

 Seonglae Cho
Seonglae ChoSelf Attention is the core feature
Transformer is the first thing that actually scales. Before the Transformer, RNN such as LSTM and stacking them does not get clean scaling.
The Transformer gains a wider perspective and can attend to multiple interaction levels within the input sentence. Unlike CNN and RNN, a significant advancement is the improvement in handling distant Long-term dependency. Transformer Model is not just proficient in Language modeling but also versatile token sequence model with broader application across domains.
The model enables parallel processing by computing all tokens simultaneously, and unlike previous Attention Mechanisms, the paper uses all vectors as weight vectors.
After this paper, major changes in the field include the positioning of Layer Normalization, replacement with RMS Normalization, and the use of GLU as FFN activation.
Transformer Model Notion
Transformer Models
Transformer Visualization
Complete 3D visualization
LLM Visualization
A 3D animated visualization of an LLM with a walkthrough.
https://bbycroft.net/llm
Matrix form details
a transformer innit
https://ben-learning-transformers.vercel.app/
Blockwise flow
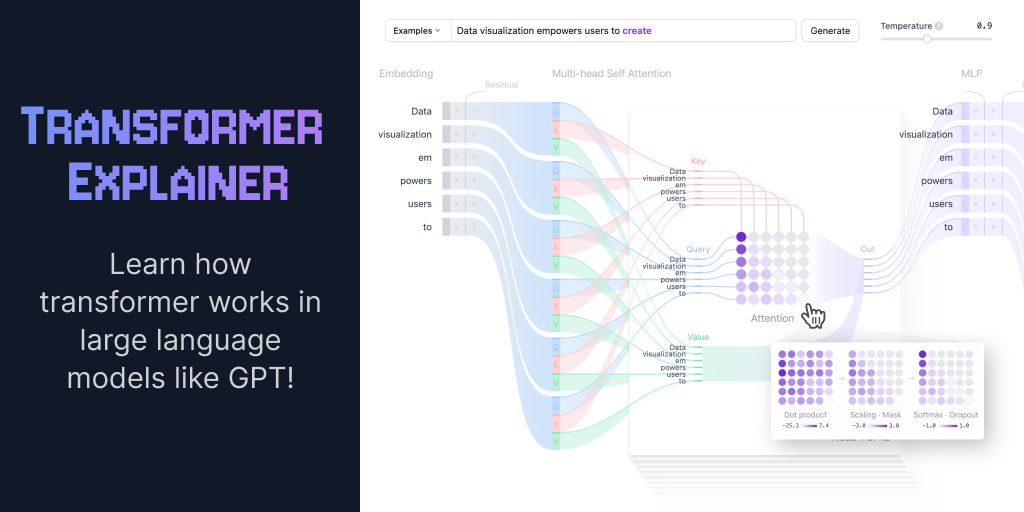
Transformer Explainer: LLM Transformer Model Visually Explained
An interactive visualization tool showing you how transformer models work in large language models (LLM) like GPT.

https://poloclub.github.io/transformer-explainer/
Architecture
arxiv.org
https://arxiv.org/pdf/1706.03762.pdf
2015
Effective Approaches to Attention-based Neural Machine Translation
An attentional mechanism has lately been used to improve neural machine translation (NMT) by selectively focusing on parts of the source sentence during translation. However, there has been little...
https://arxiv.org/abs/1508.04025
aclanthology.org
https://aclanthology.org/D16-1244.pdf
Pseudo Source code
Transformers for software engineers
Ever since its introduction in the 2017 paper, Attention is All You Need, the Transformer model architecture has taken the deep-learning world by storm. Initially introduced for machine translation, it has become the tool of choice for a wide range of domains, including text, audio, video, and others.
https://blog.nelhage.com/post/transformers-for-software-engineers/
But what is a GPT? Visual intro to Transformers | Deep learning, chapter 5
An introduction to transformers and their prerequisites
Early view of the next chapter for patrons: https://3b1b.co/early-attention
Special thanks to these supporters: https://3b1b.co/lessons/gpt#thanks
To contribute edits to the subtitles, visit https://translate.3blue1brown.com/
Other recommended resources on the topic.
Richard Turner's introduction is one of the best starting places:
https://arxiv.org/pdf/2304.10557.pdf
Coding a GPT with Andrej Karpathy
https://youtu.be/kCc8FmEb1nY
Introduction to self-attention by John Hewitt
https://web.stanford.edu/class/cs224n/readings/cs224n-self-attention-transformers-2023_draft.pdf
History of language models by Brit Cruise:
https://youtu.be/OFS90-FX6pg
------------------
Timestamps
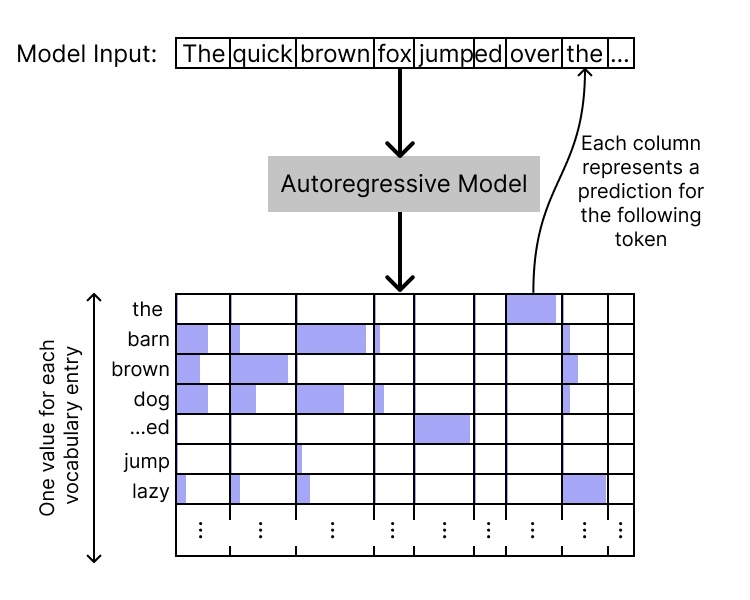
0:00 - Predict, sample, repeat
3:03 - Inside a transformer
6:36 - Chapter layout
7:20 - The premise of Deep Learning
12:27 - Word embeddings
18:25 - Embeddings beyond words
20:22 - Unembedding
22:22 - Softmax with temperature
26:03 - Up next
------------------
These animations are largely made using a custom Python library, manim. See the FAQ comments here:
https://3b1b.co/faq#manim
https://github.com/3b1b/manim
https://github.com/ManimCommunity/manim/
All code for specific videos is visible here:
https://github.com/3b1b/videos/
The music is by Vincent Rubinetti.
https://www.vincentrubinetti.com
https://vincerubinetti.bandcamp.com/album/the-music-of-3blue1brown
https://open.spotify.com/album/1dVyjwS8FBqXhRunaG5W5u
------------------
3blue1brown is a channel about animating math, in all senses of the word animate. If you're reading the bottom of a video description, I'm guessing you're more interested than the average viewer in lessons here. It would mean a lot to me if you chose to stay up to date on new ones, either by subscribing here on YouTube or otherwise following on whichever platform below you check most regularly.
Mailing list: https://3blue1brown.substack.com
Twitter: https://twitter.com/3blue1brown
Instagram: https://www.instagram.com/3blue1brown
Reddit: https://www.reddit.com/r/3blue1brown
Facebook: https://www.facebook.com/3blue1brown
Patreon: https://patreon.com/3blue1brown
Website: https://www.3blue1brown.com

https://www.youtube.com/watch?v=wjZofJX0v4M

Transformer Explainer
Transformer is a neural network architecture that has fundamentally changed the approach to
Artificial Intelligence. Transformer was first introduced in the seminal paper
"Attention is All You Need"
in 2017 and has since become the go-to architecture for deep learning models, powering text-generative
models like OpenAI's GPT, Meta's Llama, and Google's
Gemini. Beyond text, Transformer is also applied in
audio generation,
image recognition,
protein structure prediction, and even
game playing, demonstrating its versatility across numerous domains.
https://poloclub.github.io/transformer-explainer/
Patent US10/452, 978 ATTENTION-BASED SEQUENCE TRANSDUCTION NEURAL NETWORKS
Attention-based sequence transduction neural networks
Methods, systems, and apparatus, including computer programs encoded on a computer storage medium, for generating an output sequence from an input sequence. In one aspect, one of the systems includes an encoder neural network configured to receive the input sequence and generate encoded representations of the network inputs, the encoder neural network comprising a sequence of one or more encoder subnetworks, each encoder subnetwork configured to receive a respective encoder subnetwork input for each of the input positions and to generate a respective subnetwork output for each of the input positions, and each encoder subnetwork comprising: an encoder self-attention sub-layer that is configured to receive the subnetwork input for each of the input positions and, for each particular input position in the input order: apply an attention mechanism over the encoder subnetwork inputs using one or more queries derived from the encoder subnetwork input at the particular input position.
https://patents.google.com/patent/US10452978B2/en