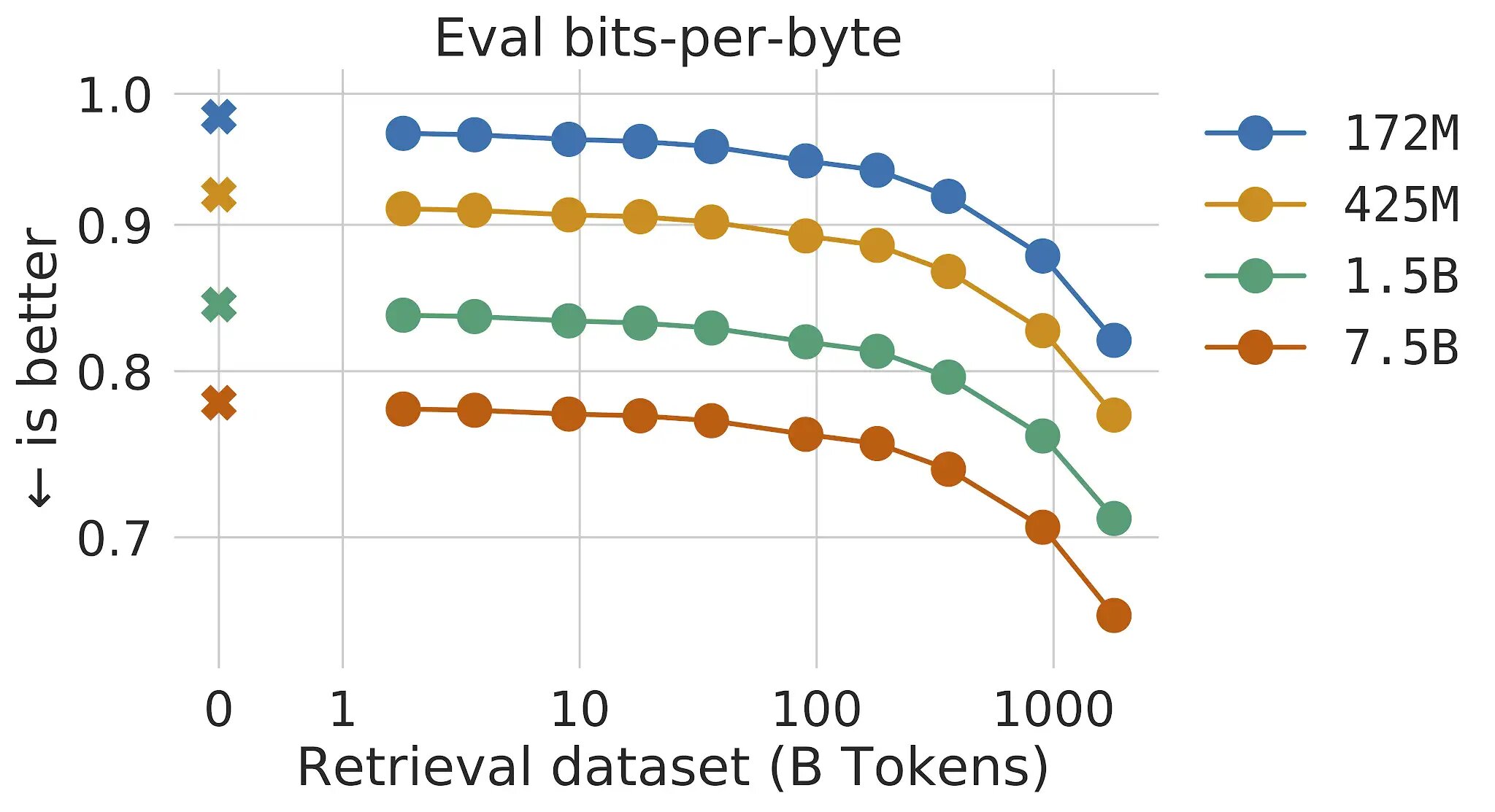
We enhance auto-regressive language models by conditioning on document chunks retrieved from a large corpus, based on local similarity with preceding tokens. With a $2$ trillion token database, our Retrieval-Enhanced Transformer (Retro) obtains comparable performance to GPT-3 and Jurassic-1 on the Pile, despite using 25× fewer parameters.
https://www.deepmind.com/publications/improving-language-models-by-retrieving-from-trillions-of-tokens
The Illustrated Retrieval Transformer
Discussion: Discussion Thread for comments, corrections, or any feedback. Translations: Korean, Russian Summary: The latest batch of language models can be much smaller yet achieve GPT-3 like performance by being able to query a database or search the web for information. A key indication is that building larger and larger models is not the only way to improve performance.
https://jalammar.github.io/illustrated-retrieval-transformer/
RETRO Is Blazingly Fast
When I first read Google's RETRO paper, I was skeptical. Sure, RETRO models are 25x smaller than the competition, supposedly leading to HUGE savings in training and inference costs. But what about the new trillion token "retrieval database" they added to the architcture? Surely that must add back some computational costs, balancing the cosmic seesaw?
http://mitchgordon.me/ml/2022/07/01/retro-is-blazing.html
Korean
RETRO: Improving language models by retrieving from trillions of tokens
Trillion단위의 토큰 데이터 베이스로 구성된 retrieval system을 이용한 언어 모델.Retrieval-Enhanced Transformer(RETRO)를 사용.25배 적은 파라미터(7B)로 GPT-3와 Jurassic-1과 비슷한 성능을 얻었다.Ret
https://velog.io/@nawnoes/RETRO-Improving-language-models-by-retrieving-from-trillions-of-tokens
