Seonglae Cho
Seonglae ChoSupport vector machine
SVM is a Discriminative Model rather than a Statistical Model. It dominated machine learning as a powerful classifier throughout the 2000s before the rise of deep learning.
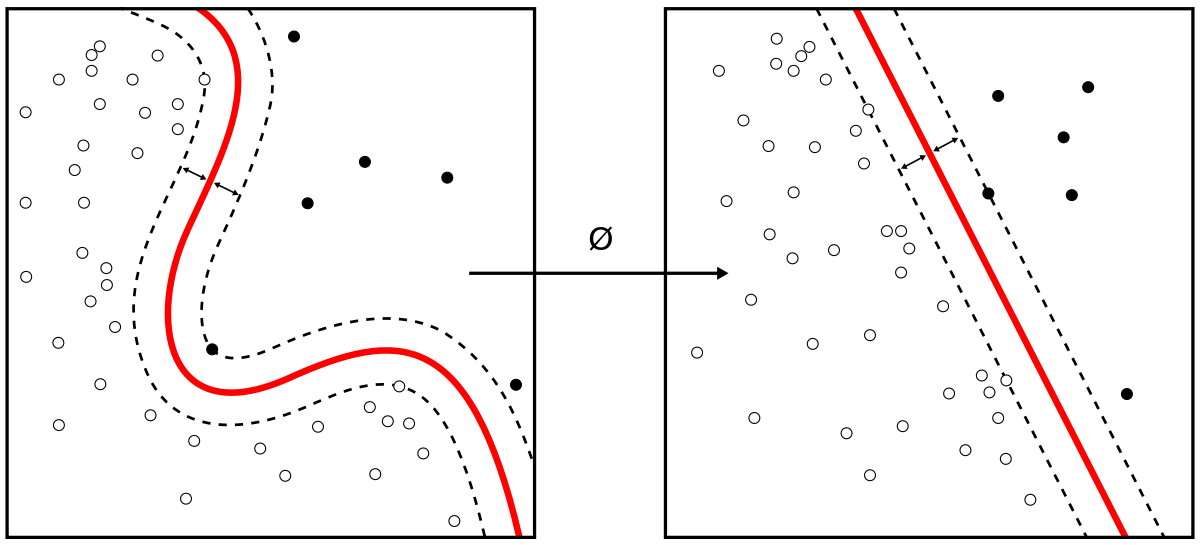
While SVM excels with small datasets, it lacks direct multi-class classification capabilities and requires combining multiple binary classifiers. The model uses weights (w), bias (b), and margin () as key parameters.
SVM Training Process
- Find an initial decision boundary that can separate input data either linearly or non-linearly
- Select support vectors - the data points closest to the initial decision boundary
- Update the decision boundary using these support vectors
- Repeat steps 2-3 until finding the optimal decision boundary
SVM Notion
SVMs
www.linkedin.com
https://www.linkedin.com/feed/update/urn:li:activity:7082025501048918016/
Implementations
Software
—
Kernel Machines
Kernel-Machines.Org software links
http://www.kernel-machines.org/software
Support vector machine
In machine learning, support vector machines are supervised learning models with associated learning algorithms that analyze data for classification and regression analysis. Developed at AT&T Bell Laboratories by Vladimir Vapnik with colleagues SVMs are one of the most robust prediction methods, being based on statistical learning frameworks or VC theory proposed by Vapnik and Chervonenkis (1974). Given a set of training examples, each marked as belonging to one of two categories, an SVM training algorithm builds a model that assigns new examples to one category or the other, making it a non-probabilistic binary linear classifier. SVM maps training examples to points in space so as to maximise the width of the gap between the two categories. New examples are then mapped into that same space and predicted to belong to a category based on which side of the gap they fall.

https://en.wikipedia.org/wiki/Support_vector_machine