

 Seonglae Cho
Seonglae ChoTransformer Interpretability
A transformer starts with a token embedding, followed by a series of residual blocks, and finally a token unembedding
MLPs store factual information and Attention performs pattern matching. Since in transformer models, MLPs are token-wise operations while attention is an inter-token operation
Both the attention and MLP layers each “read” their input from the residual stream (by performing a linear projection), and then “write” their result to the residual stream by adding a linear projection back in.
- Transformers have an enormous amount of linear structure.
- One layer attention-only transformers are an ensemble of bigram and “skip-trigram
- Two layer attention-only transformers can implement much more complex algorithms using compositions of attention heads
When there are many equivalent ways to represent the same computation, it is likely that the most human-interpretable representation and the most computationally efficient representation will be different. Composition of attention heads is the key difference between one-layer and two-layer attention-only transformers
- logit
- token vectot
- embedding matrix
- MLP output
- Attention head
- token unembedding

Fundamentally, if activations in attention appears linearly, then the activation function's non-linearity is a side effect, and like in diffusion models, noise reduction through layers might be the main role.
Reversing Transformer Notion
QK, OV matrix (within single head)
Attention heads can be understood as having two largely independent computations.
The OV and QK matrices are extremely low-rank. Copying behavior is widespread in OV matrices and arguably one of the most interesting behaviors. (for shifting and induction head). One-layer transformer models represent skip-trigrams in a "factored form" split between the OV and QK matrices. It's kind of like representing a function . They can't really capture the three way interactions flexibly.
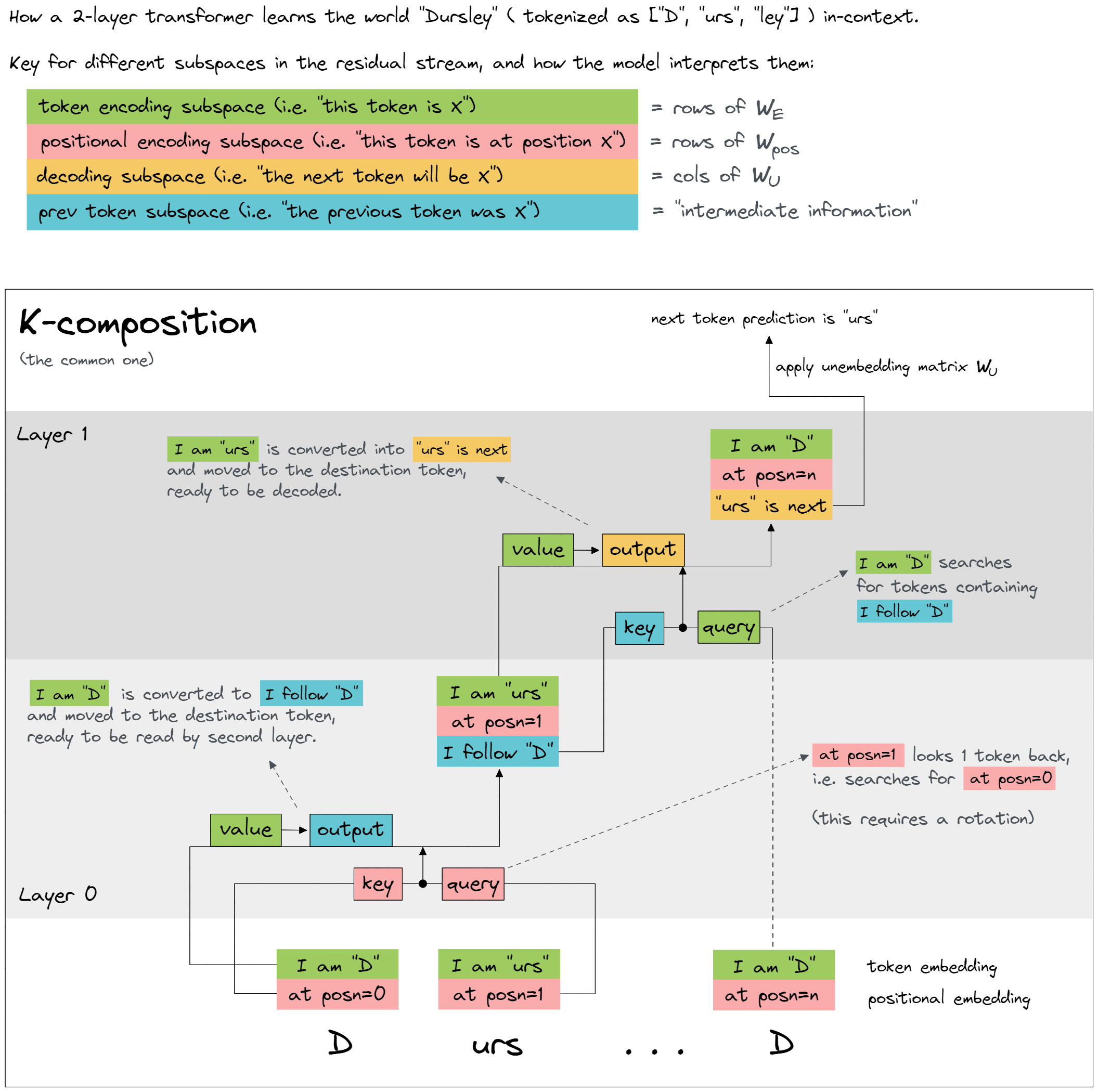
The point to understand about the Circuit is that the tokens are made up of a source and a destination, as follows.

Previous Token Head (source attention) → Induction head (destination attention)
The attention pattern is a function of both the source and destination token, but once a destination token has decided how much to attend to a source token, the effect on the output is solely a function of that source token.
1. QK Circuit
How each attention head's attention pattern is computed (same pattern matching)
- preceding tokens → attended token
In fact, information about the attended token itself is quite irrelevant to calculating the attention pattern for induction. Note that the attended token is only ignored when calculating the attention pattern through the QK-circuit. Attended token is extremely important for calculating the head’s output through the OV-circuit! (The parts of the head that calculate the attention pattern, and the output if attended to, are separable and are often useful to consider independently)
2. OV Circuit
Copying is done by the OV ("Output-Value") circuit.
Transformers seem to have quite a number of copying head (Attention head), of which induction heads are a subset.

Path Expansion Trick for Multi-layer Attention with composition

More complex QK circuit terms can be used to create induction heads which match on more than just the preceding token. The most basic form of an induction head uses pure K-composition with an earlier “previous token head” to create a QK-Circuit term of the form where has positive Eigenvalues. This term causes the induction head to compare the current token with every earlier position's preceding token and look for places where they're similar. More complex QK circuit terms can be used to create induction heads which match on more than just the preceding token.
Although it is not clearly stated in the paper, in the case of a specific form of single layer, or in the case of multi-layer where the latent space residual stream is altered by token embedding or Q,K-composition, the induction head with a similar Eigenvector increases the token distribution probability.
Token Definitions
The QK circuit determines which "source" token the present "destination" token attends back to and copies information from, while the OV circuit describes what the resulting effect on the "out" predictions for the next token is.
[source]... [destination][out]- preceding tokens - attention pattern is a function of all possible source tokens from the start to the destination token.
- source token - attended token is a specific previous token which induction head attended to. Attended token needs to contain information about the preceding tokens from what information is read.
- destination token - current token where information is written
- output token - predicted token which are similar with source token after destination token
Composition
- One layer model copying head:
[b] … [a] → [b] - And when rare quirks of tokenization allow:
[ab] … [a] → [b]
- Two layer model induction head:
[a][b] … [a] → [b]
For the next layer QK-circuit, both Q-composition and K-composition come into play, with previous layer attention heads potentially influencing the construction of the keys and queries
ARENA tutorial for everyone
Home
This GitHub repo hosts the exercises and Streamlit pages for the ARENA 3.0 program.

https://arena3-chapter1-transformer-interp.streamlit.app/

Attention-only transformers, which don't have MLP layers
Because they had much less success in understanding MLP layers so far (2021)
A Mathematical Framework for Transformer Circuits
Transformer language models are an emerging technology that is gaining increasingly broad real-world use, for example in systems like GPT-3 , LaMDA , Codex , Meena , Gopher , and similar models. However, as these models scale, their open-endedness and high capacity creates an increasing scope for unexpected and sometimes harmful behaviors. Even years after a large model is trained, both creators and users routinely discover model capabilities – including problematic behaviors – they were previously unaware of.
https://transformer-circuits.pub/2021/framework/index.html
Induction heads - illustrated — LessWrong
Many thanks to everyone who provided helpful feedback, particularly Aryan Bhatt and Lawrence Chan! …

https://www.lesswrong.com/posts/TvrfY4c9eaGLeyDkE/induction-heads-illustrated#Q_composition
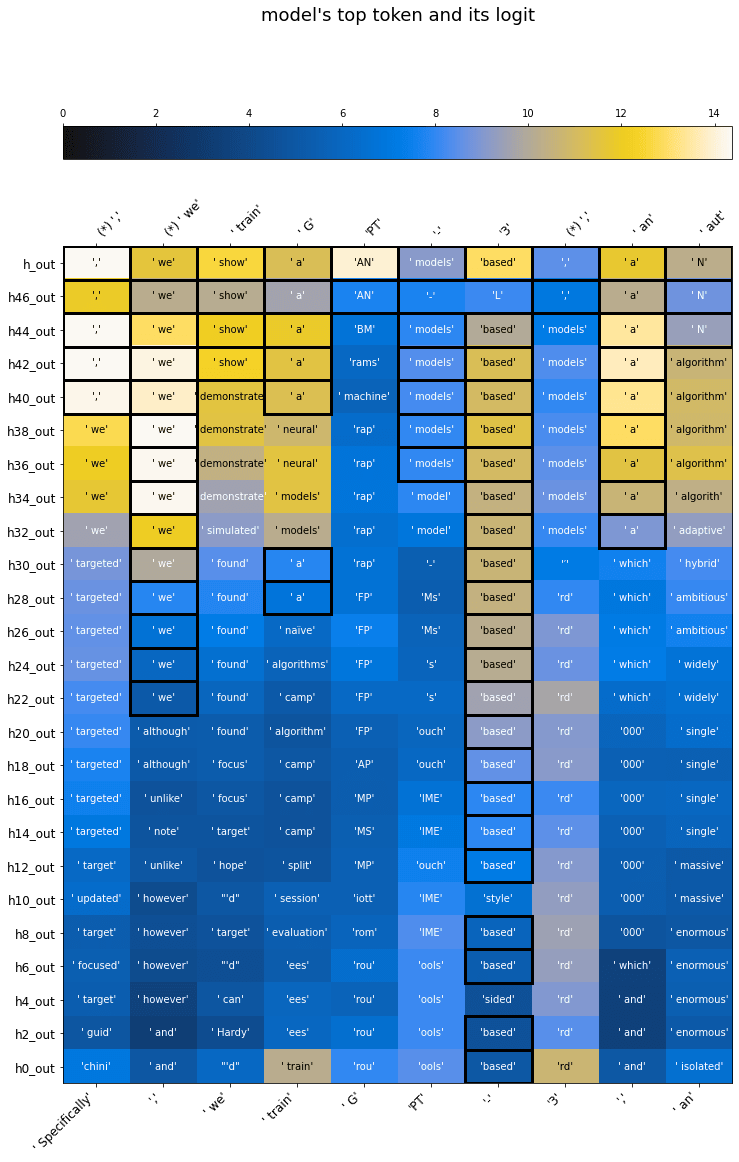
interpreting GPT: the logit lens — LessWrong
This post relates an observation I've made in my work with GPT-2, which I have not seen made elsewhere. …
https://www.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens
arxiv.org
https://arxiv.org/pdf/2405.00208
Handcrafting transformer
Neel Nanda on Twitter / X
My weak guess is that it'll also be doing rotation-y stuff in some base - regular addition is just modular addition if you correct for the rounding! And I think models find it hard to represent things precisely as a direction with highly varying norm.— Neel Nanda (@NeelNanda5) June 20, 2023
https://x.com/NeelNanda5/status/1671094151633305602