
 Seonglae Cho
Seonglae Cho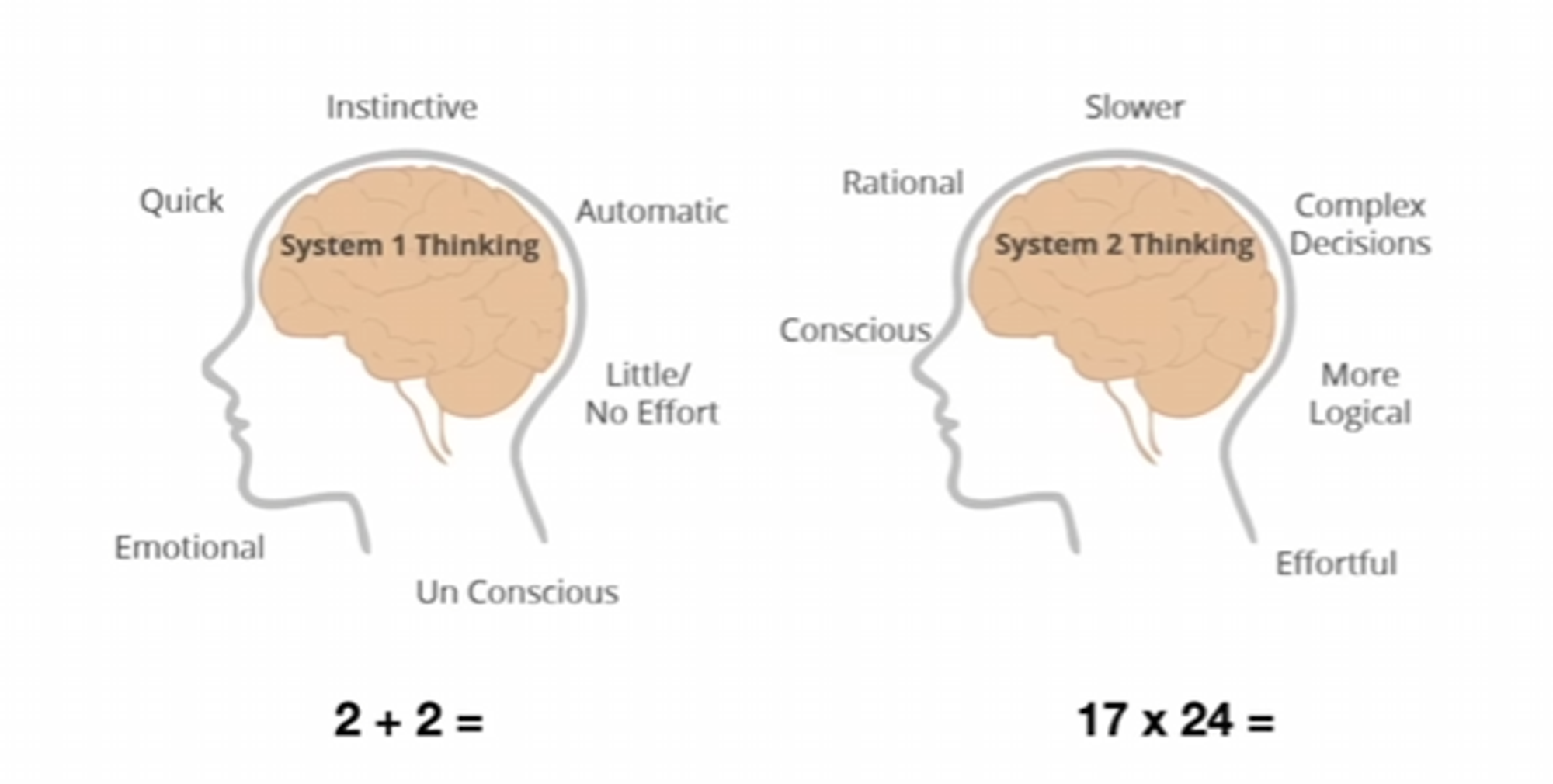
Chess
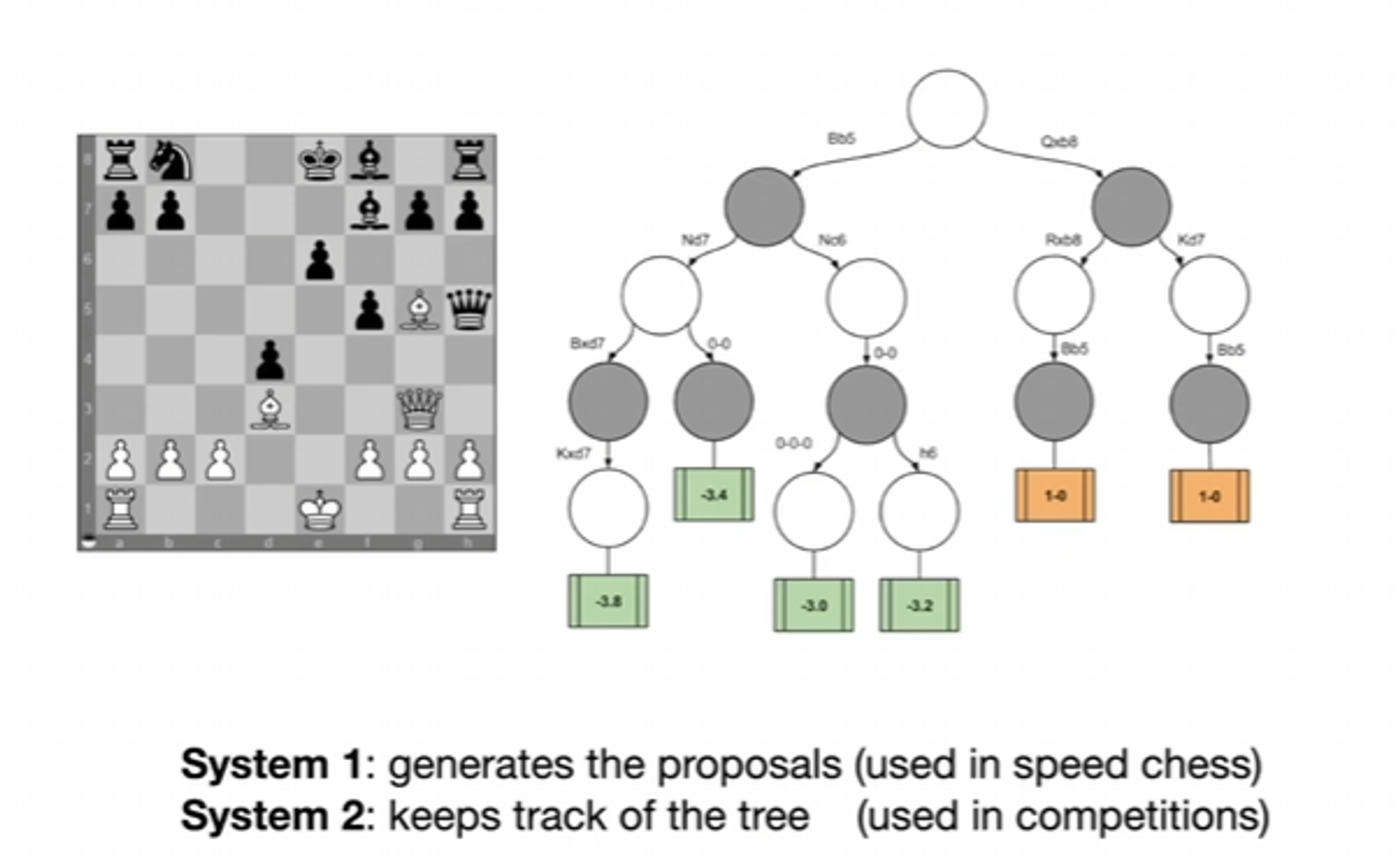
System 1
a near-instantaneous process
System 2
slower and requires more effort. It is conscious and logical
Thinking, Fast and Slow
Thinking, Fast and Slow is a 2011 popular science book by psychologist Daniel Kahneman.
The book's main thesis is a differentiation between two modes of thought: "System 1" is fast, instinctive and emotional; "System 2" is slower, more deliberative, and more logical.

https://en.wikipedia.org/wiki/Thinking,_Fast_and_Slow

[1hr Talk] Intro to Large Language Models
This is a 1 hour general-audience introduction to Large Language Models: the core technical component behind systems like ChatGPT, Claude, and Bard. What they are, where they are headed, comparisons and analogies to present-day operating systems, and some of the security-related challenges of this new computing paradigm.
As of November 2023 (this field moves fast!).
Context: This video is based on the slides of a talk I gave recently at the AI Security Summit. The talk was not recorded but a lot of people came to me after and told me they liked it. Seeing as I had already put in one long weekend of work to make the slides, I decided to just tune them a bit, record this round 2 of the talk and upload it here on YouTube. Pardon the random background, that's my hotel room during the thanksgiving break.
- Slides as PDF: https://drive.google.com/file/d/1pxx_ZI7O-Nwl7ZLNk5hI3WzAsTLwvNU7/view?usp=share_link (42MB)
- Slides. as Keynote: https://drive.google.com/file/d/1FPUpFMiCkMRKPFjhi9MAhby68MHVqe8u/view?usp=share_link (140MB)
Few things I wish I said (I'll add items here as they come up):
- The dreams and hallucinations do not get fixed with finetuning. Finetuning just "directs" the dreams into "helpful assistant dreams". Always be careful with what LLMs tell you, especially if they are telling you something from memory alone. That said, similar to a human, if the LLM used browsing or retrieval and the answer made its way into the "working memory" of its context window, you can trust the LLM a bit more to process that information into the final answer. But TLDR right now, do not trust what LLMs say or do. For example, in the tools section, I'd always recommend double-checking the math/code the LLM did.
- How does the LLM use a tool like the browser? It emits special words, e.g. |BROWSER|. When the code "above" that is inferencing the LLM detects these words it captures the output that follows, sends it off to a tool, comes back with the result and continues the generation. How does the LLM know to emit these special words? Finetuning datasets teach it how and when to browse, by example. And/or the instructions for tool use can also be automatically placed in the context window (in the “system message”).
- You might also enjoy my 2015 blog post "Unreasonable Effectiveness of Recurrent Neural Networks". The way we obtain base models today is pretty much identical on a high level, except the RNN is swapped for a Transformer. http://karpathy.github.io/2015/05/21/rnn-effectiveness/
- What is in the run.c file? A bit more full-featured 1000-line version hre: https://github.com/karpathy/llama2.c/blob/master/run.c
Chapters:
Part 1: LLMs
00:00:00 Intro: Large Language Model (LLM) talk
00:00:20 LLM Inference
00:04:17 LLM Training
00:08:58 LLM dreams
00:11:22 How do they work?
00:14:14 Finetuning into an Assistant
00:17:52 Summary so far
00:21:05 Appendix: Comparisons, Labeling docs, RLHF, Synthetic data, Leaderboard
Part 2: Future of LLMs
00:25:43 LLM Scaling Laws
00:27:43 Tool Use (Browser, Calculator, Interpreter, DALL-E)
00:33:32 Multimodality (Vision, Audio)
00:35:00 Thinking, System 1/2
00:38:02 Self-improvement, LLM AlphaGo
00:40:45 LLM Customization, GPTs store
00:42:15 LLM OS
Part 3: LLM Security
00:45:43 LLM Security Intro
00:46:14 Jailbreaks
00:51:30 Prompt Injection
00:56:23 Data poisoning
00:58:37 LLM Security conclusions
End
00:59:23 Outro
![[1hr Talk] Intro to Large Language Models](https://www.youtube.com/s/desktop/85bdacdc/img/favicon_144x144.png)
https://www.youtube.com/watch?v=zjkBMFhNj_g
![[1hr Talk] Intro to Large Language Models](https://i.ytimg.com/vi/zjkBMFhNj_g/hqdefault.jpg)
System 1 and System 2 Thinking - The Decision Lab
System 1 thinking is a near-instantaneous thinking process while System 2 thinking is slower and requires more effort.
https://thedecisionlab.com/reference-guide/philosophy/system-1-and-system-2-thinking

Descriptive and Part Prescriptive
aclanthology.org
https://aclanthology.org/2025.acl-long.1454.pdf