

 Seonglae Cho
Seonglae ChoScaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet
We find a diversity of highly abstract features. They both respond to and behaviorally cause abstract behaviors. Examples of features we find include features for famous people, features for countries and cities, and features tracking type signatures in code. Many features are multilingual (responding to the same concept across languages) and multimodal (responding to the same concept in both text and images), as well as encompassing both abstract and concrete instantiations of the same idea (such as code with security vulnerabilities, and abstract discussion of security vulnerabilities).
https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html
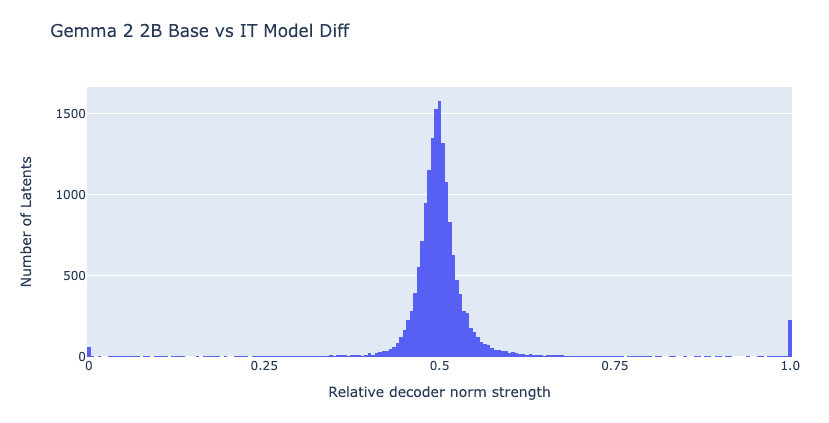
Open Source Replication of Anthropic’s Crosscoder paper for model-diffing — LessWrong
Intro Anthropic recently released an exciting mini-paper on crosscoders (Lindsey et al.). In this post, we open source a model-diffing crosscoder tra…

https://www.lesswrong.com/posts/srt6JXsRMtmqAJavD/open-source-replication-of-anthropic-s-crosscoder-paper-for
Who's asking? User personas and the mechanics of latent misalignment
Despite investments in improving model safety, studies show that misaligned capabilities remain latent in safety-tuned models. In this work, we shed light on the mechanics of this phenomenon....
https://arxiv.org/abs/2406.12094