Seonglae Cho
Seonglae ChoInterpretability and usage limitation
- Reducing reconstruction Loss
- SAE’s activations reflect two things: the distribution of the dataset and the way that distribution is transformed by the model.
- SAE encoder and decoder is not symmetry in many sense
About SAE Feature
- SAEs tend to capture low-level, context-independent features rather than highly context-dependent features, since they depend separately on individual tokens.
- Features that are only activated on specific tokens, which are not really necessary, should be avoided using loss (Prefer AI Context feature or AI Task vector than Token-in-context feature) (SAE feature importance)
While the token distribution entropy is not a direct measure of abstractness
- SAE Dead Feature (almost resolved)
SAE Limitations
Is SAE really meaningful or it is the property of sparse text dataset? (that only single-token features are discovered) I suspect the results are more due to the structure of the transformer itself rather than the superposition in token embeddings, since the comparison between random and intact token embeddings showed similar outcomes. This makes me curious about how these findings would generalize to other architectures.
arxiv.org
https://arxiv.org/pdf/2501.17727v1
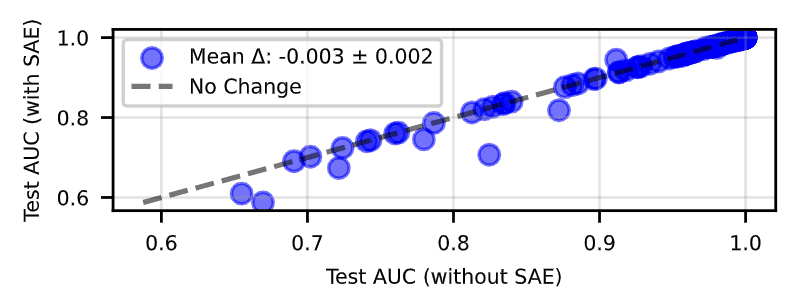
Instead of simple reconstruction loss, we need to design loss functions that directly optimize "downstream performance" or "interpretability". While outlier and spurious feature detection and data quality problem diagnosis can be performed intuitively and quickly, SAE Probing is useful but provides almost no benefit in terms of activation.
Takeaways From Our Recent Work on SAE Probing — LessWrong
Subhash and Josh are co-first authors on this work done in Neel Nanda’s MATS stream. …

https://www.lesswrong.com/posts/osNKnwiJWHxDYvQTD/takeaways-from-our-recent-work-on-sae-probing