

 Seonglae Cho
Seonglae ChoSAE for Classification
SAE probing uses learned sparse features as inputs to downstream classifiers.
Threshold Binarization logistic regression
Not using just one feature, but using entire dictionary as logistic regression's input
- Wider SAE shows worse performance overall (contradicts with previous below research)
- Threshold Binarization reduces computing costs and performance
arxiv.org
https://arxiv.org/pdf/2502.11367
Top-n logistic regression
- Wider SAE shows better performance
- SAE probes outperform traditional methods on small datasets (<100 samples)
- SAE probes maintain stable performance with label noise (due to being unsupervised)
- Similar performance to traditional methods for OOD and class imbalance cases
- For datasets with spurious correlations (distinguished by presence/absence of periods), it is interpretable and can be excluded
SAE Probing: What is it good for? Absolutely something! — LessWrong
Subhash and Josh are co-first authors. Work done as part of the two week research sprint in Neel Nanda’s MATS stream …

https://www.lesswrong.com/posts/NMLq8yoTecAF44KX9
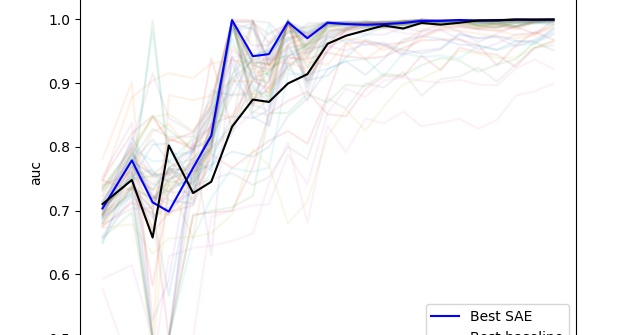
SAE probing is one of the few practical downstream tasks for SAEs besides interpretability, but it still underperforms compared to SOTA methods.
Takeaways From Our Recent Work on SAE Probing — LessWrong
Subhash and Josh are co-first authors on this work done in Neel Nanda’s MATS stream. …
https://www.lesswrong.com/posts/osNKnwiJWHxDYvQTD/takeaways-from-our-recent-work-on-sae-probing
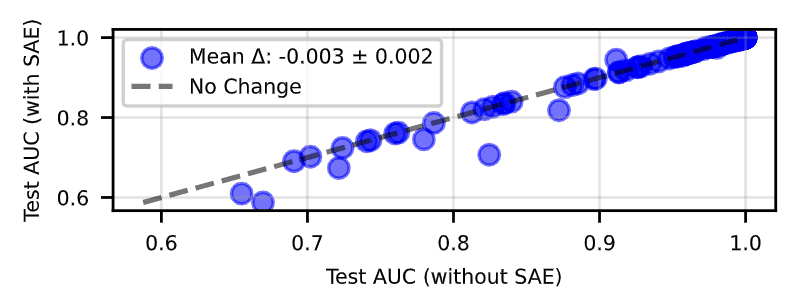
arxiv.org
https://arxiv.org/pdf/2502.16681
Linear probing is better demonstrated by Deepmind
Negative Results for SAEs On Downstream Tasks and Deprioritising SAE Research (GDM Mech Interp Team Progress Update #2) — LessWrong
Lewis Smith*, Sen Rajamanoharan*, Arthur Conmy, Callum McDougall, Janos Kramar, Tom Lieberum, Rohin Shah, Neel Nanda • * = equal contribution …
https://www.lesswrong.com/posts/4uXCAJNuPKtKBsi28/sae-progress-update-2-draft#Dataset_debugging_with_SAEs
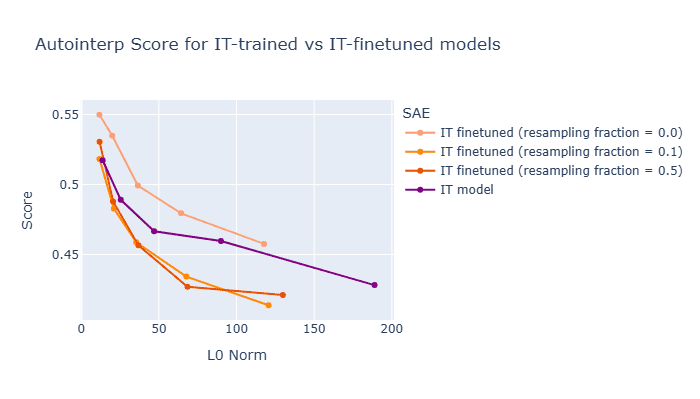
Generally, linear probes only assign positive labels to specific tokens, but in reality, features are activated by being transferred to other tokens through attention, resulting in probes learning misclassified data and reduced feature prediction performance. Therefore, SAE features that are distributively activated and correspond to the model's internal state rather than text may have a comparative advantage in probing.
Adam Karvonen on Twitter / X
I'm skeptical that probes would be as good. For example, consider a middle layer SAE gender feature, where ablating it significantly reduces model gender bias. It will activate on e.g. gender pronouns, but also on many other seemingly unrelated tokens. Presumably this is because…— Adam Karvonen (@a_karvonen) May 17, 2025
https://x.com/a_karvonen/status/1923757018122268686
Max pooling works better usually, since it is sparse and monosemantic
arxiv.org
https://arxiv.org/pdf/2509.06938
arxiv.org
https://arxiv.org/pdf/2508.12535
arxiv.org
https://arxiv.org/pdf/2511.16309
SAE as a classifier
Using Dictionary Learning Features as Classifiers
There has been recent success and excitement around extracting human interpretable features from LLMs using dictionary learning . However, many theorized benefits of these features have not yet been realized.
https://transformer-circuits.pub/2024/features-as-classifiers/index.html