

 Seonglae Cho
Seonglae ChoLLaMA2 Implementations
From GPT
- Replacing LayerNorm with RMSNorm
- Switching from GELU to SiLU activation
- Implementing rotary position embeddings (RoPE)
- Updating the FeedForward module with SwiGLU
- Loading and using pretrained Llama 2 weights
- Adapting the tokenizer for Llama 2
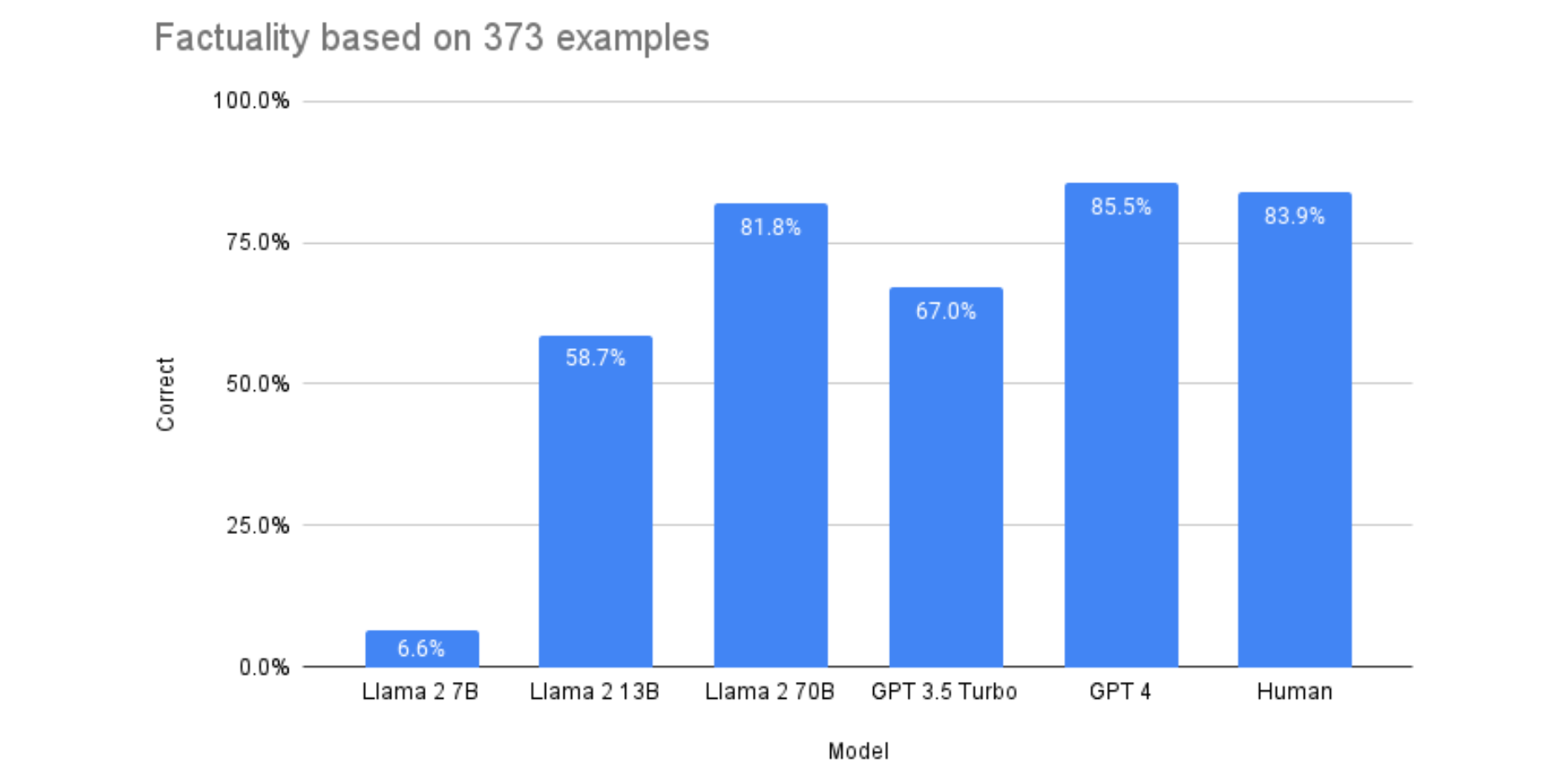
Llama 2 is about as factually accurate as GPT-4 for summaries and is 30X cheaper | Anyscale
From the creators of Ray, Anyscale is a framework for building machine learning applications at any scale originating from the UC Berkeley RISELab.
https://www.anyscale.com/blog/llama-2-is-about-as-factually-accurate-as-gpt-4-for-summaries-and-is-30x-cheaper
Why Did Meta Open-Source Llama 2?
Llama 2 is a commercially-available open-source model from Meta that builds on LLaMA, the “academic-use only” model that was, in reality, generally available to anyone who could click a download link. At a high level, many are familiar with strategic open-source from big technology companies — products like Android, Chrome, and Visual Studio Code. But why exactly would Meta make the weights of the Llama 2 commercially available? A more in-depth analysis. The framework in A Short Taxonomy of Op
https://matt-rickard.com/why-did-meta-open-source-llama
meta-llama (Meta Llama 2)
Org profile for Meta Llama 2 on Hugging Face, the AI community building the future.
https://huggingface.co/meta-llama
