


 Seonglae Cho
Seonglae ChoInter-Token Communication mechanism
Starting with the assumption that the latent vector just before a word's output would be similar to the vector right after its input
This technique was introduced to correct the decreased accuracy of output sequences when input sequences become longer, and does not consider order information
Attention is how much weight the query word should give each word in the sentence. This is computed via a dot product between the query vector and all the key vectors. These dot products then go through a softmax which makes the attention scores (across all keys) sum to 1.
- Q - What am I looking for
- K - What do I contain
- V - What I communicate to another token
- Attention Score (through Q, K) attention matrix
- Attention Weight (softmax → attention distribution)
- Attention output is softmax(QK)V
The attention mechanism inherently has an inductive bias toward sparse activation and the Superposition Hypothesis, since it must focus on different tokens depending on the context.
Attention-Mechanism Notion
Attention Mechanism usages
Andrej Karpathy denoted that
- Attention is a communication mechanism. Can be seen as nodes in a directed graph looking at each other and aggregating information with a weighted sum from all nodes that point to them, with data-dependent weights.
- There is no notion of space (position). Attention simply acts over a set of vectors. This is why we need to positionally encode tokens.
- Each example across batch dimension is of course processed completely independently and never "talk" to each other
- In an "encoder" attention block just delete the single line that does masking with
tril, allowing all tokens to communicate. This block here is called a "decoder" attention block because it has triangular masking, and is usually used in autoregressive settings, like language modeling.
- "self-attention" just means that the keys and values are produced from the same source as queries. In "cross-attention", the queries still get produced from x, but the keys and values come from some other, external source (e.g. an encoder module)
- "Scaled" attention additional divides
weiby 1/sqrt(head_size). This makes it so when input Q,K are unit variance, wei will be unit variance too and Softmax will stay diffuse and not saturate too much. Illustration below
Paper (2014) ICLR 2015
NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE (Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio)
arxiv.org
https://arxiv.org/pdf/1409.0473.pdf
2015
Effective Approaches to Attention-based Neural Machine Translation
An attentional mechanism has lately been used to improve neural machine translation (NMT) by selectively focusing on parts of the source sentence during translation. However, there has been little...
https://arxiv.org/abs/1508.04025
aclanthology.org
https://aclanthology.org/D16-1244.pdf
Attention and Augmented Recurrent Neural Networks
A visual overview of neural attention, and the powerful extensions of neural networks being built on top of it.
https://distill.pub/2016/augmented-rnns/
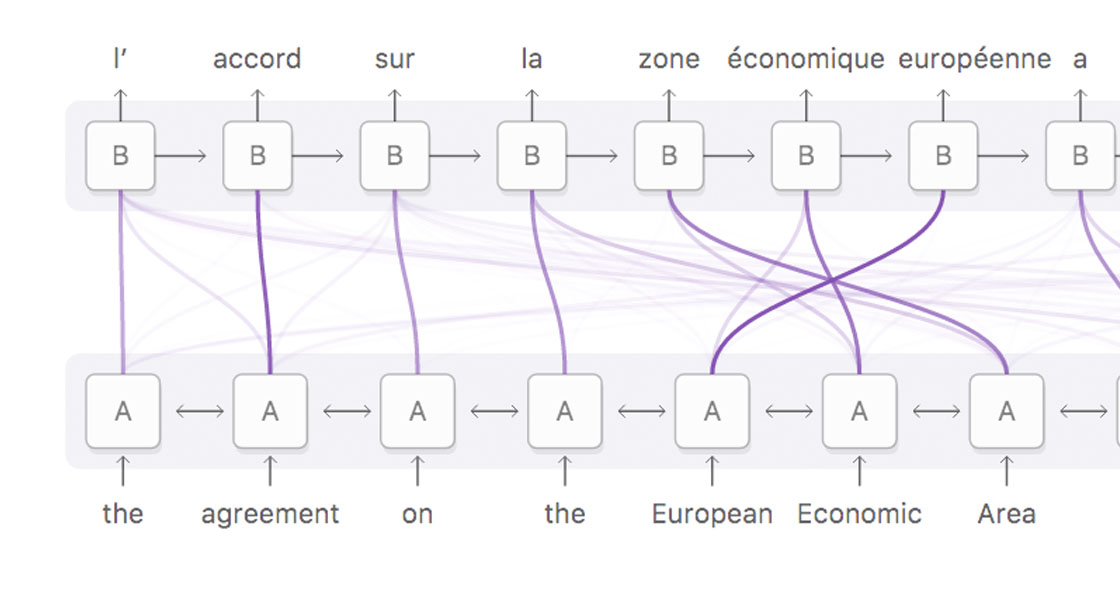
Visualization
AlphaCode
Problem descriptions from Codeforces.
https://alphacode.deepmind.com/#layer=18,problem=114,heads=11111111111
Process
[딥러닝] 언어모델, RNN, GRU, LSTM, Attention, Transformer, GPT, BERT 개념 정리
언어모델에 대한 기초적인 정리
https://velog.io/@rsj9987/딥러닝-용어정리
![[딥러닝] 언어모델, RNN, GRU, LSTM, Attention, Transformer, GPT, BERT 개념 정리](https://images.velog.io/velog.png)
15-01 어텐션 메커니즘 (Attention Mechanism)
앞서 배운 seq2seq 모델은 **인코더**에서 입력 시퀀스를 컨텍스트 벡터라는 하나의 고정된 크기의 벡터 표현으로 압축하고, **디코더**는 이 컨텍스트 벡터를 통해서 출력 …

https://wikidocs.net/22893

어텐션 메커니즘 (Attention Mechanism) : Seq2Seq 모델에서 Transformer 모델로 가기까지
Reinventing the Wheel
https://heekangpark.github.io/nlp/attention
Selective Attention Intuition
selective attention test
The original, world-famous awareness test from Daniel Simons and Christopher Chabris. Get our new book, *** Nobody's Fool: Why We Get Taken In and What We Can Do About It *** available July 11, 2023. Learn more and order from Basic Books, Amazon, or your favorite local bookstore. For more information, go to https://www.hachettebookgroup.com/titles/daniel-simons/nobodys-fool/9781541602236

https://www.youtube.com/watch?v=vJG698U2Mvo
