

 Seonglae Cho
Seonglae ChoDiT
Diffusion loss is applied to image tokens.
Embedding inversion via conditional masked diffusion
Embedding Inversion via Conditional Masked Diffusion Language Models
We frame embedding inversion as conditional masked diffusion, recovering all tokens in parallel through iterative denoising rather than sequential autoregressive generation. A masked diffusion...
https://arxiv.org/abs/2602.11047
Language Models are Injective and Hence Invertible
Transformer components such as non-linear activations and normalization are inherently non-injective, suggesting that different inputs could map to the same output and prevent exact recovery of...
https://arxiv.org/abs/2510.15511
BERT/MLM is essentially a special form of text diffusion model, and by adding a masking schedule and iterative denoising, it can be used as a complete generative language model.
BERT (especially RoBERTa) is originally an encoder model that performs MLM (masked token recovery). However, by reinterpreting it as a discrete text diffusion process where the masking ratio changes like time steps, it can be transformed into a full generative model. By training with varying masking ratios from 0% to 100%, BERT can also generate text in a diffusion manner. By adding only variable masking and iterative denoising to RoBERTa and fine-tuning on WikiText, quite natural sentence generation was successfully achieved.
BERT is just a Single Text Diffusion Step
This article appeared on Hacker News. Link to the discussion here. A while back, Google DeepMind unveiled Gemini Diffusion, an experimental language model that generates text using diffusion. Unlike traditional GPT-style models that generate one word at a time, Gemini Diffusion creates whole blocks of text by refining random noise step-by-step. I read the paper Large Language Diffusion Models and was surprised to find that discrete language diffusion is just a generalization of masked language modeling (MLM), something we’ve been doing since 2018. The first thought I had was, “can we finetune a BERT-like model to do text generation?” I decided to try a quick proof of concept out of curiosity.

https://nathan.rs/posts/roberta-diffusion/
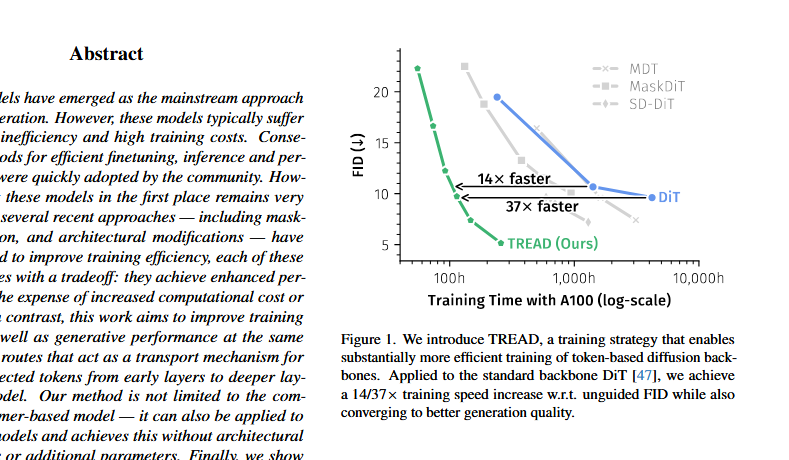
TREAD
All tokens use the same diffusion loss per image token. However, this means each token has a different loss, which breaks the gradual denoising assumption of diffusion. So shouldn't we just apply diffusion loss to all image tokens? Instead of discarding thread tokens, let's temporarily route them through a different path (routing). All tokens receive diffusion loss.
サメQCU on Twitter / X
bros, DiT is wrong.it's mathematically wrong.it's formally wrong. there is something wrong with it pic.twitter.com/OQZ8IcQfnA— サメQCU (@sameQCU) August 17, 2025
https://x.com/sameQCU/status/1957223774094585872
Traditional DiT (=Diffusion Transformer) relies on outdated VAE encoders → low-dimensional (latent 4ch), complex structure, weak expressiveness. Instead of VAE, using pre-trained representation encoders (DINO, MAE, SigLIP, etc.) + lightweight decoder combination = Representation Autoencoder (RAE). L1+GAN+LPIPS loss
arxiv.org
https://arxiv.org/pdf/2510.11690