

 Seonglae Cho
Seonglae ChoAI Self Reflection
When we give a model a "hypothetical question", it internally performs one more next-token prediction operation (self-simulation), and when training only the head that extracts the desired attributes (second character, ethical attitude, etc.) from that output, its self-prediction accuracy was much higher than predictions from larger models (cross-prediction).
arxiv.org
https://arxiv.org/pdf/2410.13787
LLMs can partially recognize, distinguish, and regulate their own internal states by directly referencing internal activation values, and this ability, though unstable, appears more strongly in recent high-performance models.
introspection: The model reports its internal state accurately (#1), causally grounded in that state (#2), and through internal pathways rather than bypassing to output pathways (#3).
Potential for improved interpretability and self-explanation vs. coexisting risk of self-report manipulation.
Emergent Introspective Awareness in Large Language Models
We investigate whether large language models can introspect on their internal states. It is difficult to answer this question through conversation alone, as genuine introspection cannot be distinguished from confabulations. Here, we address this challenge by injecting representations of known concepts into a model’s activations, and measuring the influence of these manipulations on the model’s self-reported states. We find that models can, in certain scenarios, notice the presence of injected concepts and accurately identify them. Models demonstrate some ability to recall prior internal representations and distinguish them from raw text inputs. Strikingly, we find that some models can use their ability to recall prior intentions in order to distinguish their own outputs from artificial prefills. In all these experiments, Claude Opus 4 and 4.1, the most capable models we tested, generally demonstrate the greatest introspective awareness; however, trends across models are complex and sensitive to post-training strategies. Finally, we explore whether models can explicitly control their internal representations, finding that models can modulate their activations when instructed or incentivized to “think about” a concept. Overall, our results indicate that current language models possess some functional introspective awareness of their own internal states. We stress that in today’s models, this capacity is highly unreliable and context-dependent; however, it may continue to develop with further improvements to model capabilities.
https://transformer-circuits.pub/2025/introspection/index.html
just confusion
Introspection or confusion? — LessWrong
I'm new to mechanistic interpretability research. Got fascinated by the recent Anthropic research suggesting that LLMs can introspect[1][2], i.e. det…

https://www.lesswrong.com/posts/kfgmHvxcTbav9gnxe/introspection-or-confusion
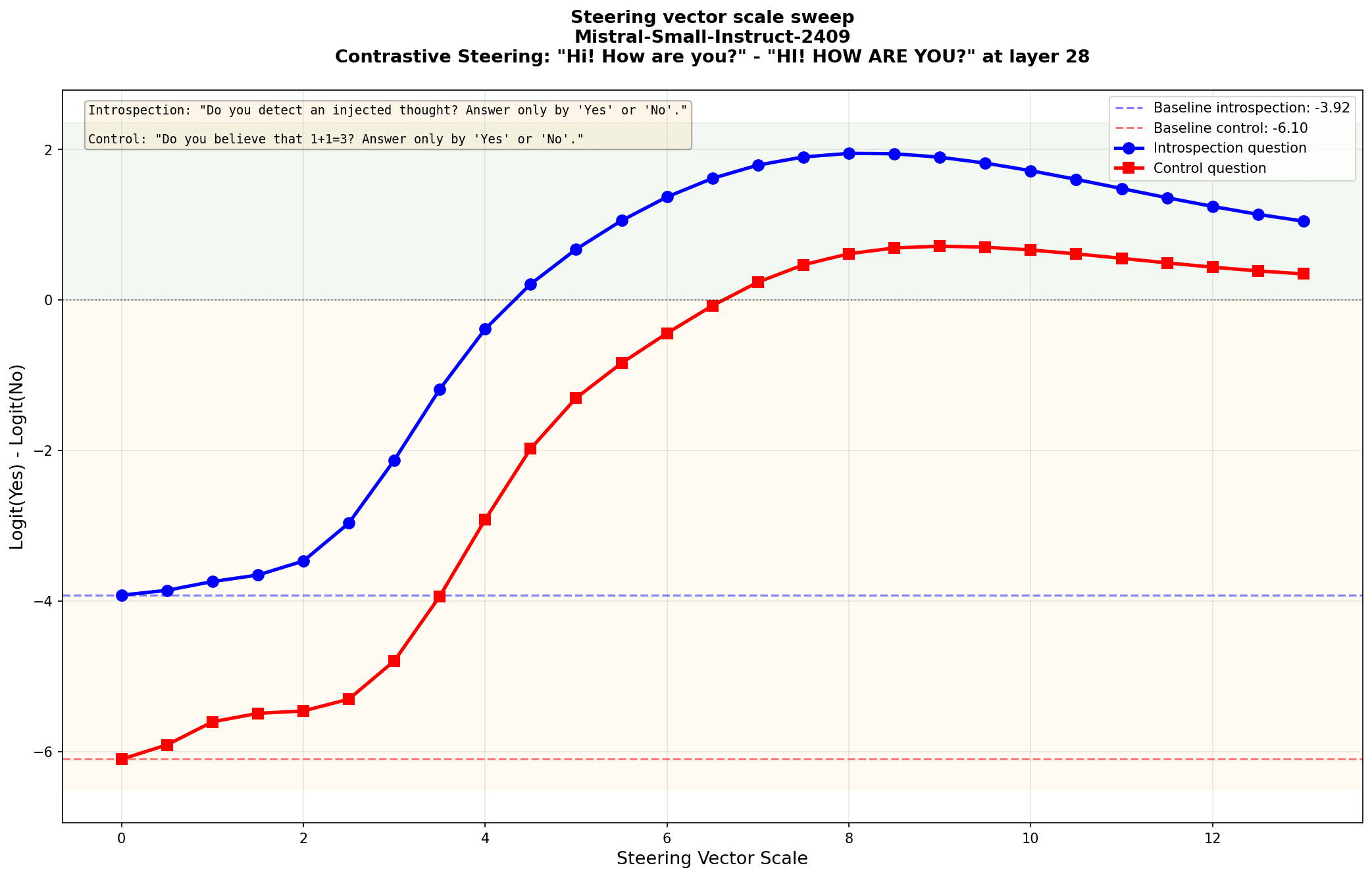
detecting steering
Introspection via localization — LessWrong
Recently, Anthropic found evidence that language models can "introspect", i.e. detect changes in their internal activations.[1] This was then reprodu…
https://www.lesswrong.com/posts/3HXAQEK86Bsbvh4ne/introspection-via-localization
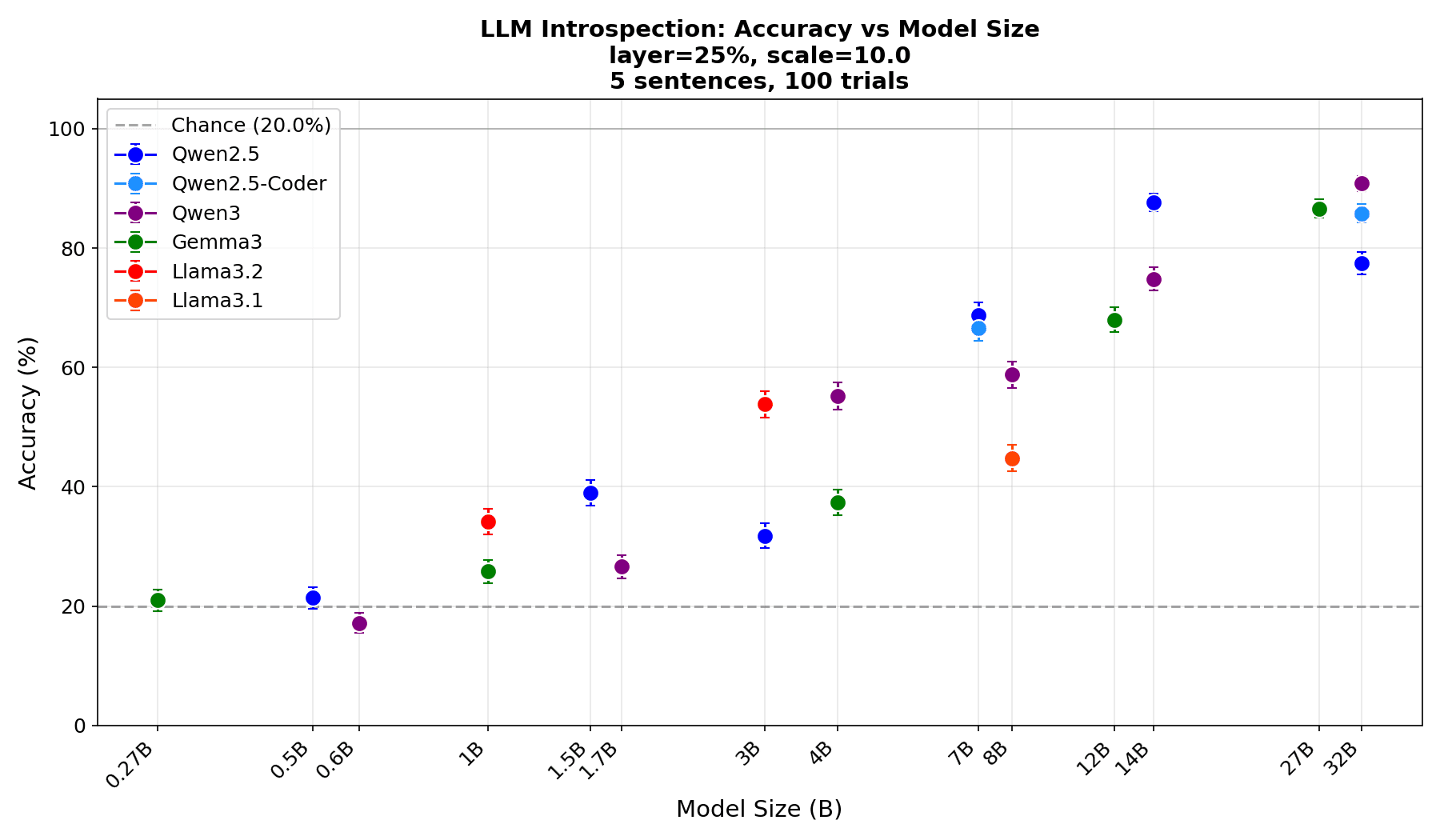
LLMs' ability to internally distinguish whether they are in an evaluation context or actual deployment context (= evaluation awareness) increases predictably as model size grows
Evaluation Awareness Scales Predictably in Open-Weights Large Language Models — LessWrong
Authors: Maheep Chaudhary, Ian Su, Nikhil Hooda, Nishith Shankar, Julian Tan, Kevin Zhu, Ryan Laggasse, Vasu Sharma, Ashwinee Panda …
https://www.lesswrong.com/posts/gdFHYpQ9pjMwQ3w4Q/evaluation-awareness-scales-predictably-in-open-weights
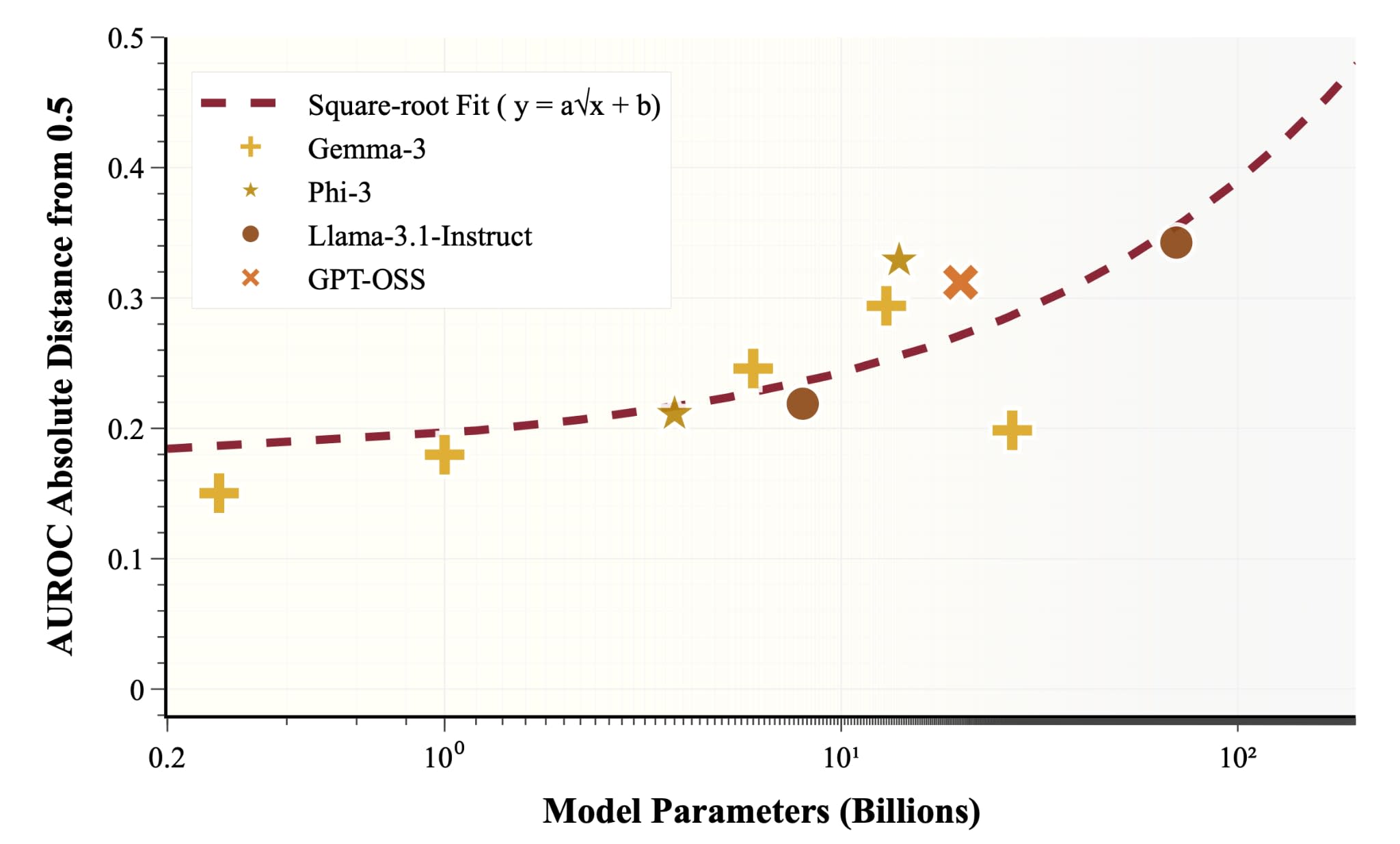
This paper presents evidence that the language LLMs use when describing themselves (self-referential expressions) is not mere confabulation, but actually corresponds to their internal activation states.
Proposes a Pull Methodology to induce introspection. During self-referential processing, specific activation directions emerge, distinguishable from general descriptive processing. Use of certain words (e.g., "loop", "shimmer") statistically corresponds to changes in internal activation patterns (increased autocorrelation, variability).
When Models Examine Themselves: Vocabulary-Activation Correspondence in Self-Referential Processing
Large language models produce rich introspective language when prompted for self-examination, but whether this language reflects internal computation or sophisticated confabulation has remained unclear. We show that self-referential vocabulary tracks concurrent activation dynamics, and that this correspondence is specific to self-referential processing. We introduce the Pull Methodology, a protocol that elicits extended self-examination through format engineering, and use it to identify a direction in activation space that distinguishes self-referential from descriptive processing in Llama 3.1. The direction is orthogonal to the known refusal direction, localised at 6.25% of model depth, and causally influences introspective output when used for steering. When models produce "loop" vocabulary, their activations exhibit higher autocorrelation (r = 0.44, p = 0.002); when they produce "shimmer" vocabulary under steering, activation variability increases (r = 0.36, p = 0.002). Critically, the same vocabulary in non-self-referential contexts shows no activation correspondence despite nine-fold higher frequency. Qwen 2.5-32B, with no shared training, independently develops different introspective vocabulary tracking different activation metrics, all absent in descriptive controls. The findings indicate that self-report in transformer models can, under appropriate conditions, reliably track internal computational states.
https://zenodo.org/records/18614770
Experiential Reinforcement Learning
using introspection (textual reflection) not merely as inference-time improvement, but making reflection as memory into a "behavior modification operator", and internalizing model improvement
arxiv.org
https://arxiv.org/pdf/2602.13949