

 Seonglae Cho
Seonglae ChoModality determines the type of data contained in a data point
Information integration or exchanging across Vision, Text, Speech, Touch, Smell from diverse sensors unlike unimodal AI
Multimodal AI Models
Multimodal AI Notion
CS224n
Stanford CS 224N | Natural Language Processing with Deep Learning
Note: In the 2023–24
academic year, CS224N will be taught in both Winter and
Spring 2024. We hope to see you in class!
https://web.stanford.edu/class/cs224n/
Notion
Multimodality and Large Multimodal Models (LMMs)
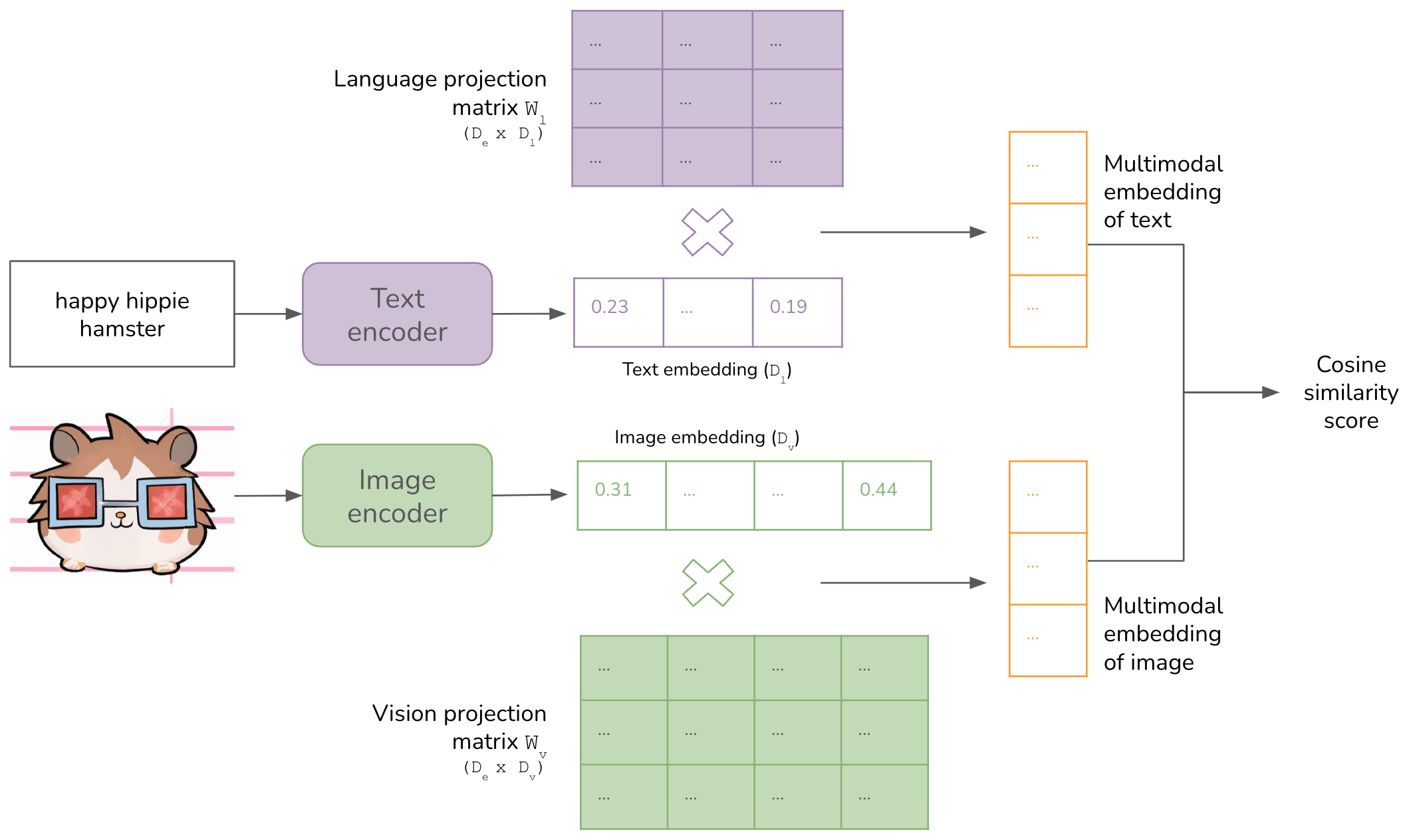
For a long time, each ML model operated in one data mode – text (translation, language modeling), image (object detection, image classification), or audio (speech recognition).
https://huyenchip.com/2023/10/10/multimodal.html
What Is Multimodal AI?
Applications, Principles, and Core Research Challenges in Multimodal AI
.svg)
https://app.twelvelabs.io/blog/what-is-multimodal-ai

[미라클레터] 인공지능이 하나가 된다 ?!?
미라클 모닝을 하는 일잘러들의 '참고서'
https://stibee.com/api/v1.0/emails/share/Ue8q7jhsWwUJw3s7XtO19eGpnGJDUJ4=
![[미라클레터] 인공지능이 하나가 된다 ?!?](https://www.notion.so/image/https%3A%2F%2Fs3.ap-northeast-2.amazonaws.com%2Fimg.stibee.com%2F11584_1649039620.png?table=block&id=fd0f79df-7454-4076-adbc-b8285c74f613&cache=v2)
thegenerality.com
https://thegenerality.com/agi/?fbclid=IwAR3aPmwPe6CC7INiPtKlq3SxShfP_-l4LsfvCmS-I6ChQgIAl5qfuQLz_YE
UX
Multi-Modal AI is a UX Problem
Transformers and other AI breakthroughs have shown state-of-the-art performance across different modalities * Text-to-Text (OpenAI ChatGPT) * Text-to-Image (Stable Diffusion) * Image-to-Text (Open AI CLIP) * Speech-to-Text (OpenAI Whisper) * Text-to-Speech (Meta’s Massively Multilingual Speech) * Image-to-Image (img2img or pix2pix) * Text-to-Audio (Meta MusicGen) * Text-to-Code (OpenAI Codex / GitHub Copilot) * Code-to-Text (ChatGPT, etc.) The next frontier in AI is combining these mo
https://matt-rickard.com/multi-modal-ai-is-a-ux-problem