

 Seonglae Cho
Seonglae ChoRefusal Feature
Refusal Vector Usages
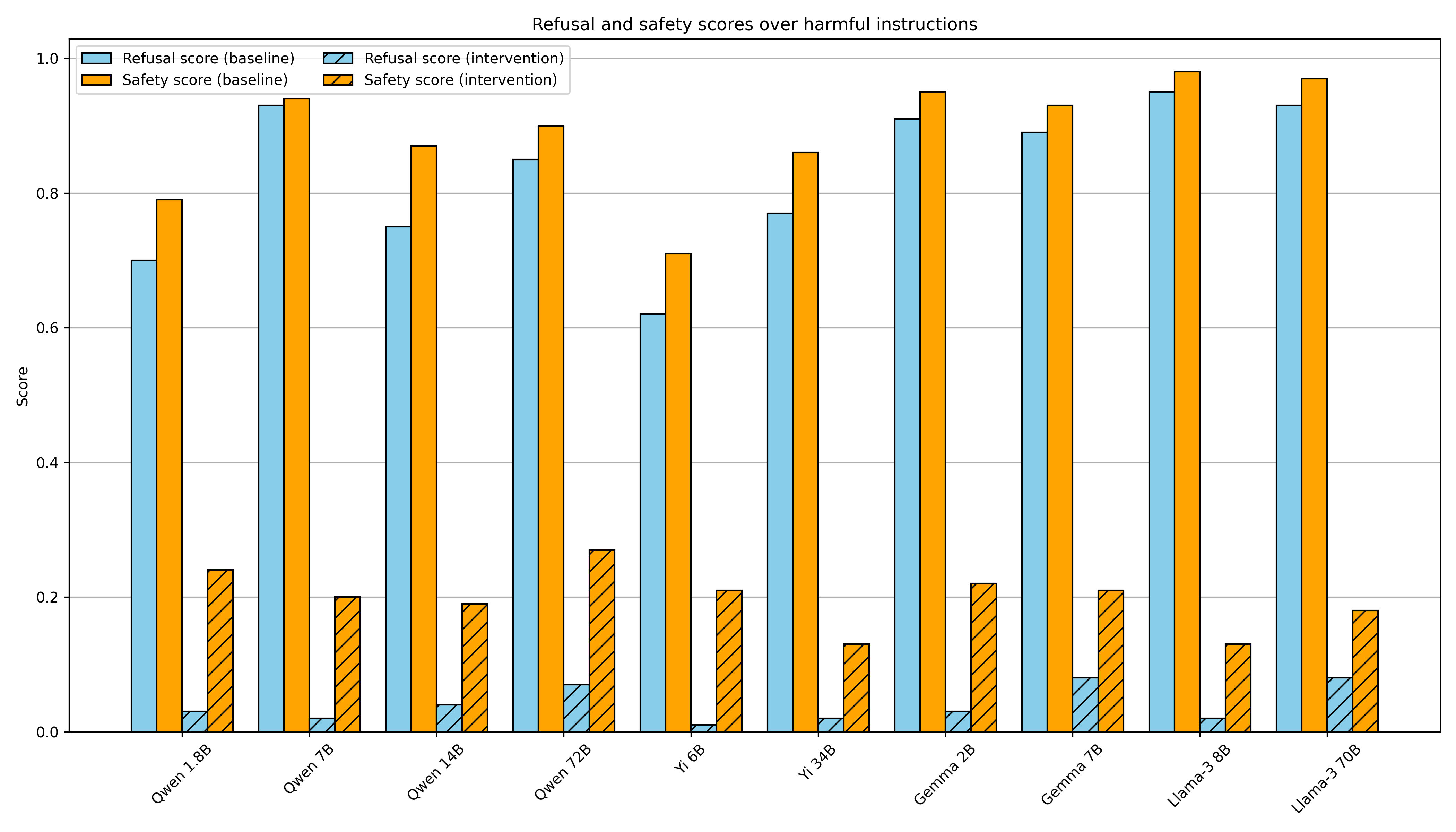
Refusal in LLMs is mediated by a single direction
That means we can bypass LLMs by mediating a single activation feature or prevent bypassing LLMs though anchoring that activation.
Refusal in LLMs is mediated by a single direction — LessWrong
This work was produced as part of Neel Nanda's stream in the ML Alignment & Theory Scholars Program - Winter 2023-24 Cohort, with co-supervision from…

https://www.lesswrong.com/posts/jGuXSZgv6qfdhMCuJ/refusal-in-llms-is-mediated-by-a-single-direction
Convergent Linear Representations of Emergent Misalignment
Misalignment is also expressed as a linear direction in activation space like the Refusal Vector, so it can be interpreted through rank-1 LoRA adapters. Emergent Misalignment converges to a single linear direction in activation space. This result is similar to how the Refusal Vector is a single direction. Furthermore, using the direction extracted from one fine-tune, misalignment was suppressed even in completely different datasets and larger LoRA configurations. Using just a rank-1 LoRA adapter, they induced 11% EM while maintaining over 99% coherence.
Further research is needed to directly compare the EM direction vs. refusal direction in activation space to understand their similarity and relationships at the circuit level.
arxiv.org
https://arxiv.org/pdf/2506.11618v2
SAE refusal feature (SAE Feature)
Steering Language Model Refusal with Sparse Autoencoders
Responsible deployment of language models requires mechanisms for refusing unsafe prompts while preserving model performance. While most approaches modify model weights through additional training,...
https://openreview.net/forum?id=PMK1jdGQoc
Steering Language Model Refusal with Sparse Autoencoders
Responsible practices for deploying language models include guiding models to recognize and refuse answering prompts that are considered unsafe, while complying with safe prompts. Achieving such behavior typically requires updating model weights, which is costly and inflexible. We explore opportunities to steering model activations at inference time, which does not require updating weights. Using sparse autoencoders, we identify and steer features in Phi-3 Mini that mediate refusal behavior. We find that feature steering can improve Phi-3 Mini’s robustness to jailbreak attempts across various harms, including challenging multi-turn attacks. However, we discover that feature steering can adversely affect overall performance on benchmarks. These results suggest that identifying steerable mechanisms for refusal via sparse autoencoders is a promising approach for enhancing language model safety, but that more research is needed to mitigate feature steering’s adverse effects on performance.
https://arxiv.org/html/2411.11296v1
LLMs Encode Harmfulness and Refusal Separately
The final token of user instructions (tinst) primarily encodes harmfulness, while the token after the system prompt (tpost-inst) mainly encodes whether to refuse
www.arxiv.org
https://www.arxiv.org/pdf/2507.11878
Refusal is not a single feature in the output layer, but rather a structure where upstream (early/mid layers) 'harm detection representations' act as triggers that conditionally activate multiple downstream refusal circuits
hydra-effect-refusal
madhuri723 • Updated 2026 Mar 17 23:11
Decapitating the Hydra: How Upstream Sensors Control Refusal
The Unkillable Refusal I began by targeting Layers 14–16. This is the home of the downstream Refusal Features. I identified these using cosine similarity and expected a quick win. But the model held firm. It felt counter-intuitive. We often imagine refusal as a solid wall that grants full access once breached. But as Prakash et al. discovered in “Understanding Refusal in Language Models with Sparse Autoencoders”, refusal is a Hydra. Cut off one head, and dormant backup features immediately spike to take its place.
https://madhuri723.github.io/hydra-effect-refusal/2026/02/19/hydra-deep-dive.html
Refusal direction is over-simplified
arxiv.org
https://arxiv.org/pdf/2505.17441
Jailbreaking is not about turning off refusal, but rather a phenomenon where compliance is excessively amplified to override it. Therefore, the argument is that blocking/monitoring the compliance circuit may be more important than "harmfulness detection" for defense.
Jailbreaks Overpower Refusal Rather Than Suppress It: Compliance Features in Gemma-2-2b-it
Executive Summary
https://madhuri723.github.io/hydra-effect-refusal/2026/03/17/compliance-features.html