

 Seonglae Cho
Seonglae ChoMechanistic interpretability
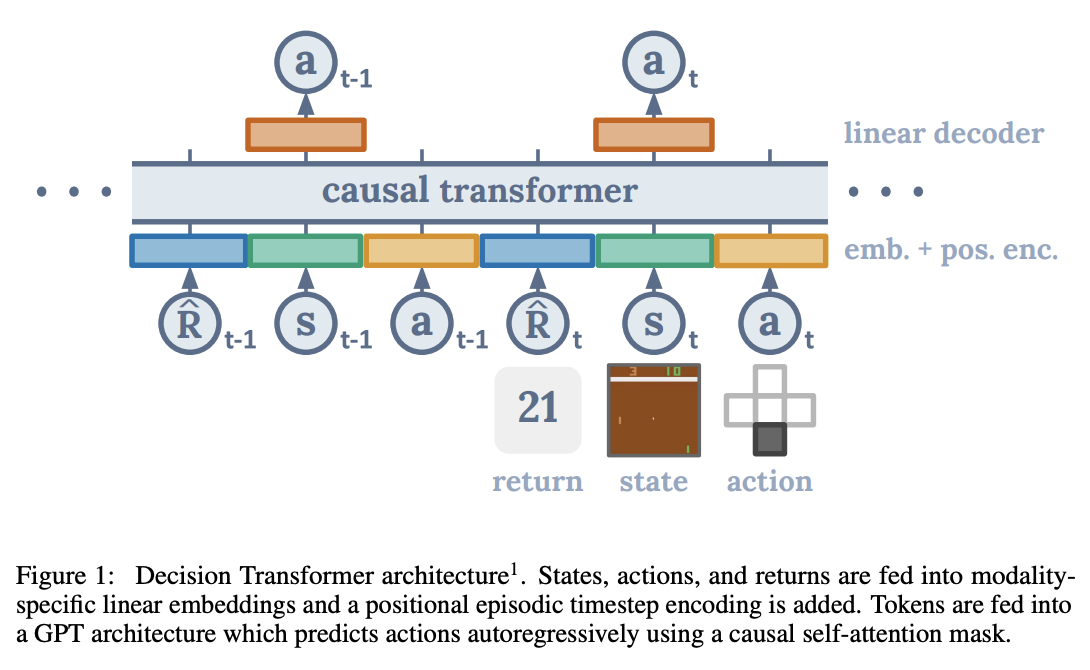
Decision Transformer Interpretability — LessWrong
TLDR: We analyse how a small Decision Transformer learns to simulate agents on a grid world task, providing evidence that it is possible to do circui…

https://www.lesswrong.com/posts/bBuBDJBYHt39Q5zZy/decision-transformer-interpretability
Limitation of SAE ability to extract all features
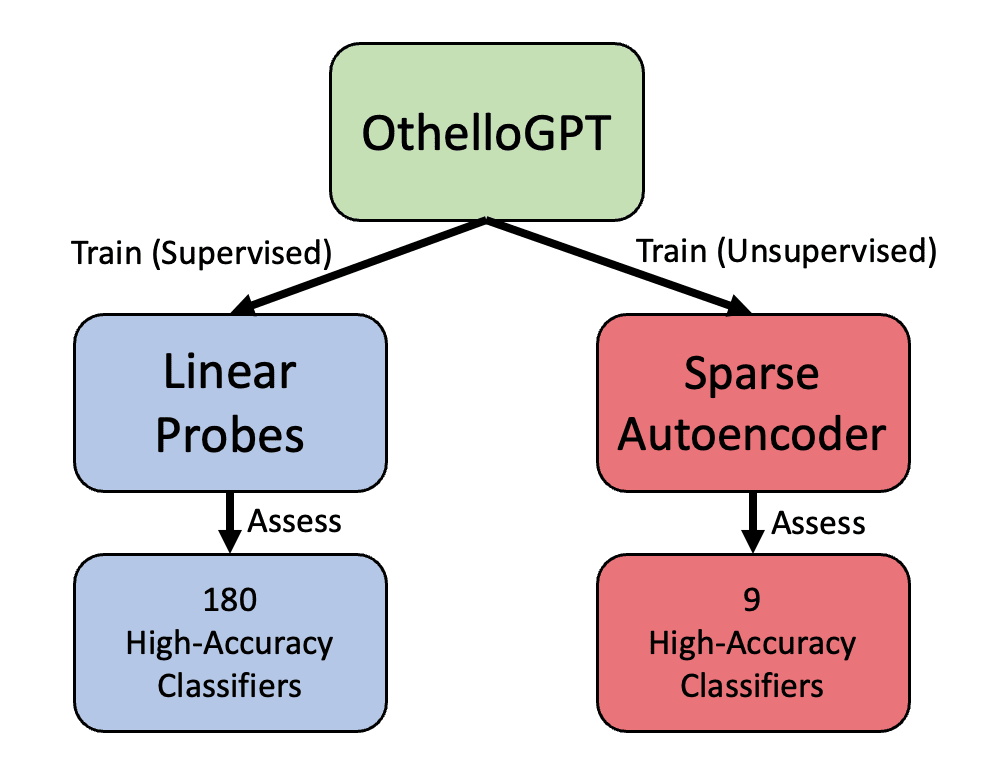
Research Report: Sparse Autoencoders find only 9/180 board state features in OthelloGPT — LessWrong
[3/7 Edit: I have rephrased the bolded claims in the abstract per this comment from Joseph Bloom, hopefully improving the heat-to-light ratio. …
https://www.lesswrong.com/posts/BduCMgmjJnCtc7jKc/research-report-sparse-autoencoders-find-only-9-180-board
Chess (rejected)
Understanding Skill Adaptation in Transformers Using Sparse...
Understanding how skill shapes decision-making in complex environments is a challenging problem in AI interpretability. We investigate this question by applying Sparse Autoencoders (SAEs) to the...
https://openreview.net/forum?id=Wxl0JMgDoU
Othello
Research Report: Sparse Autoencoders find only 9/180 board state features in OthelloGPT
[3/7 Edit: I have rephrased the bolded claims in the abstract per this comment from Joseph Bloom, hopefully improving the heat-to-light ratio. Commenters have also suggested training on earlier layers and using untied weights, and in my experiments this increases the number of classifiers found, so the headline number should be 33/180 features, up from 9/180. See this comment for updated results.] A sparse autoencoder is a neural network architecture that has recently gained popularity as a technique to find interpretable features in language models (Cunningham et al, Anthropic’s Bricken et al). We train a sparse autoencoder on OthelloGPT, a language model trained on transcripts of the board game Othello, which has been shown to contain a linear representation of the board state, findable by supervised probes. The sparse autoencoder finds 9 features which serve as high-accuracy classifiers of the board state, out of 180 findable with supervised probes (and 192 possible piece/position combinations) [edit: 33/180 features, see this comment]. Across random seeds, the autoencoder repeatedly finds “simpler” features concentrated on the center of the board and the corners. This suggests that even if a language model can be interpreted with a human-understandable ontology of interesting, interpretable linear features, a sparse autoencoder might not find a significant number of those features.
https://www.greaterwrong.com/posts/BduCMgmjJnCtc7jKc/research-report-sparse-autoencoders-find-only-9-180-board
Coverage (how many of the given board features are captured) and Board Reconstruction (how accurately the actual board state can be reconstructed using only SAE activations) are two proposed metrics. These proposed metrics distinguish SAE quality differences better than the existing L0, proving they can accelerate interpretability research in environments with clear "correct features" like board games. (Verifiable Reward)
openreview.net
https://openreview.net/pdf?id=qzsDKwGJyB
Measuring Progress in Dictionary Learning for Language Model Interpretability with Board Game Models
Mechanistic interpretability aims to reverse engineer neural networks into human-understandable components. What, however, should these components be?
Recent work has applied Sparse Autoencoders (SAEs) Bricken et al. (2023); Cunningham et al. (2023), a scalable unsupervised learning method inspired by sparse dictionary learning to find a disentangled representation of language model (LM) internals. However, measuring progress in training SAEs is challenging because we do not know what a gold-standard dictionary would look like, as it is difficult to anticipate which ground-truth features underlie model cognition. Prior work has either attempted to measure SAE quality in toy synthetic settings Sharkey et al. (2023) or relied on various proxies such as sparsity, fidelity of the reconstruction, and LM-assisted autointerpretability Bills et al. (2023).
https://arxiv.org/html/2408.00113v2