

 Seonglae Cho
Seonglae ChoEmbedding inversion via conditional masked diffusion
Embedding Inversion via Conditional Masked Diffusion Language Models
We frame embedding inversion as conditional masked diffusion, recovering all tokens in parallel through iterative denoising rather than sequential autoregressive generation. A masked diffusion...
https://arxiv.org/abs/2602.11047
Language Models are Injective and Hence Invertible
Transformer components such as non-linear activations and normalization are inherently non-injective, suggesting that different inputs could map to the same output and prevent exact recovery of...
https://arxiv.org/abs/2510.15511
Residual Stream is thought as a communication channel, since it doesn't do any processing itself and all layers communicate through it. The residual stream has a deeply linear structure without privileged basis. we could rotate it by rotating all the matrices interacting with it, without changing model behavior.
Once added, information persists in a subspace unless another layer actively deletes it. From this perspective, dimensions of the residual stream become something like "memory" or "bandwidth”. The residual stream is high dimensional, and can be divided into different Subspaces. Layers can interact by writing to and reading from the same or overlapping subspaces. If they write to and read from Disjoint vector space, they will not interact. Typically the spaces only partially overlap. Layers can delete the residual stream by reading in a subspace and then writing the negative version.
Bottleneck activation
We say that an activation is a bottleneck activation if it is a lower-dimensional intermediate between two higher dimensional activations. For example, the residual stream is a bottleneck activation because it is the only way to pass information between MLP activations, which are typically four times larger than it.
For example, at layer 25 of a 50 layer transformer, the residual stream has 100 times more neurons as it has dimensions before it, trying to communicate with 100 times as many neurons as it has dimensions after it, somehow communicating in Superposition Hypothesis! We call tensors like this bottleneck activation. Similarly, a value vector is a bottleneck activation because it’s much lower dimensional than the residual stream, and it’s the only way to move information from the residual stream for one token position in the context to another.
Perhaps because of this high demand on residual stream bandwidth, we've seen hints that some MLP neurons and attention heads may perform a kind of "memory management" role, clearing residual stream dimensions set by other layers by reading in information and writing out the negative version. (This is one theory)
The capital of France is → Attention/FFN activated capitals/cities
Subvalue means activation in this context not weight
- The distribution change of residual connections in vocabulary space caused by a direct addition function on before-softmax values.
- Log probability increase as contribution score could help locate important subvalues.
- Attention/FFN subvalues on previous layers are direct “queries” to activate upper FFN subvalues by inner products.
Residual Stream Notion
Virtual weights
These virtual weights are the product of the output weights of one layer with the input weights.


Privileged basis
Some dimensions show higher importance or activity than expected, appearing more Privileged than other dimensions. The basis directions should be in some sense "arbitrary" and no more likely to encode information than random directions). Recent work has shown that this observation is false in practice. For the computation inside of each layer, we observe heavy-tailed activations inside the computation basis, but not in the residual stream.
The design of the transformer does not favor specific dimensions in information encoding, so such privilege-based discoveries contradict the assumption of uniformity in the distribution of information within the model.
Optimizers like the Adam Optimizer that manage momentum by dimension can make certain dimensions learn faster than others.
When Anthropic train a Transformer with a different basis for the residual stream and for the computation inside of each layer, Anthropic observe heavy-tailed activations inside the computation basis, but not in the residual stream.
Anthropic explore two other obvious sources of basis dependency in a Transformer: Layer normalization, and finite-precision floating-point calculations. Anthropic confidently rule these out as being the source of the observed basis-alignment.
However, Transformers do not rely on a privileged basis to train and function properly, even when floating-point precision is taken into account
Viewer
Very briefly, the tool lets you see what the dot product of the residual stream at each token is with a particular direction.

2023 July
Really Strong Features Found in Residual Stream — LessWrong
[I'm writing this quickly because the results are really strong. I still need to do due diligence & compare to baselines, but it's really exciting!] …

https://www.lesswrong.com/posts/Q76CpqHeEMykKpFdB/really-strong-features-found-in-residual-stream

2023 March
Privileged Bases in the Transformer Residual Stream
Our mathematical theories of the Transformer architecture suggest that individual coordinates in the residual stream should have no special significance (that is, the basis directions should be in some sense "arbitrary" and no more likely to encode information than random directions). Recent work has shown that this observation is false in practice. We investigate this phenomenon and provisionally conclude that the per-dimension normalizers in the Adam optimizer are to blame for the effect.
https://transformer-circuits.pub/2023/privileged-basis/index.html
tinyurl.com
https://tinyurl.com/resid-viewer
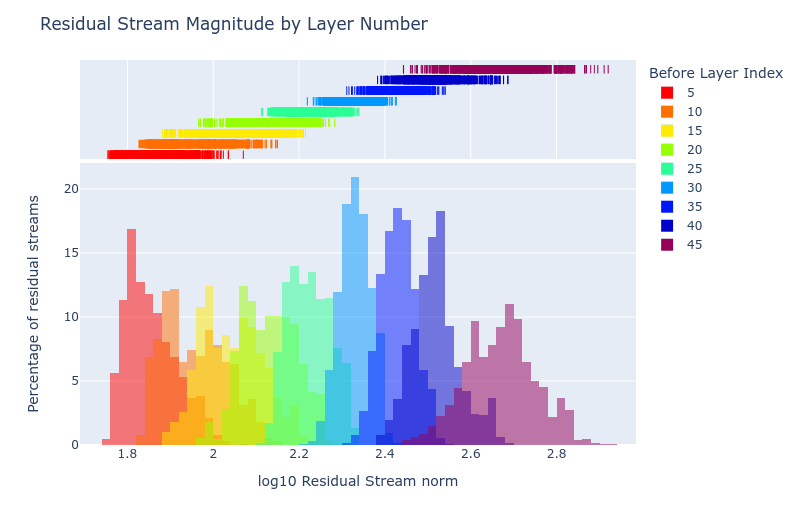
Residual stream norms grow exponentially over the forward pass — AI Alignment Forum
Summary: For a range of language models and a range of input prompts, the norm of each residual stream grows exponentially over the forward pass, wit…

https://www.alignmentforum.org/posts/8mizBCm3dyc432nK8/residual-stream-norms-grow-exponentially-over-the-forward
2023 Dec
Exploring the Residual Stream of Transformers for Mechanistic Interpretability — Explained
— by Zeping Yu, Dec 24, 2023

https://medium.com/@zepingyu/123-cb62513f5d50

arxiv.org
https://arxiv.org/pdf/2312.12141.pdf
Residual stream embeddings tend to align with important tokens in the input sentence
arxiv.org
https://arxiv.org/pdf/2406.17378
Invertibility of the Activation
- Embedding inversion via conditional masked diffusion
- Language model's residual stream
Embedding Inversion via Conditional Masked Diffusion Language Models
We frame embedding inversion as conditional masked diffusion, recovering all tokens in parallel through iterative denoising rather than sequential autoregressive generation. A masked diffusion...
https://arxiv.org/abs/2602.11047
Language Models are Injective and Hence Invertible
Transformer components such as non-linear activations and normalization are inherently non-injective, suggesting that different inputs could map to the same output and prevent exact recovery of...
https://arxiv.org/abs/2510.15511