

 Seonglae Cho
Seonglae ChoThe superposition hypothesis postulates that neural networks “want to represent more features than they have neurons”.
It is consistent with the fact that actual brain activation does not occur all at once, in that only some of the model's neurons are used to prevent overlapping between superposed functions. The idea that we only use 10% of our brain's capacity came about because there was no understanding of superposition, but in reality, using it that way would render it meaningless.
Cross entropy loss verification
We can calculate the cross-entropy loss achieved by this model in a few cases:
- Suppose the neuron only fires on feature A, and correctly predicts token A when it does. The model ignores all of the other features, predicting a uniform distribution over tokens B/C/D when feature A is not present. In this case the loss is
- Instead suppose that the neuron fires on both features A and B, predicting a uniform distribution over the A and B tokens. When the A and B features are not present, the model predicts a uniform distribution over the C and D tokens. In this case the loss is
Models trained on cross-entropy loss will generally prefer to represent more features polysemantically than to represent monosemantically even in cases where sparsity constraints make superposition impossible. Models trained on other loss functions do not necessarily suffer this problem. This is the reason why Sparse Autoencoder use MSE reconstruction loss and sparsity loss to make monosemantic latent dictionary.
Interference in Residual Stream
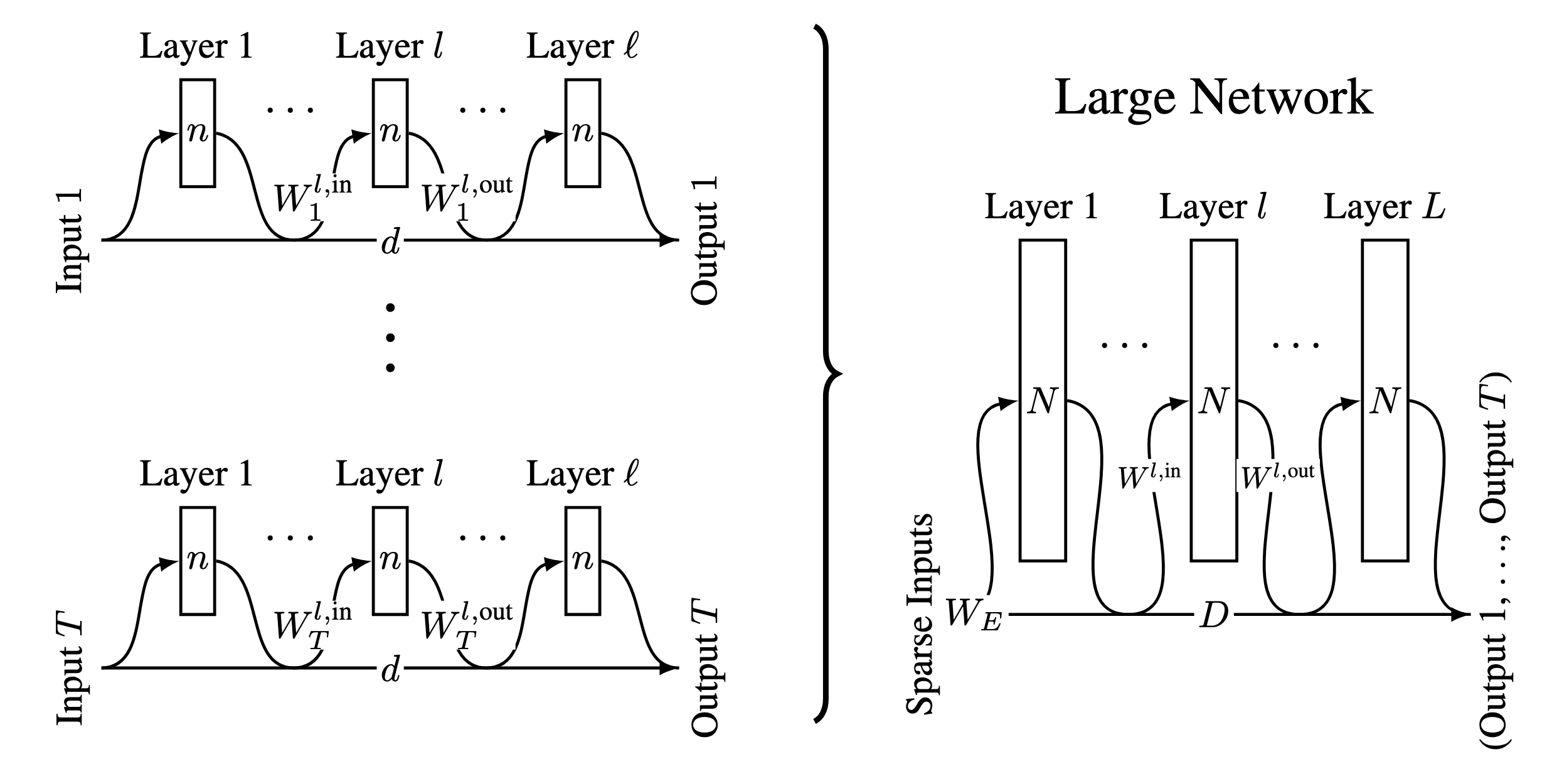
Compressing many small neural network into one
- Read-in interference
- Read-out interference
Superposition Hypothesis Notion
Compression
Because the loss is lower in case (2) than in case (1), the model achieves better performance by making its sole neuron polysemantic, even though there is no superposition.

The feature activations should be *sparse*, because sparsity is what enables this kind of noisy simulation. (Compressed sensing)
It trained with 2 features and 1 activation relu, they were divided antipodally. As expected, sparsity is necessary for superposition to occur


The implementation of the connection to something that should come to mind along with the corresponding memory can be interpreted as a form of superposition. Additionally, the need for a backup neuron due to Dropout is also one interpretation.
Architectural approach
There are highlighted several different approaches to solving superposition. One of those approaches was to engineer models to simply not have superposition in the first place.

It is generally accepted that in 10 dimensions, you can use 10 orthogonal bases, but in fact, as shown above, you can use 5 bases in 2 dimensions. Even with some interference.
But it isn't always the case that features correspond so cleanly to neurons, especially in large language models where it actually seems rare for neurons to correspond to clean features.
In this paper, Anthropic uses toy models — small ReLU networks trained on synthetic data with sparse input features. When features are sparse, superposition allows compression beyond what a linear model would do, at the cost of "interference" that requires nonlinear filtering.
- Superposition is a real, observed phenomenon.
- Both monosemantic and polysemantic neurons can form.
- At least some kinds of computation can be performed in superposition.
- Whether features are stored in superposition is governed by a phase change.
- Superposition organizes features into geometric structures
Phase change

If we make it sufficiently sparse, there's a phase change, and it collapses from a pentagon to a pair of digons with the sparser point at zero. The phase change corresponds to loss curves corresponding to the two different geometries crossing over
A more complicated form of non-uniform superposition occurs when there are correlations between features. This seems essential for understanding superposition in the real world, where many features are correlated or anti-correlated.

Phase change for In-context learning
Induction heads may be the mechanistic source of general in-context learning in transformer models of any size
Phase change occurs early in training for language models of every size (provided they have more than one layer), and which is visible as a bump in the training loss. During this phase change, the majority of in-context learning ability (as measured by difference in loss between tokens early and late in the sequence) is acquired, and simultaneously induction heads form within the model that are capable of implementing fairly abstract and fuzzy versions of pattern completion.

Perhaps the most striking phenomenon the Anthropic have noticed is that the learning dynamics of toy models with large numbers of features appear to be dominated by "energy level jumps" where features jump between different feature dimensionalities.

Thought vector (2016, Gabriel Goh)
Decoding the Thought Vector
Neural networks have the rather uncanny knack for turning meaning into numbers. Data flows from the input to the output, getting pushed through a series of transformations which process the data into increasingly abstruse vectors of representations. These numbers, the activations of the network, carry useful information from one layer of the network to the next, and are believed to represent the data at different layers of abstraction. But the vectors themselves have thus far defied interpretation.
https://gabgoh.github.io/ThoughtVectors/
2018 Superposition
Linear Algebraic Structure of Word Senses, with Applications to Polysemy
Word embeddings are ubiquitous in NLP and information retrieval, but it is unclear what they represent when the word is polysemous. Here it is shown that multiple word senses reside in linear...
https://arxiv.org/abs/1601.03764
2021
A Mathematical Framework for Transformer Circuits
Transformer language models are an emerging technology that is gaining increasingly broad real-world use, for example in systems like GPT-3 , LaMDA , Codex , Meena , Gopher , and similar models. However, as these models scale, their open-endedness and high capacity creates an increasing scope for unexpected and sometimes harmful behaviors. Even years after a large model is trained, both creators and users routinely discover model capabilities – including problematic behaviors – they were previously unaware of.
https://transformer-circuits.pub/2021/framework/index.html
2022 Amazing works
In-context Learning and Induction Heads
As Transformer generative models continue to scale and gain increasing real world use , addressing their associated safety problems becomes increasingly important. Mechanistic interpretability – attempting to reverse engineer the detailed computations performed by the model – offers one possible avenue for addressing these safety issues. If we can understand the internal structures that cause Transformer models to produce the outputs they do, then we may be able to address current safety problems more systematically, as well as anticipating safety problems in future more powerful models. Note that mechanistic interpretability is a subset of the broader field of interpretability, which encompasses many different methods for explaining the outputs of a neural network. Mechanistic interpretability is distinguished by a specific focus on trying to systematically characterize the internal circuitry of a neural net.
https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html
Toy Models of Superposition
It would be very convenient if the individual neurons of artificial neural networks corresponded to cleanly interpretable features of the input. For example, in an “ideal” ImageNet classifier, each neuron would fire only in the presence of a specific visual feature, such as the color red, a left-facing curve, or a dog snout. Empirically, in models we have studied, some of the neurons do cleanly map to features. But it isn't always the case that features correspond so cleanly to neurons, especially in large language models where it actually seems rare for neurons to correspond to clean features. This brings up many questions. Why is it that neurons sometimes align with features and sometimes don't? Why do some models and tasks have many of these clean neurons, while they're vanishingly rare in others?
https://transformer-circuits.pub/2022/toy_model/index.html
(2023, Chris Olah) Distributed Representations: Composition & Superposition
Composition and superposition are opposing representational methods, and it is important to distinguish between them (tradeoff). Composition-based representations excel in interpretability and generalization, while superposition-based representations have high spatial efficiency. (Compressed sensing)
Distributed Representations: Composition & Superposition
Distributed representations are a classic idea in both neuroscience and connectionist approaches to AI. We're often asked how our work on superposition relates to it. Since publishing our original paper on superposition, we've had more time to reflect on the relationship between the topics and discuss it with people, and wanted to expand on our earlier discussion in the related work section and share a few thoughts. (We care a lot about superposition and the structure of distributed representations because decomposing representations into independent components is necessary to escape the curse of dimensionality and understand neural networks.)
https://transformer-circuits.pub/2023/superposition-composition/index.html
arxiv.org
https://arxiv.org/pdf/2305.01610
2024
Interference in superposition and how to deal with that
Circuits in Superposition: Compressing many small neural networks into one — LessWrong
Tl;dr: We generalize the mathematical framework for computation in superposition from compressing many boolean logic gates into a neural network, to…

https://www.lesswrong.com/posts/roE7SHjFWEoMcGZKd/circuits-in-superposition-compressing-many-small-neural
singular value decay in logit matrix
Sequences of Logits Reveal the Low Rank Structure of Language Models
A major problem in the study of large language models is to understand their inherent low-dimensional structure. We introduce an approach to study the low-dimensional structure of language models...
https://arxiv.org/abs/2510.24966