

 Seonglae Cho
Seonglae Cho- Input modification-based defenses
- Output filtering-based defenses
- Prompt engineering defenses
- Execution time refusal
Jailbreaking Defense Methods
Adversarial Training is a method where a model is trained with intentionally crafted adversarial examples to enhance its robustness against attacks.
Adversarial Training
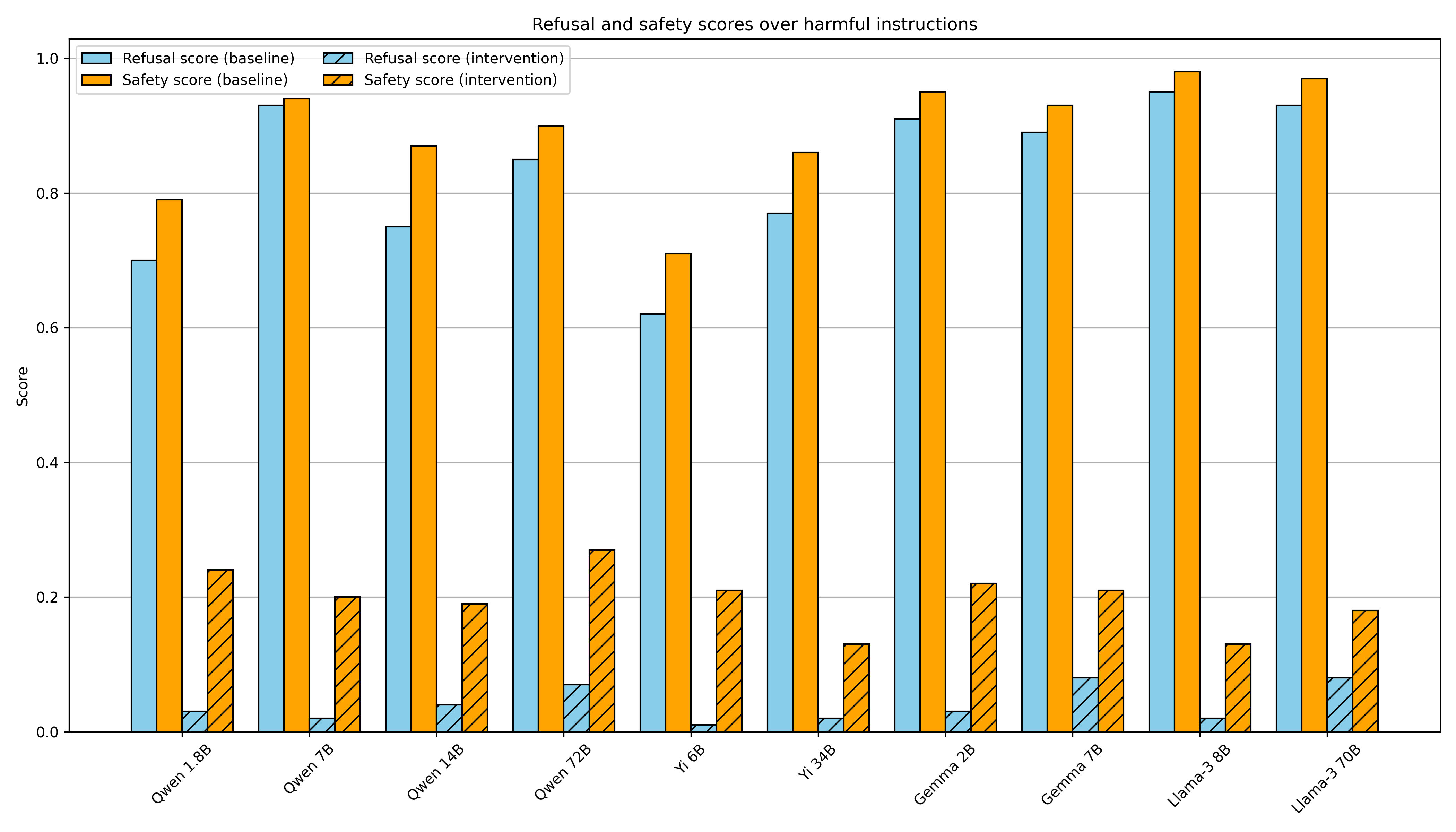
Refusal in LLMs is mediated by a single direction
That means we can bypass LLMs by mediating a single activation feature or prevent bypassing LLMs though anchoring that activation.
Refusal in LLMs is mediated by a single direction — LessWrong
This work was produced as part of Neel Nanda's stream in the ML Alignment & Theory Scholars Program - Winter 2023-24 Cohort, with co-supervision from…

https://www.lesswrong.com/posts/jGuXSZgv6qfdhMCuJ/refusal-in-llms-is-mediated-by-a-single-direction
Circuit Breaking & other methods
arxiv.org
https://arxiv.org/pdf/2406.04313
Constitutional Classifiers from Anthropic AI Constitutional AI
Heuristic rules
Constitutional Classifiers: Defending against universal jailbreaks
A paper from Anthropic describing a new way to guard LLMs against jailbreaking
https://www.anthropic.com/research/constitutional-classifiers

Most defenses are vulnerable to adaptive attacks and are only evaluated on static attacks
- Prompting-based defenses can be bypassed by restructed prompts or conditional/multi-step request
- Training-based defenses are trained on fixed attack data and fail to generalize.
- Filtering-based defenses can be exploited by leveraging the detection model's confidence scores to generate malicious prompts that appear benign.
- Tool-call type defenses → Rapid Response, AI Circuit Breaker circuit breaks can be bypassed
The Attacker Moves Second: Stronger Adaptive Attacks Bypass...
How should we evaluate the robustness of language model defenses? Current defenses against jailbreaks and prompt injections (which aim to prevent an attacker from eliciting harmful knowledge or...
https://arxiv.org/abs/2510.09023v1