

 Seonglae Cho
Seonglae ChoAI Embodied Cognition
AI Spatial Reasoning Methods
Nature
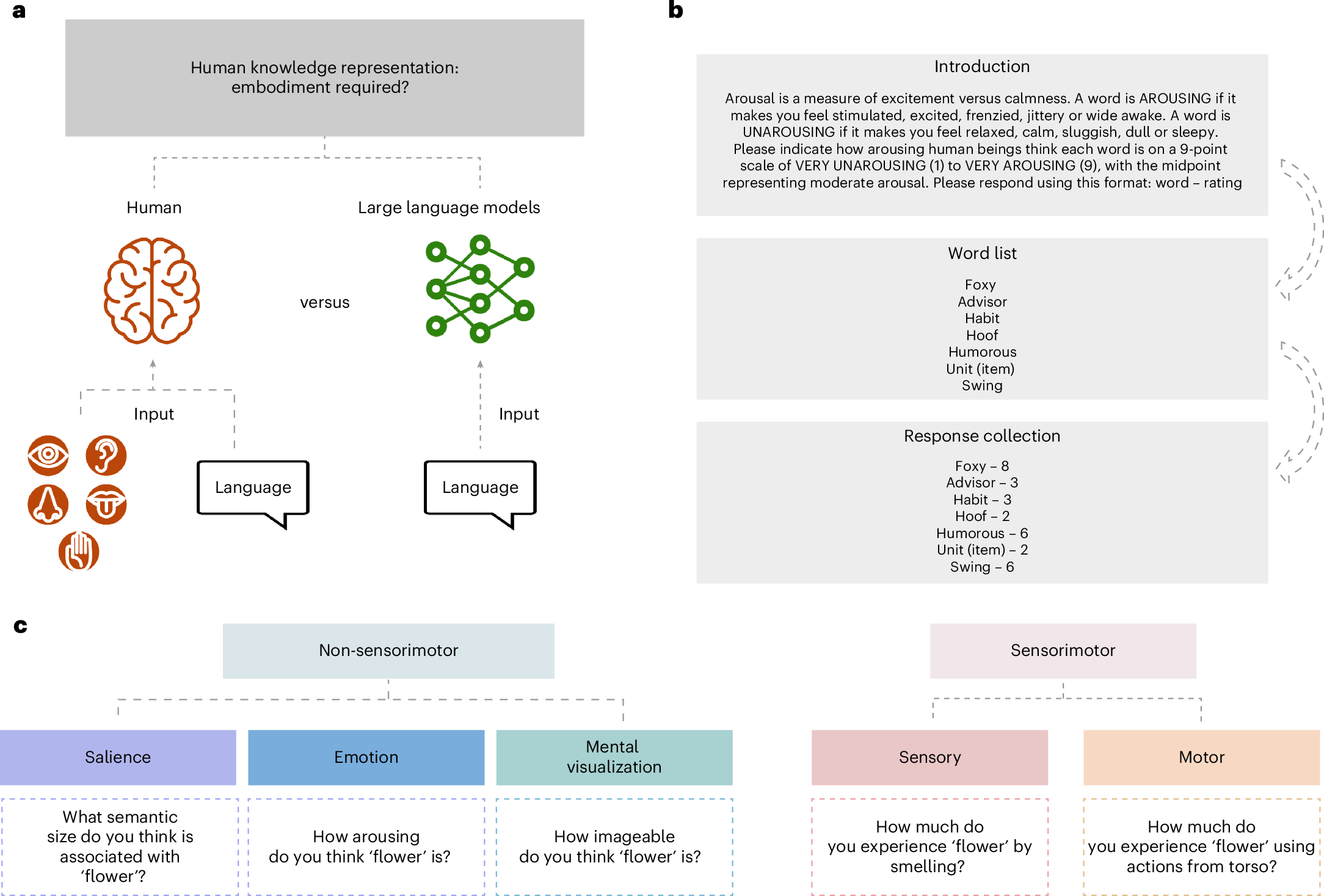
Human conceptual representation is grounded in sensorimotor experience (embodied cognition), a longstanding claim in cognitive science. Recently, arguments have emerged that LLMs learn human-like semantic representations from text alone, raising a core debate: can language alone capture all aspects of concepts? This paper systematically analyzes which dimensions of human conceptual representation LLMs successfully recover and which they fail to capture. The researchers classified feature norms collected from human participants into sensorimotor and non-sensorimotor features.
The key analysis method is Representational Similarity Analysis (RSA), which compares the similarity structure among concepts in humans versus LLMs. Specifically, they computed the Spearman correlation rho(S_human, S_LLM) between the human similarity matrix S_human and the LLM similarity matrix S_LLM, separately comparing similarity matrices constructed from sensorimotor features only versus non-sensorimotor features only.
After extracting contextualized embeddings from all models, they computed cosine similarity between concept pairs to construct RSA matrices. As an important control, they matched the number and variance of sensorimotor and non-sensorimotor features to ensure statistical comparability between feature types. Text-only LLMs showed significant correlation with non-sensorimotor feature-based similarity structure (rho approximately 0.3-0.5, p < 0.001), but correlation with sensorimotor feature-based similarity structure was significantly lower or not statistically significant. Vision-language grounded models (CLIP, etc.) showed partial improvement in sensorimotor feature recovery, but did not reach the level of non-sensorimotor feature recovery. Scaling model size did not resolve the limitations in sensorimotor feature recovery (scaling benefits only non-sensorimotor features). This may reflect limitations of text data, though the study also lacks model size diversity, and the categorization of sensory features into language categories poses additional limitations.
Large language models without grounding recover non-sensorimotor but not sensorimotor features of human concepts
Nature Human Behaviour - Xu et al. find that large language models not only align with human representations in non-sensorimotor domains but also diverge in sensorimotor ones, with additional...
https://www.nature.com/articles/s41562-025-02203-8
MLLM show less than 50% accuracy in visually recognizing or systematically counting edges of even simple regular polygons, due to the vision encoder's 'shape-blind' phenomenon that prevents it from distinguishing rare shapes. The models rely only on intuition and memorization (System 1 Thinking) without performing logical step-by-step reasoning (System 2 Thinking). However, when applying Visually-Cued CoT prompts that label each shape's edges with numbers/characters and guide step-by-step, GPT-4v's accuracy in counting edges of irregular polygons dramatically improves from 7% to 93%.
arxiv.org
https://arxiv.org/pdf/2502.15969
Spatial reasoning platform | University of Surrey
We use cookies to help our site work, to understand how it is used, and to tailor ads that are more relevant to you and your interests.
https://www.surrey.ac.uk/spatial-reasoning
VLMs excel at semantic understanding but struggle with spatial relationships. Current VLMs have a real spatial blindspot, caused by encoder design and 1D alignment methods. To fix this, spatial grounding itself must be treated as a separate design axis, not just semantic capability.
arxiv.org
https://arxiv.org/pdf/2601.09954